 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTLM Engineering Report: Dropout
Sep 09, 2024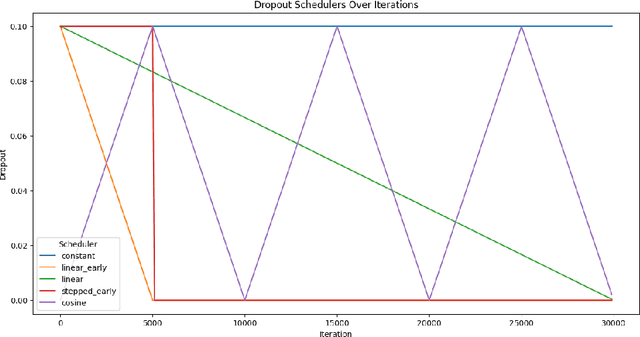
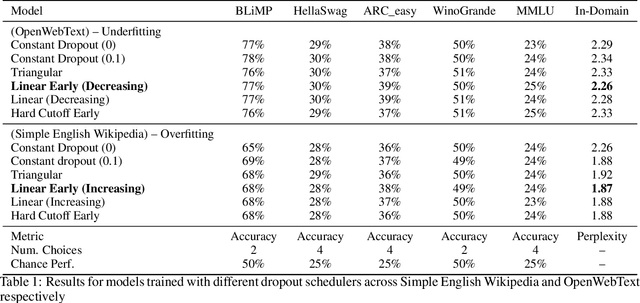
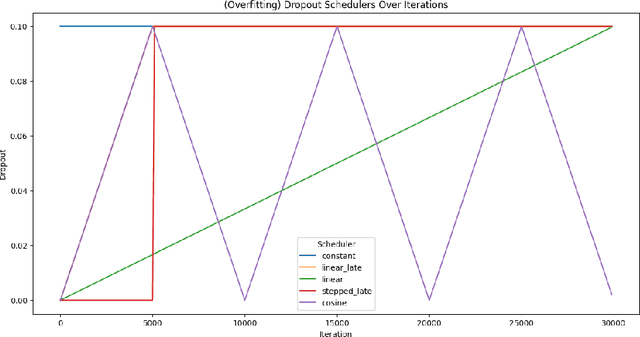
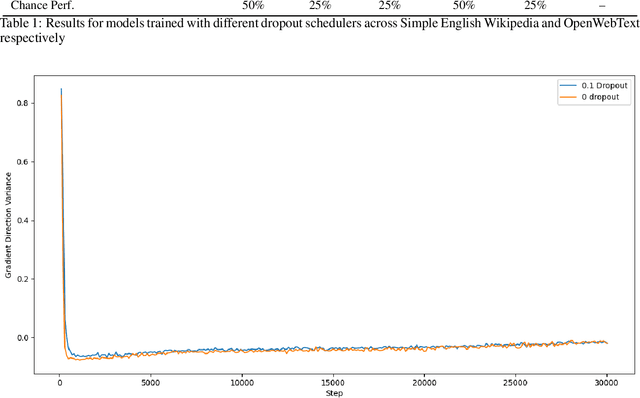
In this work we explore the relevance of dropout for modern language models, particularly in the context of models on the scale of <100M parameters. We explore it's relevance firstly in the regime of improving the sample efficiency of models given small, high quality datasets, and secondly in the regime of improving the quality of its fit on larger datasets where models may underfit. We find that concordant with conventional wisdom, dropout remains effective in the overfitting scenario, and that furthermore it may have some relevance for improving the fit of models even in the case of excess data, as suggested by previous research. In the process we find that the existing explanation for the mechanism behind this performance gain is not applicable in the case of language modelling.
Super Tiny Language Models
May 23, 2024The rapid advancement of large language models (LLMs) has led to significant improvements in natural language processing but also poses challenges due to their high computational and energy demands. This paper introduces a series of research efforts focused on Super Tiny Language Models (STLMs), which aim to deliver high performance with significantly reduced parameter counts. We explore innovative techniques such as byte-level tokenization with a pooling mechanism, weight tying, and efficient training strategies. These methods collectively reduce the parameter count by $90\%$ to $95\%$ compared to traditional models while maintaining competitive performance. This series of papers will explore into various subproblems, including tokenizer-free models, self-play based training, and alternative training objectives, targeting models with 10M, 50M, and 100M parameters. Our ultimate goal is to make high-performance language models more accessible and practical for a wide range of applications.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022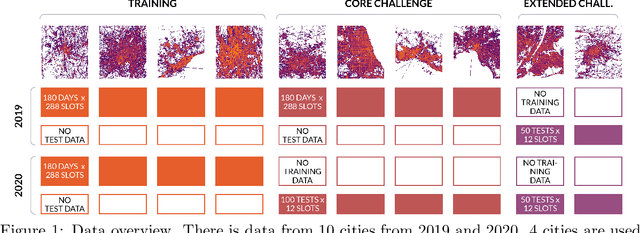
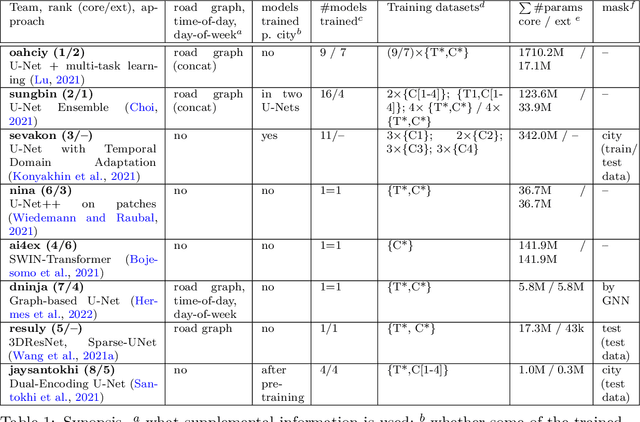
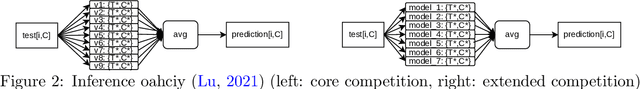
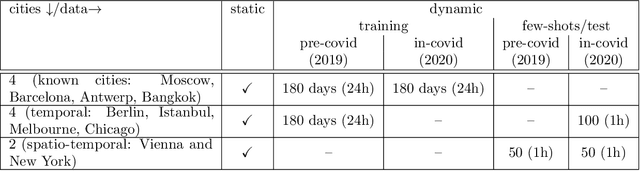
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
Dual Encoding U-Net for Spatio-Temporal Domain Shift Frame Prediction
Oct 21, 2021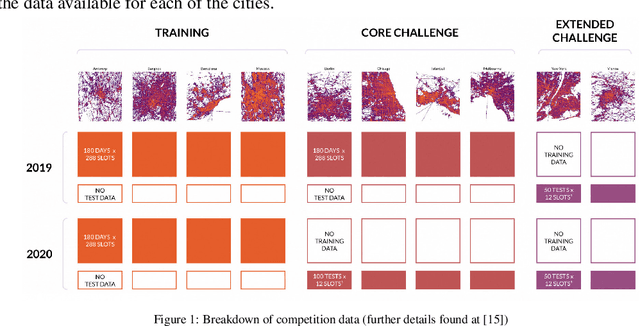

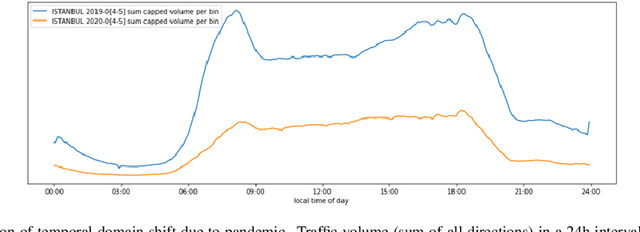
The landscape of city-wide mobility behaviour has altered significantly over the past 18 months. The ability to make accurate and reliable predictions on such behaviour has likewise changed drastically with COVID-19 measures impacting how populations across the world interact with the different facets of mobility. This raises the question: "How does one use an abundance of pre-covid mobility data to make predictions on future behaviour in a present/post-covid environment?" This paper seeks to address this question by introducing an approach for traffic frame prediction using a lightweight Dual-Encoding U-Net built using only 12 Convolutional layers that incorporates a novel approach to skip-connections between Convolutional LSTM layers. This approach combined with an intuitive handling of training data can model both a temporal and spatio-temporal domain shift (gitlab.com/alchera/alchera-traffic4cast-2021).