 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
May 19, 2025Facial Emotion Analysis (FEA) plays a crucial role in visual affective computing, aiming to infer a person's emotional state based on facial data. Scientifically, facial expressions (FEs) result from the coordinated movement of facial muscles, which can be decomposed into specific action units (AUs) that provide detailed emotional insights. However, traditional methods often struggle with limited interpretability, constrained generalization and reasoning abilities. Recently, Multimodal Large Language Models (MLLMs) have shown exceptional performance in various visual tasks, while they still face significant challenges in FEA due to the lack of specialized datasets and their inability to capture the intricate relationships between FEs and AUs. To address these issues, we introduce a novel FEA Instruction Dataset that provides accurate and aligned FE and AU descriptions and establishes causal reasoning relationships between them, followed by constructing a new benchmark, FEABench. Moreover, we propose FEALLM, a novel MLLM architecture designed to capture more detailed facial information, enhancing its capability in FEA tasks. Our model demonstrates strong performance on FEABench and impressive generalization capability through zero-shot evaluation on various datasets, including RAF-DB, AffectNet, BP4D, and DISFA, showcasing its robustness and effectiveness in FEA tasks. The dataset and code will be available at https://github.com/953206211/FEALLM.
Decoupled Doubly Contrastive Learning for Cross Domain Facial Action Unit Detection
Mar 12, 2025Despite the impressive performance of current vision-based facial action unit (AU) detection approaches, they are heavily susceptible to the variations across different domains and the cross-domain AU detection methods are under-explored. In response to this challenge, we propose a decoupled doubly contrastive adaptation (D$^2$CA) approach to learn a purified AU representation that is semantically aligned for the source and target domains. Specifically, we decompose latent representations into AU-relevant and AU-irrelevant components, with the objective of exclusively facilitating adaptation within the AU-relevant subspace. To achieve the feature decoupling, D$^2$CA is trained to disentangle AU and domain factors by assessing the quality of synthesized faces in cross-domain scenarios when either AU or domain attributes are modified. To further strengthen feature decoupling, particularly in scenarios with limited AU data diversity, D$^2$CA employs a doubly contrastive learning mechanism comprising image and feature-level contrastive learning to ensure the quality of synthesized faces and mitigate feature ambiguities. This new framework leads to an automatically learned, dedicated separation of AU-relevant and domain-relevant factors, and it enables intuitive, scale-specific control of the cross-domain facial image synthesis. Extensive experiments demonstrate the efficacy of D$^2$CA in successfully decoupling AU and domain factors, yielding visually pleasing cross-domain synthesized facial images. Meanwhile, D$^2$CA consistently outperforms state-of-the-art cross-domain AU detection approaches, achieving an average F1 score improvement of 6\%-14\% across various cross-domain scenarios.
* Accepted by IEEE Transactions on Image Processing 2025. A novel and elegant feature decoupling method for cross-domain facial action unit detection
Towards Realistic Emotional Voice Conversion using Controllable Emotional Intensity
Jul 20, 2024


Realistic emotional voice conversion (EVC) aims to enhance emotional diversity of converted audios, making the synthesized voices more authentic and natural. To this end, we propose Emotional Intensity-aware Network (EINet), dynamically adjusting intonation and rhythm by incorporating controllable emotional intensity. To better capture nuances in emotional intensity, we go beyond mere distance measurements among acoustic features. Instead, an emotion evaluator is utilized to precisely quantify speaker's emotional state. By employing an intensity mapper, intensity pseudo-labels are obtained to bridge the gap between emotional speech intensity modeling and run-time conversion. To ensure high speech quality while retaining controllability, an emotion renderer is used for combining linguistic features smoothly with manipulated emotional features at frame level. Furthermore, we employ a duration predictor to facilitate adaptive prediction of rhythm changes condition on specifying intensity value. Experimental results show EINet's superior performance in naturalness and diversity of emotional expression compared to state-of-the-art EVC methods.
Temporal Label Hierachical Network for Compound Emotion Recognition
Jul 17, 2024The emotion recognition has attracted more attention in recent decades. Although significant progress has been made in the recognition technology of the seven basic emotions, existing methods are still hard to tackle compound emotion recognition that occurred commonly in practical application. This article introduces our achievements in the 7th Field Emotion Behavior Analysis (ABAW) competition. In the competition, we selected pre trained ResNet18 and Transformer, which have been widely validated, as the basic network framework. Considering the continuity of emotions over time, we propose a time pyramid structure network for frame level emotion prediction. Furthermore. At the same time, in order to address the lack of data in composite emotion recognition, we utilized fine-grained labels from the DFEW database to construct training data for emotion categories in competitions. Taking into account the characteristics of valence arousal of various complex emotions, we constructed a classification framework from coarse to fine in the label space.
EALD-MLLM: Emotion Analysis in Long-sequential and De-identity videos with Multi-modal Large Language Model
May 01, 2024Emotion AI is the ability of computers to understand human emotional states. Existing works have achieved promising progress, but two limitations remain to be solved: 1) Previous studies have been more focused on short sequential video emotion analysis while overlooking long sequential video. However, the emotions in short sequential videos only reflect instantaneous emotions, which may be deliberately guided or hidden. In contrast, long sequential videos can reveal authentic emotions; 2) Previous studies commonly utilize various signals such as facial, speech, and even sensitive biological signals (e.g., electrocardiogram). However, due to the increasing demand for privacy, developing Emotion AI without relying on sensitive signals is becoming important. To address the aforementioned limitations, in this paper, we construct a dataset for Emotion Analysis in Long-sequential and De-identity videos called EALD by collecting and processing the sequences of athletes' post-match interviews. In addition to providing annotations of the overall emotional state of each video, we also provide the Non-Facial Body Language (NFBL) annotations for each player. NFBL is an inner-driven emotional expression and can serve as an identity-free clue to understanding the emotional state. Moreover, we provide a simple but effective baseline for further research. More precisely, we evaluate the Multimodal Large Language Models (MLLMs) with de-identification signals (e.g., visual, speech, and NFBLs) to perform emotion analysis. Our experimental results demonstrate that: 1) MLLMs can achieve comparable, even better performance than the supervised single-modal models, even in a zero-shot scenario; 2) NFBL is an important cue in long sequential emotion analysis. EALD will be available on the open-source platform.
PAVITS: Exploring Prosody-aware VITS for End-to-End Emotional Voice Conversion
Mar 03, 2024In this paper, we propose Prosody-aware VITS (PAVITS) for emotional voice conversion (EVC), aiming to achieve two major objectives of EVC: high content naturalness and high emotional naturalness, which are crucial for meeting the demands of human perception. To improve the content naturalness of converted audio, we have developed an end-to-end EVC architecture inspired by the high audio quality of VITS. By seamlessly integrating an acoustic converter and vocoder, we effectively address the common issue of mismatch between emotional prosody training and run-time conversion that is prevalent in existing EVC models. To further enhance the emotional naturalness, we introduce an emotion descriptor to model the subtle prosody variations of different speech emotions. Additionally, we propose a prosody predictor, which predicts prosody features from text based on the provided emotion label. Notably, we introduce a prosody alignment loss to establish a connection between latent prosody features from two distinct modalities, ensuring effective training. Experimental results show that the performance of PAVITS is superior to the state-of-the-art EVC methods. Speech Samples are available at https://jeremychee4.github.io/pavits4EVC/ .
Emotion-Aware Contrastive Adaptation Network for Source-Free Cross-Corpus Speech Emotion Recognition
Jan 23, 2024



Cross-corpus speech emotion recognition (SER) aims to transfer emotional knowledge from a labeled source corpus to an unlabeled corpus. However, prior methods require access to source data during adaptation, which is unattainable in real-life scenarios due to data privacy protection concerns. This paper tackles a more practical task, namely source-free cross-corpus SER, where a pre-trained source model is adapted to the target domain without access to source data. To address the problem, we propose a novel method called emotion-aware contrastive adaptation network (ECAN). The core idea is to capture local neighborhood information between samples while considering the global class-level adaptation. Specifically, we propose a nearest neighbor contrastive learning to promote local emotion consistency among features of highly similar samples. Furthermore, relying solely on nearest neighborhoods may lead to ambiguous boundaries between clusters. Thus, we incorporate supervised contrastive learning to encourage greater separation between clusters representing different emotions, thereby facilitating improved class-level adaptation. Extensive experiments indicate that our proposed ECAN significantly outperforms state-of-the-art methods under the source-free cross-corpus SER setting on several speech emotion corpora.
Speech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition
Jan 19, 2024


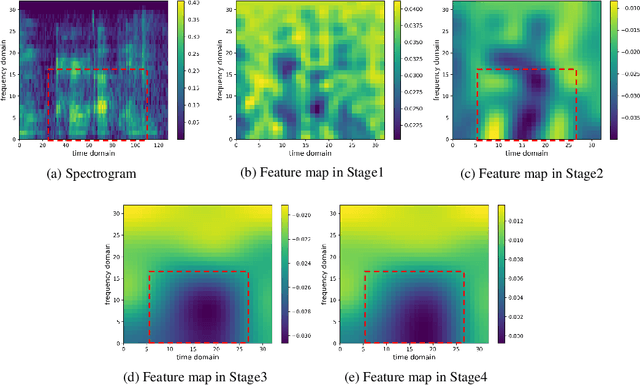
Swin-Transformer has demonstrated remarkable success in computer vision by leveraging its hierarchical feature representation based on Transformer. In speech signals, emotional information is distributed across different scales of speech features, e.\,g., word, phrase, and utterance. Drawing above inspiration, this paper presents a hierarchical speech Transformer with shifted windows to aggregate multi-scale emotion features for speech emotion recognition (SER), called Speech Swin-Transformer. Specifically, we first divide the speech spectrogram into segment-level patches in the time domain, composed of multiple frame patches. These segment-level patches are then encoded using a stack of Swin blocks, in which a local window Transformer is utilized to explore local inter-frame emotional information across frame patches of each segment patch. After that, we also design a shifted window Transformer to compensate for patch correlations near the boundaries of segment patches. Finally, we employ a patch merging operation to aggregate segment-level emotional features for hierarchical speech representation by expanding the receptive field of Transformer from frame-level to segment-level. Experimental results demonstrate that our proposed Speech Swin-Transformer outperforms the state-of-the-art methods.
Improving Speaker-independent Speech Emotion Recognition Using Dynamic Joint Distribution Adaptation
Jan 18, 2024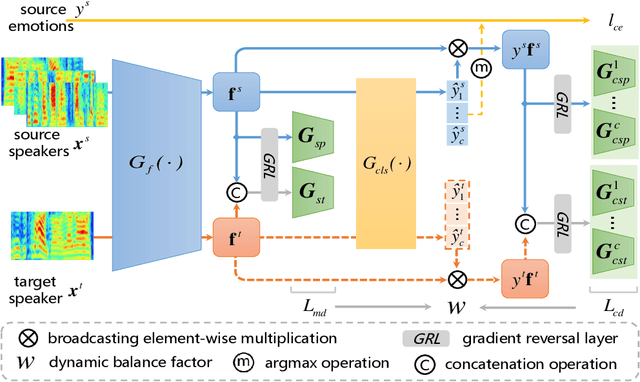


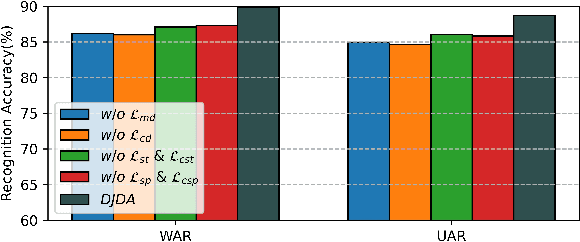
In speaker-independent speech emotion recognition, the training and testing samples are collected from diverse speakers, leading to a multi-domain shift challenge across the feature distributions of data from different speakers. Consequently, when the trained model is confronted with data from new speakers, its performance tends to degrade. To address the issue, we propose a Dynamic Joint Distribution Adaptation (DJDA) method under the framework of multi-source domain adaptation. DJDA firstly utilizes joint distribution adaptation (JDA), involving marginal distribution adaptation (MDA) and conditional distribution adaptation (CDA), to more precisely measure the multi-domain distribution shifts caused by different speakers. This helps eliminate speaker bias in emotion features, allowing for learning discriminative and speaker-invariant speech emotion features from coarse-level to fine-level. Furthermore, we quantify the adaptation contributions of MDA and CDA within JDA by using a dynamic balance factor based on $\mathcal{A}$-Distance, promoting to effectively handle the unknown distributions encountered in data from new speakers. Experimental results demonstrate the superior performance of our DJDA as compared to other state-of-the-art (SOTA) methods.