 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKompeteAI: Accelerated Autonomous Multi-Agent System for End-to-End Pipeline Generation for Machine Learning Problems
Aug 13, 2025



Recent Large Language Model (LLM)-based AutoML systems demonstrate impressive capabilities but face significant limitations such as constrained exploration strategies and a severe execution bottleneck. Exploration is hindered by one-shot methods lacking diversity and Monte Carlo Tree Search (MCTS) approaches that fail to recombine strong partial solutions. The execution bottleneck arises from lengthy code validation cycles that stifle iterative refinement. To overcome these challenges, we introduce KompeteAI, a novel AutoML framework with dynamic solution space exploration. Unlike previous MCTS methods that treat ideas in isolation, KompeteAI introduces a merging stage that composes top candidates. We further expand the hypothesis space by integrating Retrieval-Augmented Generation (RAG), sourcing ideas from Kaggle notebooks and arXiv papers to incorporate real-world strategies. KompeteAI also addresses the execution bottleneck via a predictive scoring model and an accelerated debugging method, assessing solution potential using early stage metrics to avoid costly full-code execution. This approach accelerates pipeline evaluation 6.9 times. KompeteAI outperforms leading methods (e.g., RD-agent, AIDE, and Ml-Master) by an average of 3\% on the primary AutoML benchmark, MLE-Bench. Additionally, we propose Kompete-bench to address limitations in MLE-Bench, where KompeteAI also achieves state-of-the-art results
Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting
Oct 17, 2022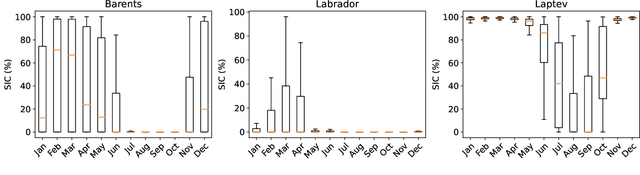
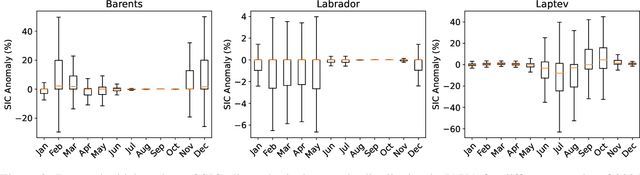

Global warming made the Arctic available for marine operations and created demand for reliable operational sea ice forecasts to make them safe. While ocean-ice numerical models are highly computationally intensive, relatively lightweight ML-based methods may be more efficient in this task. Many works have exploited different deep learning models alongside classical approaches for predicting sea ice concentration in the Arctic. However, only a few focus on daily operational forecasts and consider the real-time availability of data they need for operation. In this work, we aim to close this gap and investigate the performance of the U-Net model trained in two regimes for predicting sea ice for up to the next 10 days. We show that this deep learning model can outperform simple baselines by a significant margin and improve its quality by using additional weather data and training on multiple regions, ensuring its generalization abilities. As a practical outcome, we build a fast and flexible tool that produces operational sea ice forecasts in the Barents Sea, the Labrador Sea, and the Laptev Sea regions.
Scalable Multi-Agent Model-Based Reinforcement Learning
May 25, 2022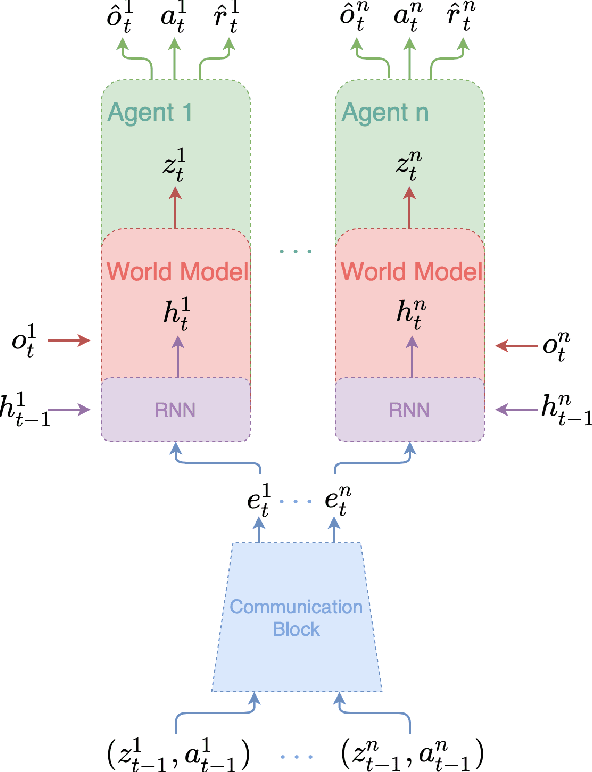
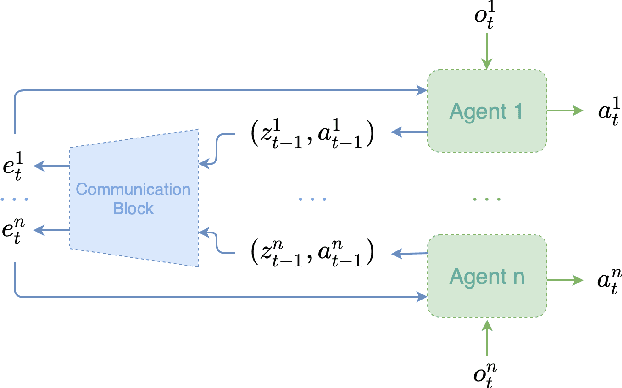
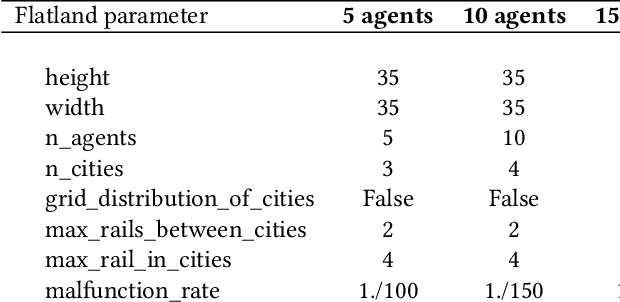
Recent Multi-Agent Reinforcement Learning (MARL) literature has been largely focused on Centralized Training with Decentralized Execution (CTDE) paradigm. CTDE has been a dominant approach for both cooperative and mixed environments due to its capability to efficiently train decentralized policies. While in mixed environments full autonomy of the agents can be a desirable outcome, cooperative environments allow agents to share information to facilitate coordination. Approaches that leverage this technique are usually referred as communication methods, as full autonomy of agents is compromised for better performance. Although communication approaches have shown impressive results, they do not fully leverage this additional information during training phase. In this paper, we propose a new method called MAMBA which utilizes Model-Based Reinforcement Learning (MBRL) to further leverage centralized training in cooperative environments. We argue that communication between agents is enough to sustain a world model for each agent during execution phase while imaginary rollouts can be used for training, removing the necessity to interact with the environment. These properties yield sample efficient algorithm that can scale gracefully with the number of agents. We empirically confirm that MAMBA achieves good performance while reducing the number of interactions with the environment up to an orders of magnitude compared to Model-Free state-of-the-art approaches in challenging domains of SMAC and Flatland.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022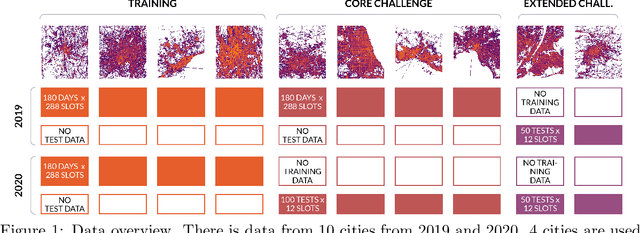
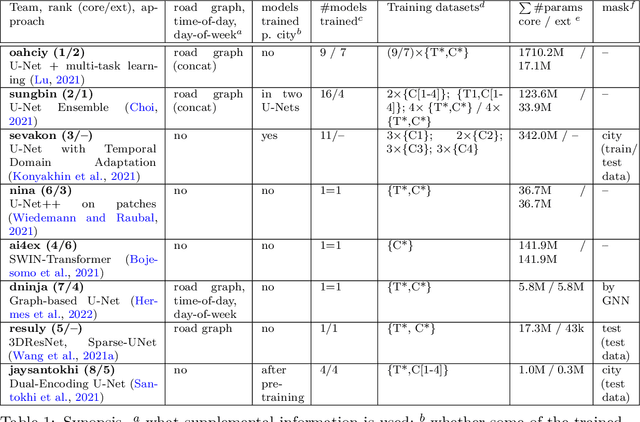
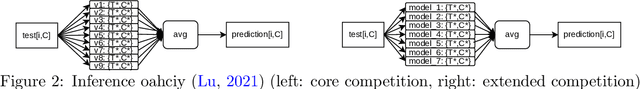
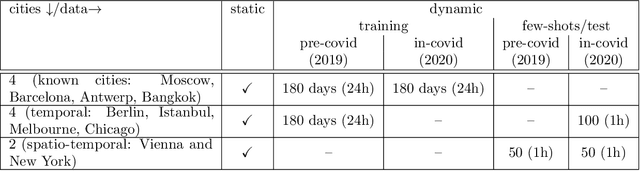
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
Self-Imitation Learning from Demonstrations
Mar 21, 2022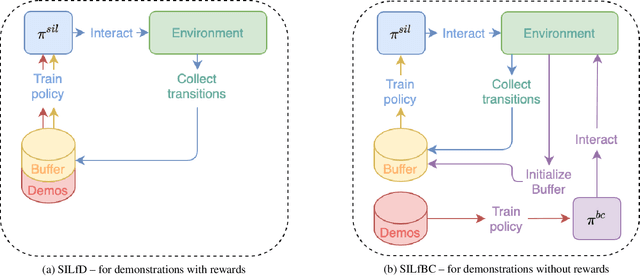
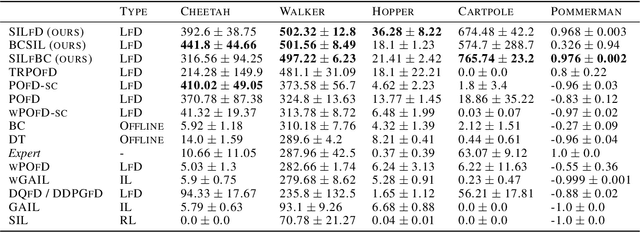
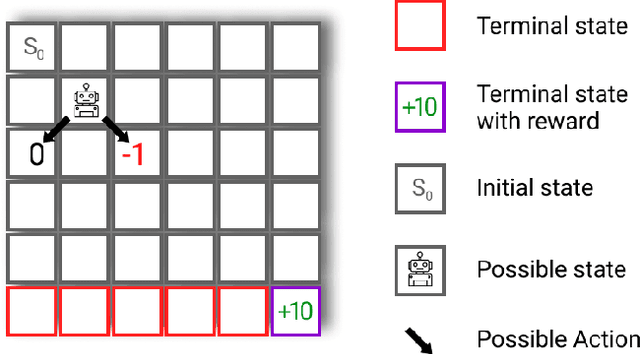
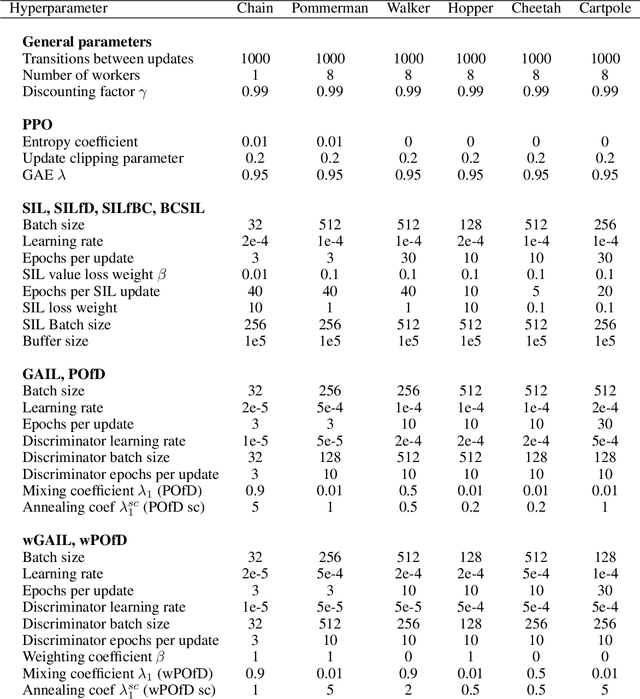
Despite the numerous breakthroughs achieved with Reinforcement Learning (RL), solving environments with sparse rewards remains a challenging task that requires sophisticated exploration. Learning from Demonstrations (LfD) remedies this issue by guiding the agent's exploration towards states experienced by an expert. Naturally, the benefits of this approach hinge on the quality of demonstrations, which are rarely optimal in realistic scenarios. Modern LfD algorithms require meticulous tuning of hyperparameters that control the influence of demonstrations and, as we show in the paper, struggle with learning from suboptimal demonstrations. To address these issues, we extend Self-Imitation Learning (SIL), a recent RL algorithm that exploits the agent's past good experience, to the LfD setup by initializing its replay buffer with demonstrations. We denote our algorithm as SIL from Demonstrations (SILfD). We empirically show that SILfD can learn from demonstrations that are noisy or far from optimal and can automatically adjust the influence of demonstrations throughout the training without additional hyperparameters or handcrafted schedules. We also find SILfD superior to the existing state-of-the-art LfD algorithms in sparse environments, especially when demonstrations are highly suboptimal.
Improving State-of-the-Art in One-Class Classification by Leveraging Unlabeled Data
Mar 14, 2022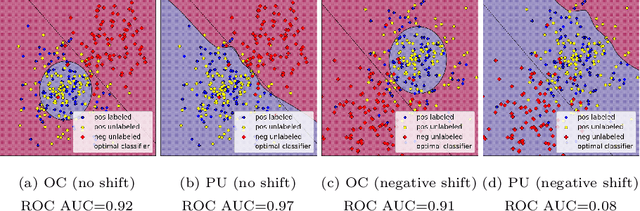
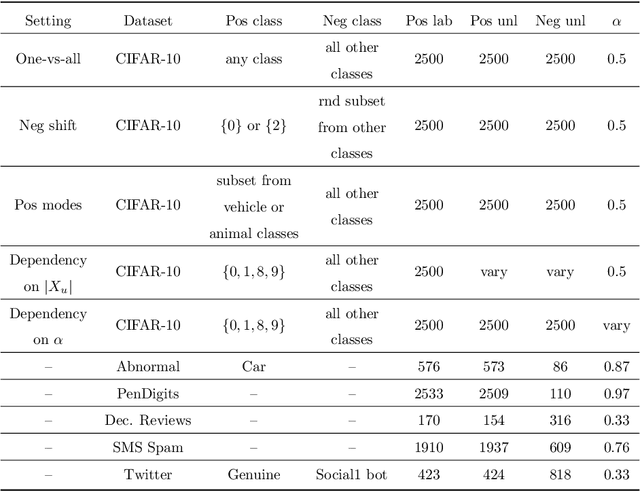
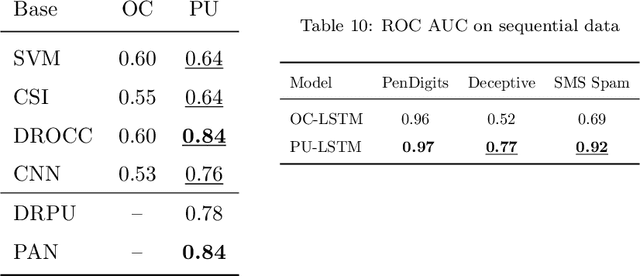
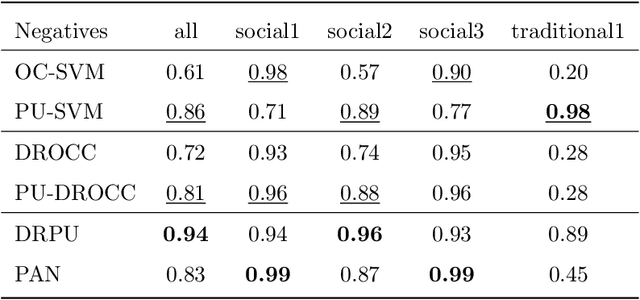
When dealing with binary classification of data with only one labeled class data scientists employ two main approaches, namely One-Class (OC) classification and Positive Unlabeled (PU) learning. The former only learns from labeled positive data, whereas the latter also utilizes unlabeled data to improve the overall performance. Since PU learning utilizes more data, we might be prone to think that when unlabeled data is available, the go-to algorithms should always come from the PU group. However, we find that this is not always the case if unlabeled data is unreliable, i.e. contains limited or biased latent negative data. We perform an extensive experimental study of a wide list of state-of-the-art OC and PU algorithms in various scenarios as far as unlabeled data reliability is concerned. Furthermore, we propose PU modifications of state-of-the-art OC algorithms that are robust to unreliable unlabeled data, as well as a guideline to similarly modify other OC algorithms. Our main practical recommendation is to use state-of-the-art PU algorithms when unlabeled data is reliable and to use the proposed modifications of state-of-the-art OC algorithms otherwise. Additionally, we outline procedures to distinguish the cases of reliable and unreliable unlabeled data using statistical tests.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022
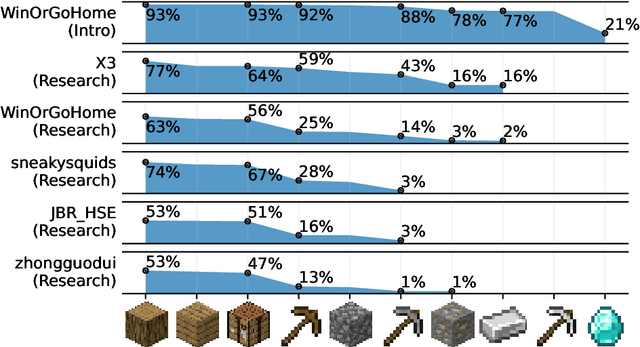
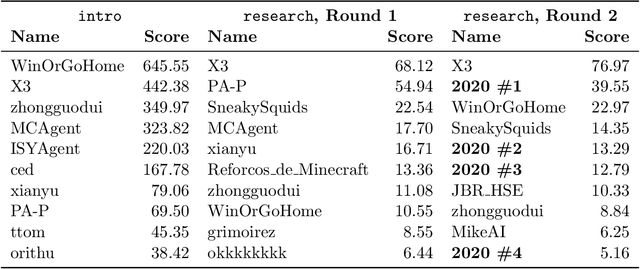
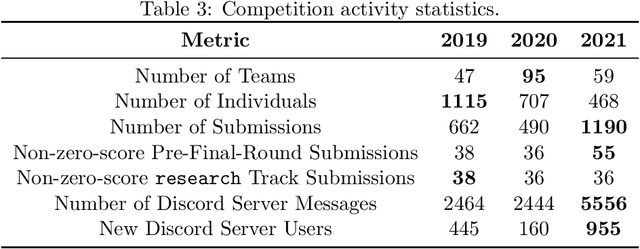
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Maximum Entropy Model-based Reinforcement Learning
Dec 02, 2021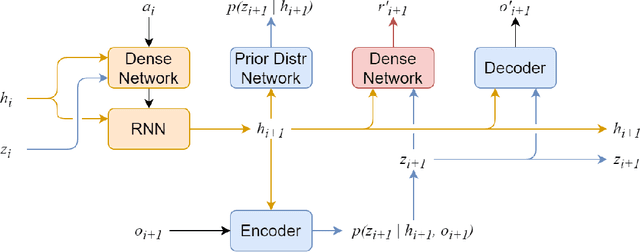
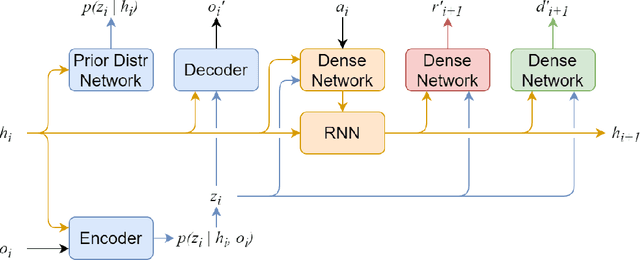
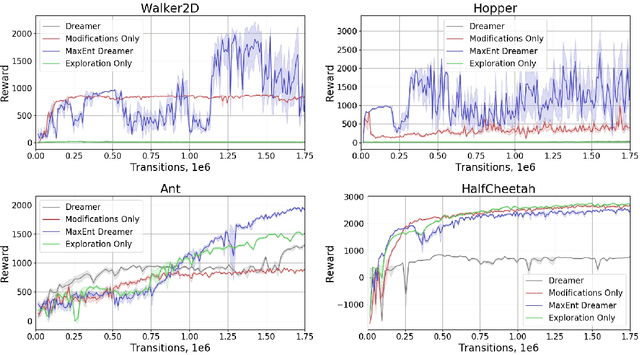
Recent advances in reinforcement learning have demonstrated its ability to solve hard agent-environment interaction tasks on a super-human level. However, the application of reinforcement learning methods to practical and real-world tasks is currently limited due to most RL state-of-art algorithms' sample inefficiency, i.e., the need for a vast number of training episodes. For example, OpenAI Five algorithm that has beaten human players in Dota 2 has trained for thousands of years of game time. Several approaches exist that tackle the issue of sample inefficiency, that either offers a more efficient usage of already gathered experience or aim to gain a more relevant and diverse experience via a better exploration of an environment. However, to our knowledge, no such approach exists for model-based algorithms, that showed their high sample efficiency in solving hard control tasks with high-dimensional state space. This work connects exploration techniques and model-based reinforcement learning. We have designed a novel exploration method that takes into account features of the model-based approach. We also demonstrate through experiments that our method significantly improves the performance of the model-based algorithm Dreamer.
Simple End-to-end Deep Learning Model for CDR-H3 Loop Structure Prediction
Nov 20, 2021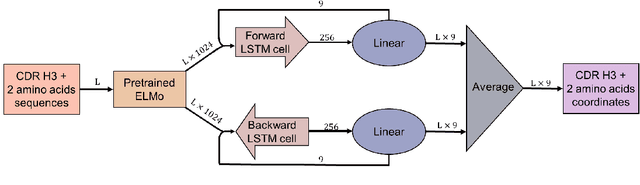
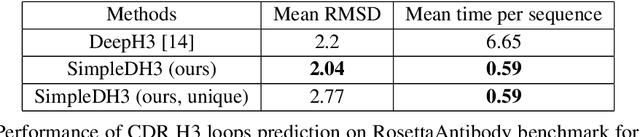
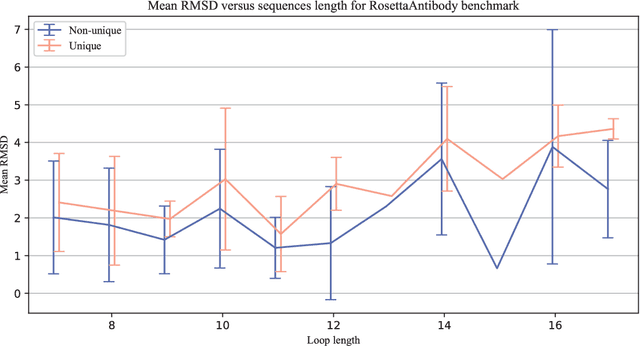
Predicting a structure of an antibody from its sequence is important since it allows for a better design process of synthetic antibodies that play a vital role in the health industry. Most of the structure of an antibody is conservative. The most variable and hard-to-predict part is the {\it third complementarity-determining region of the antibody heavy chain} (CDR H3). Lately, deep learning has been employed to solve the task of CDR H3 prediction. However, current state-of-the-art methods are not end-to-end, but rather they output inter-residue distances and orientations to the RosettaAntibody package that uses this additional information alongside statistical and physics-based methods to predict the 3D structure. This does not allow a fast screening process and, therefore, inhibits the development of targeted synthetic antibodies. In this work, we present an end-to-end model to predict CDR H3 loop structure, that performs on par with state-of-the-art methods in terms of accuracy but an order of magnitude faster. We also raise an issue with a commonly used RosettaAntibody benchmark that leads to data leaks, i.e., the presence of identical sequences in the train and test datasets.
Solving Traffic4Cast Competition with U-Net and Temporal Domain Adaptation
Nov 05, 2021
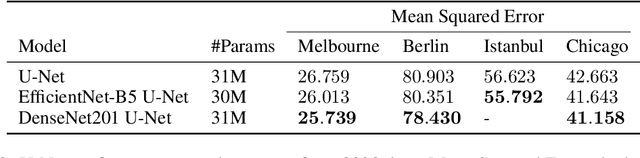


In this technical report, we present our solution to the Traffic4Cast 2021 Core Challenge, in which participants were asked to develop algorithms for predicting a traffic state 60 minutes ahead, based on the information from the previous hour, in 4 different cities. In contrast to the previously held competitions, this year's challenge focuses on the temporal domain shift in traffic due to the COVID-19 pandemic. Following the past success of U-Net, we utilize it for predicting future traffic maps. Additionally, we explore the usage of pre-trained encoders such as DenseNet and EfficientNet and employ multiple domain adaptation techniques to fight the domain shift. Our solution has ranked third in the final competition. The code is available at https://github.com/jbr-ai-labs/traffic4cast-2021.