 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
CoMMET: To What Extent Can LLMs Perform Theory of Mind Tasks?
Mar 12, 2026Theory of Mind (ToM)-the ability to reason about the mental states of oneself and others-is a cornerstone of human social intelligence. As Large Language Models (LLMs) become ubiquitous in real-world applications, validating their capacity for this level of social reasoning is essential for effective and natural interactions. However, existing benchmarks for assessing ToM in LLMs are limited; most rely solely on text inputs and focus narrowly on belief-related tasks. In this paper, we propose a new multimodal benchmark dataset, CoMMET, a Comprehensive Mental states and Moral Evaluation Task inspired by the Theory of Mind Booklet Task. CoMMET expands the scope of evaluation by covering a broader range of mental states and introducing multi-turn testing. To the best of our knowledge, this is the first multimodal dataset to evaluate ToM in a multi-turn conversational setting. Through a comprehensive assessment of LLMs across different families and sizes, we analyze the strengths and limitations of current models and identify directions for future improvement. Our work offers a deeper understanding of the social cognitive capabilities of modern LLMs.
MEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
Mar 09, 2026Multi-turn, multi-agent LLM game evaluations often exhibit substantial run-to-run variance. In long-horizon interactions, small early deviations compound across turns and are amplified by multi-agent coupling. This biases win rate estimates and makes rankings unreliable across repeated tournaments. Prompt choice worsens this further by producing different effective policies. We address both instability and underperformance with MEMO (Memory-augmented MOdel context optimization), a self-play framework that optimizes inference-time context by coupling retention and exploration. Retention maintains a persistent memory bank that stores structured insights from self-play trajectories and injects them as priors during later play. Exploration runs tournament-style prompt evolution with uncertainty-aware selection via TrueSkill, and uses prioritized replay to revisit rare and decisive states. Across five text-based games, MEMO raises mean win rate from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct, using $2,000$ self-play games per task. Run-to-run variance also drops, giving more stable rankings across prompt variations. These results suggest that multi-agent LLM game performance and robustness have substantial room for improvement through context optimization. MEMO achieves the largest gains in negotiation and imperfect-information games, while RL remains more effective in perfect-information settings.
Information Fidelity in Tool-Using LLM Agents: A Martingale Analysis of the Model Context Protocol
Feb 10, 2026As AI agents powered by large language models (LLMs) increasingly use external tools for high-stakes decisions, a critical reliability question arises: how do errors propagate across sequential tool calls? We introduce the first theoretical framework for analyzing error accumulation in Model Context Protocol (MCP) agents, proving that cumulative distortion exhibits linear growth and high-probability deviations bounded by $O(\sqrt{T})$. This concentration property ensures predictable system behavior and rules out exponential failure modes. We develop a hybrid distortion metric combining discrete fact matching with continuous semantic similarity, then establish martingale concentration bounds on error propagation through sequential tool interactions. Experiments across Qwen2-7B, Llama-3-8B, and Mistral-7B validate our theoretical predictions, showing empirical distortion tracks the linear trend with deviations consistently within $O(\sqrt{T})$ envelopes. Key findings include: semantic weighting reduces distortion by 80\%, and periodic re-grounding approximately every 9 steps suffices for error control. We translate these concentration guarantees into actionable deployment principles for trustworthy agent systems.
TangramSR: Can Vision-Language Models Reason in Continuous Geometric Space?
Feb 05, 2026Humans excel at spatial reasoning tasks like Tangram puzzle assembly through cognitive processes involving mental rotation, iterative refinement, and visual feedback. Inspired by how humans solve Tangram puzzles through trial-and-error, observation, and correction, we design a framework that models these human cognitive mechanisms. However, comprehensive experiments across five representative Vision-Language Models (VLMs) reveal systematic failures in continuous geometric reasoning: average IoU of only 0.41 on single-piece tasks, dropping to 0.23 on two-piece composition, far below human performance where children can complete Tangram tasks successfully. This paper addresses a fundamental challenge in self-improving AI: can models iteratively refine their predictions at test time without parameter updates? We introduce a test-time self-refinement framework that combines in-context learning (ICL) with reward-guided feedback loops, inspired by human cognitive processes. Our training-free verifier-refiner agent applies recursive refinement loops that iteratively self-refine predictions based on geometric consistency feedback, achieving IoU improvements from 0.63 to 0.932 on medium-triangle cases without any model retraining. This demonstrates that incorporating human-inspired iterative refinement mechanisms through ICL and reward loops can substantially enhance geometric reasoning in VLMs, moving self-improving AI from promise to practice in continuous spatial domains. Our work is available at this anonymous link https://anonymous.4open.science/r/TangramVLM-F582/.
10 Open Challenges Steering the Future of Vision-Language-Action Models
Nov 08, 2025Due to their ability of follow natural language instructions, vision-language-action (VLA) models are increasingly prevalent in the embodied AI arena, following the widespread success of their precursors -- LLMs and VLMs. In this paper, we discuss 10 principal milestones in the ongoing development of VLA models -- multimodality, reasoning, data, evaluation, cross-robot action generalization, efficiency, whole-body coordination, safety, agents, and coordination with humans. Furthermore, we discuss the emerging trends of using spatial understanding, modeling world dynamics, post training, and data synthesis -- all aiming to reach these milestones. Through these discussions, we hope to bring attention to the research avenues that may accelerate the development of VLA models into wider acceptability.
FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models
Oct 02, 2025Recent advances in robotic manipulation have integrated low-level robotic control into Vision-Language Models (VLMs), extending them into Vision-Language-Action (VLA) models. Although state-of-the-art VLAs achieve strong performance in downstream robotic applications, supported by large-scale crowd-sourced robot training data, they still inevitably encounter failures during execution. Enabling robots to reason about and recover from unpredictable and abrupt failures remains a critical challenge. Existing robotic manipulation datasets, collected in either simulation or the real world, primarily provide only ground-truth trajectories, leaving robots unable to recover once failures occur. Moreover, the few datasets that address failure detection typically offer only textual explanations, which are difficult to utilize directly in VLA models. To address this gap, we introduce FailSafe, a novel failure generation and recovery system that automatically produces diverse failure cases paired with executable recovery actions. FailSafe can be seamlessly applied to any manipulation task in any simulator, enabling scalable creation of failure-action data. To demonstrate its effectiveness, we fine-tune LLaVa-OneVision-7B (LLaVa-OV-7B) to build FailSafe-VLM. Experimental results show that FailSafe-VLM successfully helps robotic arm detect and recover from potential failures, improving the performance of three state-of-the-art VLA models pi0-FAST, OpenVLA, OpenVLA-OFT) by up to 22.6% on average across several tasks in Maniskill. Furthermore, FailSafe-VLM could generalize across different spatial configurations, camera viewpoints, and robotic embodiments. We plan to release the FailSafe code to the community.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
From Grunts to Grammar: Emergent Language from Cooperative Foraging
May 19, 2025Early cavemen relied on gestures, vocalizations, and simple signals to coordinate, plan, avoid predators, and share resources. Today, humans collaborate using complex languages to achieve remarkable results. What drives this evolution in communication? How does language emerge, adapt, and become vital for teamwork? Understanding the origins of language remains a challenge. A leading hypothesis in linguistics and anthropology posits that language evolved to meet the ecological and social demands of early human cooperation. Language did not arise in isolation, but through shared survival goals. Inspired by this view, we investigate the emergence of language in multi-agent Foraging Games. These environments are designed to reflect the cognitive and ecological constraints believed to have influenced the evolution of communication. Agents operate in a shared grid world with only partial knowledge about other agents and the environment, and must coordinate to complete games like picking up high-value targets or executing temporally ordered actions. Using end-to-end deep reinforcement learning, agents learn both actions and communication strategies from scratch. We find that agents develop communication protocols with hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. We quantify each property and analyze how different factors, such as population size and temporal dependencies, shape specific aspects of the emergent language. Our framework serves as a platform for studying how language can evolve from partial observability, temporal reasoning, and cooperative goals in embodied multi-agent settings. We will release all data, code, and models publicly.
TextArena
Apr 15, 2025
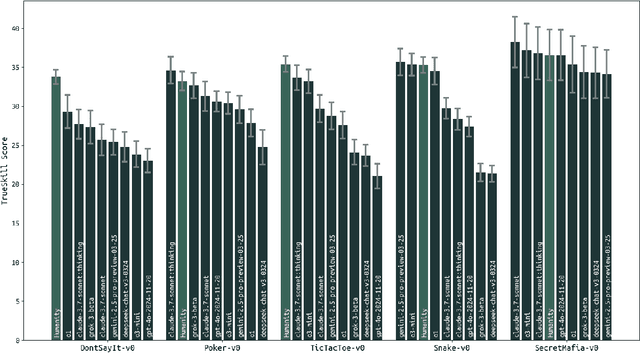
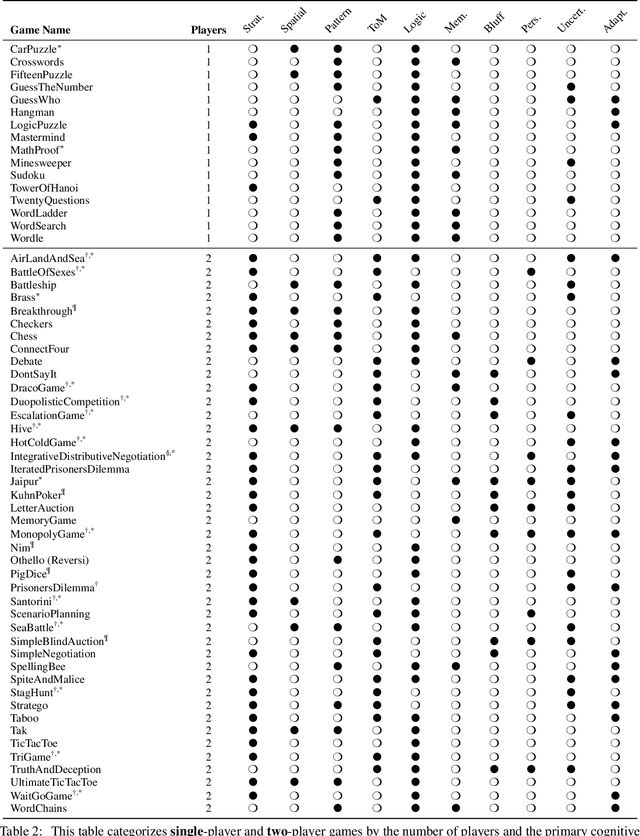

TextArena is an open-source collection of competitive text-based games for training and evaluation of agentic behavior in Large Language Models (LLMs). It spans 57+ unique environments (including single-player, two-player, and multi-player setups) and allows for easy evaluation of model capabilities via an online-play system (against humans and other submitted models) with real-time TrueSkill scores. Traditional benchmarks rarely assess dynamic social skills such as negotiation, theory of mind, and deception, creating a gap that TextArena addresses. Designed with research, community and extensibility in mind, TextArena emphasizes ease of adding new games, adapting the framework, testing models, playing against the models, and training models. Detailed documentation of environments, games, leaderboard, and examples are available on https://github.com/LeonGuertler/TextArena and https://www.textarena.ai/.