 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoVid: Temporal-Centric Self-Evolution for Video Large Language Models
May 21, 2026Recent Video Large Language Models (Video-LLMs) have demonstrated strong capabilities in video reasoning through reinforcement learning (RL). However, existing RL pipelines rely heavily on human-annotated tasks and solutions, making them costly to scale and fundamentally constrained by human expertise. Self-evolving frameworks have recently emerged as a promising alternative through autonomous Questioner-Solver self-play. Unfortunately, these approaches are primarily designed for static modalities such as text and images, fundamentally failing to capture the temporal dynamics that are central to video reasoning. In this work, we propose $\textbf{EvoVid}$, a temporal-centric self-evolving framework that enables Video-LLMs to improve directly from raw, unannotated videos. Specifically, we introduce two complementary temporal-centric rewards: a temporal-aware Questioner reward that encourages temporally dependent question generation through temporal perturbation sensitivity, and a temporal-grounded Solver reward that provides automatic temporal supervision via inherent video segment localization. Extensive experiments across four base models and six benchmarks demonstrate consistent improvements over both base models and existing self-evolving baselines, achieving competitive performance with supervised methods. These results highlight temporal-centric self-evolution as an effective and scalable paradigm for video understanding and reasoning.
WBCAtt+: Fine-Grained Pixel-Level Morphological Annotations for White Blood Cell Images
May 19, 2026The microscopic examination of white blood cells (WBCs) plays a fundamental role in pathology and is essential for diagnosing blood disorders such as leukemia and anemia. To support further research on WBC images, multiple datasets have been proposed. However, they mainly annotate cell categories, and lack detailed morphological characteristics that pathologists use to explain their interpretations of cells. To address this gap, we introduce WBCAtt+, a novel dataset of WBC images densely annotated with 11 morphological attributes and five pixel-level cell components. With 113k image-level labels and 10k segmentation maps, WBCAtt+ is the first to provide comprehensive annotations for WBC images. Leveraging this dataset, we provide baseline models for attribute recognition and semantic segmentation. We also design an attribute recognition model to incorporate compositional structure of cells, further improving the recognition performance. Lastly, we showcase various applications enabled by our dataset, such as explainable AI models, including counterfactual example generation. \revision{The dataset and code are publicly available\footnote{https://doi.org/10.57967/hf/8143}}.
Phy-CoSF: Physics-Guided Continuous Spectral Fields Reconstruction and Super-Resolution for Snapshot Compressive Imaging
May 13, 2026Recent advances have demonstrated that coded aperture snapshot spectral imaging (CASSI) systems show great potential for capturing 3D hyperspectral images (HSIs) from a single 2D measurement. Despite the inherent spectral continuity of scenes captured by CASSI, most existing reconstruction methods are restricted to fixed, discrete spectral outputs, thereby precluding continuous spectral reconstruction or spectral super-resolution. To address this challenge, we propose Phy-CoSF, which synergizes deep unfolding networks with implicit neural representations, establishing a new paradigm for continuous spectral reconstruction and super-resolution in CASSI. Specifically, we propose a two-phase architecture that bridges discrete-wavelength training with continuous spectral rendering, enabling the synthesis of high-fidelity HSIs at arbitrary target wavelengths. At the core of our framework lies the continuous spectral fields (CoSF) module, embedded within each unfolding stage as a dynamic prior, which comprises a triple-branch cross-domain feature mixer for comprehensive spatial-frequency-channel feature fusion, alongside a spectral synthesis head that generates spectral intensities by querying continuous wavelength coordinates. Extensive experimental results demonstrate that Phy-CoSF not only achieves continuous modeling at arbitrary spectral resolutions but also outperforms many state-of-the-art methods in both reconstruction fidelity and spectral detail preservation. Our code and more results are available at: https://github.com/PaiDii/Phy-CoSF.git.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
GEditBench v2: A Human-Aligned Benchmark for General Image Editing
Mar 30, 2026Recent advances in image editing have enabled models to handle complex instructions with impressive realism. However, existing evaluation frameworks lag behind: current benchmarks suffer from narrow task coverage, while standard metrics fail to adequately capture visual consistency, i.e., the preservation of identity, structure and semantic coherence between edited and original images. To address these limitations, we introduce GEditBench v2, a comprehensive benchmark with 1,200 real-world user queries spanning 23 tasks, including a dedicated open-set category for unconstrained, out-of-distribution editing instructions beyond predefined tasks. Furthermore, we propose PVC-Judge, an open-source pairwise assessment model for visual consistency, trained via two novel region-decoupled preference data synthesis pipelines. Besides, we construct VCReward-Bench using expert-annotated preference pairs to assess the alignment of PVC-Judge with human judgments on visual consistency evaluation. Experiments show that our PVC-Judge achieves state-of-the-art evaluation performance among open-source models and even surpasses GPT-5.1 on average. Finally, by benchmarking 16 frontier editing models, we show that GEditBench v2 enables more human-aligned evaluation, revealing critical limitations of current models, and providing a reliable foundation for advancing precise image editing.
RSGround-R1: Rethinking Remote Sensing Visual Grounding through Spatial Reasoning
Jan 29, 2026Remote Sensing Visual Grounding (RSVG) aims to localize target objects in large-scale aerial imagery based on natural language descriptions. Owing to the vast spatial scale and high semantic ambiguity of remote sensing scenes, these descriptions often rely heavily on positional cues, posing unique challenges for Multimodal Large Language Models (MLLMs) in spatial reasoning. To leverage this unique feature, we propose a reasoning-guided, position-aware post-training framework, dubbed \textbf{RSGround-R1}, to progressively enhance spatial understanding. Specifically, we first introduce Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) using synthetically generated RSVG reasoning data to establish explicit position awareness. Reinforcement Fine-Tuning (RFT) is then applied, augmented by our newly designed positional reward that provides continuous and distance-aware guidance toward accurate localization. Moreover, to mitigate incoherent localization behaviors across rollouts, we introduce a spatial consistency guided optimization scheme that dynamically adjusts policy updates based on their spatial coherence, ensuring stable and robust convergence. Extensive experiments on RSVG benchmarks demonstrate superior performance and generalization of our model.
Improving Flexible Image Tokenizers for Autoregressive Image Generation
Jan 04, 2026Flexible image tokenizers aim to represent an image using an ordered 1D variable-length token sequence. This flexible tokenization is typically achieved through nested dropout, where a portion of trailing tokens is randomly truncated during training, and the image is reconstructed using the remaining preceding sequence. However, this tail-truncation strategy inherently concentrates the image information in the early tokens, limiting the effectiveness of downstream AutoRegressive (AR) image generation as the token length increases. To overcome these limitations, we propose \textbf{ReToK}, a flexible tokenizer with \underline{Re}dundant \underline{Tok}en Padding and Hierarchical Semantic Regularization, designed to fully exploit all tokens for enhanced latent modeling. Specifically, we introduce \textbf{Redundant Token Padding} to activate tail tokens more frequently, thereby alleviating information over-concentration in the early tokens. In addition, we apply \textbf{Hierarchical Semantic Regularization} to align the decoding features of earlier tokens with those from a pre-trained vision foundation model, while progressively reducing the regularization strength toward the tail to allow finer low-level detail reconstruction. Extensive experiments demonstrate the effectiveness of ReTok: on ImageNet 256$\times$256, our method achieves superior generation performance compared with both flexible and fixed-length tokenizers. Code will be available at: \href{https://github.com/zfu006/ReTok}{https://github.com/zfu006/ReTok}
Learning Through Little Eyes: Attribute Discrimination Beyond Objects
Dec 22, 2025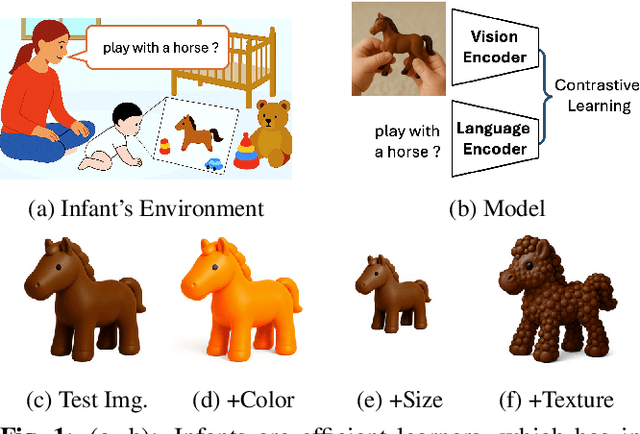

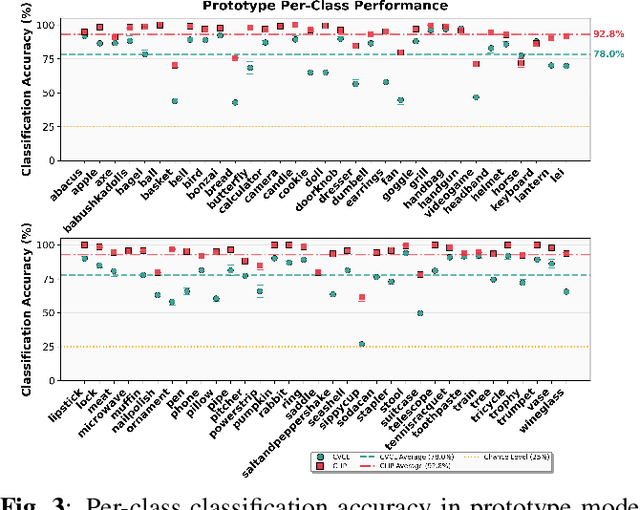
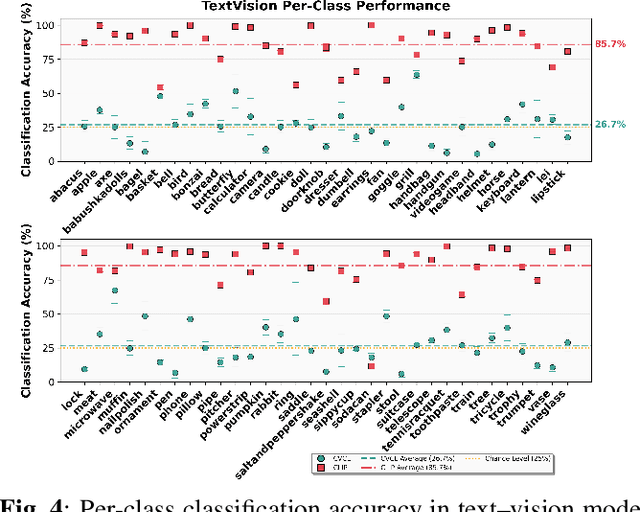
Infants learn to recognize not only object categories but also fine grained attributes such as color, size, and texture within their first two years of life. Prior work explores Childs View for Contrastive Learning (CVCL), a CLIP style model trained on infant egocentric video as a computational model of early infant learning, but it focuses only on class level recognition. This leaves it unclear whether infant scale learning also supports attribute discrimination. To address this, we introduce a benchmark that systematically varies color, size, and texture, allowing controlled tests of within class attribute recognition. Comparing CVCL with CLIP shows clear differences. CVCL is better at size discrimination, while CLIP achieves higher accuracy on color discrimination. Both models represent texture in image embeddings but fail to ground texture linguistically, suggesting a gap between visual and language spaces.
RealisticDreamer: Guidance Score Distillation for Few-shot Gaussian Splatting
Nov 14, 20253D Gaussian Splatting (3DGS) has recently gained great attention in the 3D scene representation for its high-quality real-time rendering capabilities. However, when the input comprises sparse training views, 3DGS is prone to overfitting, primarily due to the lack of intermediate-view supervision. Inspired by the recent success of Video Diffusion Models (VDM), we propose a framework called Guidance Score Distillation (GSD) to extract the rich multi-view consistency priors from pretrained VDMs. Building on the insights from Score Distillation Sampling (SDS), GSD supervises rendered images from multiple neighboring views, guiding the Gaussian splatting representation towards the generative direction of VDM. However, the generative direction often involves object motion and random camera trajectories, making it challenging for direct supervision in the optimization process. To address this problem, we introduce an unified guidance form to correct the noise prediction result of VDM. Specifically, we incorporate both a depth warp guidance based on real depth maps and a guidance based on semantic image features, ensuring that the score update direction from VDM aligns with the correct camera pose and accurate geometry. Experimental results show that our method outperforms existing approaches across multiple datasets.
Conformal Prediction for Multi-Source Detection on a Network
Nov 12, 2025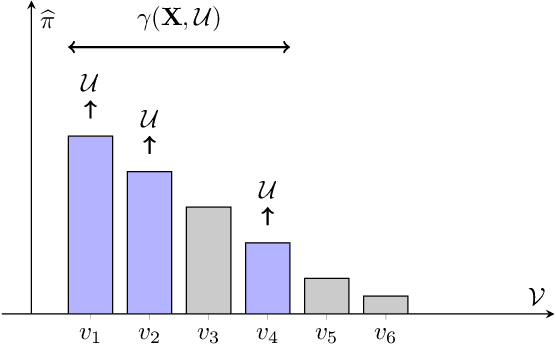
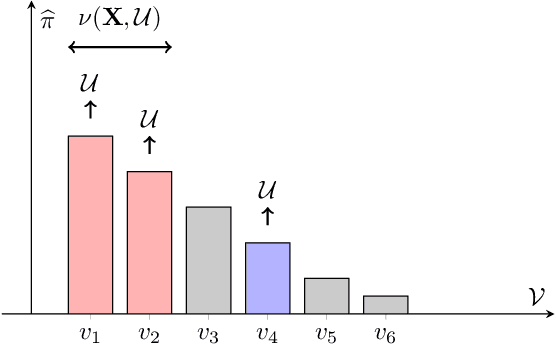
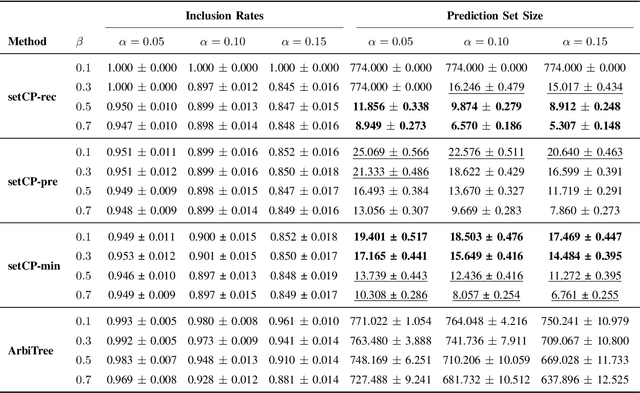
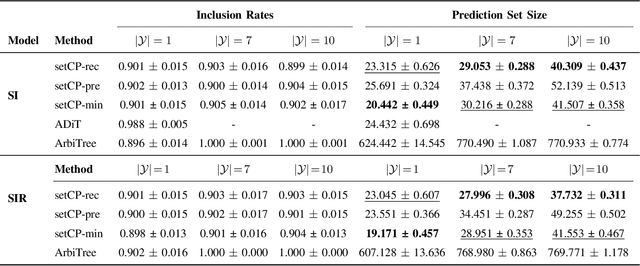
Detecting the origin of information or infection spread in networks is a fundamental challenge with applications in misinformation tracking, epidemiology, and beyond. We study the multi-source detection problem: given snapshot observations of node infection status on a graph, estimate the set of source nodes that initiated the propagation. Existing methods either lack statistical guarantees or are limited to specific diffusion models and assumptions. We propose a novel conformal prediction framework that provides statistically valid recall guarantees for source set detection, independent of the underlying diffusion process or data distribution. Our approach introduces principled score functions to quantify the alignment between predicted probabilities and true sources, and leverages a calibration set to construct prediction sets with user-specified recall and coverage levels. The method is applicable to both single- and multi-source scenarios, supports general network diffusion dynamics, and is computationally efficient for large graphs. Empirical results demonstrate that our method achieves rigorous coverage with competitive accuracy, outperforming existing baselines in both reliability and scalability.The code is available online.