 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKompeteAI: Accelerated Autonomous Multi-Agent System for End-to-End Pipeline Generation for Machine Learning Problems
Aug 13, 2025



Recent Large Language Model (LLM)-based AutoML systems demonstrate impressive capabilities but face significant limitations such as constrained exploration strategies and a severe execution bottleneck. Exploration is hindered by one-shot methods lacking diversity and Monte Carlo Tree Search (MCTS) approaches that fail to recombine strong partial solutions. The execution bottleneck arises from lengthy code validation cycles that stifle iterative refinement. To overcome these challenges, we introduce KompeteAI, a novel AutoML framework with dynamic solution space exploration. Unlike previous MCTS methods that treat ideas in isolation, KompeteAI introduces a merging stage that composes top candidates. We further expand the hypothesis space by integrating Retrieval-Augmented Generation (RAG), sourcing ideas from Kaggle notebooks and arXiv papers to incorporate real-world strategies. KompeteAI also addresses the execution bottleneck via a predictive scoring model and an accelerated debugging method, assessing solution potential using early stage metrics to avoid costly full-code execution. This approach accelerates pipeline evaluation 6.9 times. KompeteAI outperforms leading methods (e.g., RD-agent, AIDE, and Ml-Master) by an average of 3\% on the primary AutoML benchmark, MLE-Bench. Additionally, we propose Kompete-bench to address limitations in MLE-Bench, where KompeteAI also achieves state-of-the-art results
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022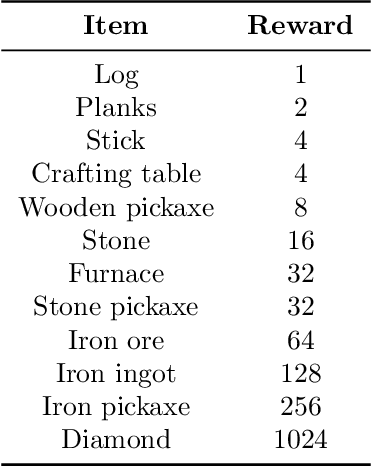
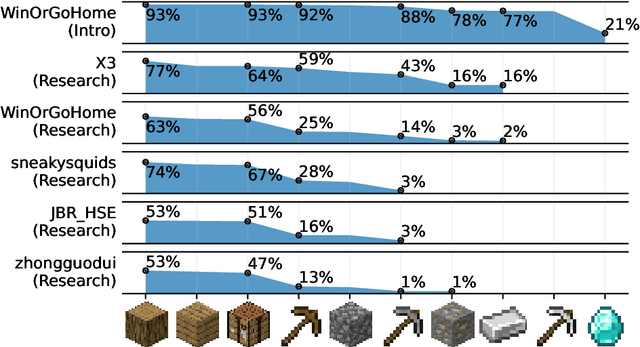
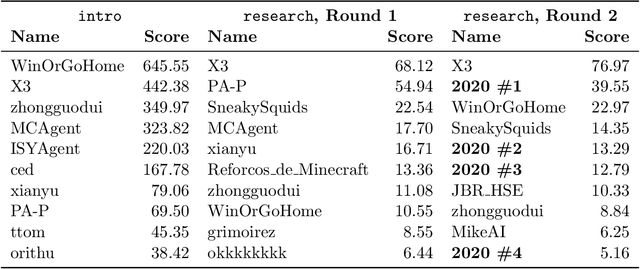
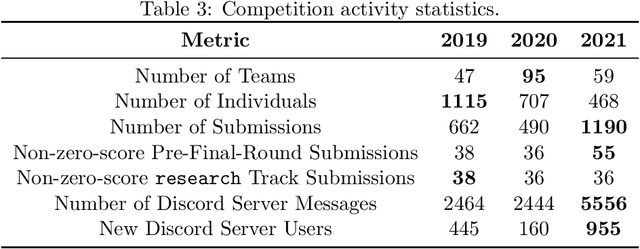
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Maximum Entropy Model-based Reinforcement Learning
Dec 02, 2021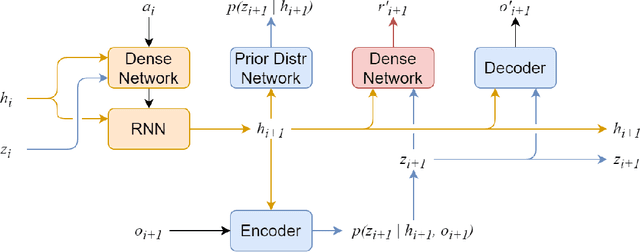
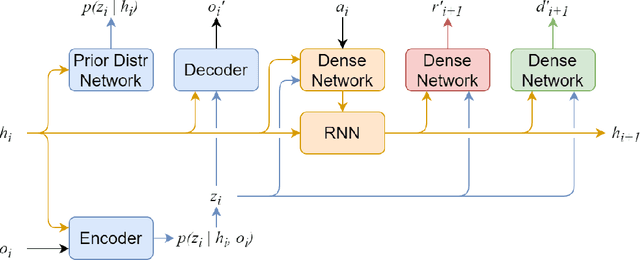
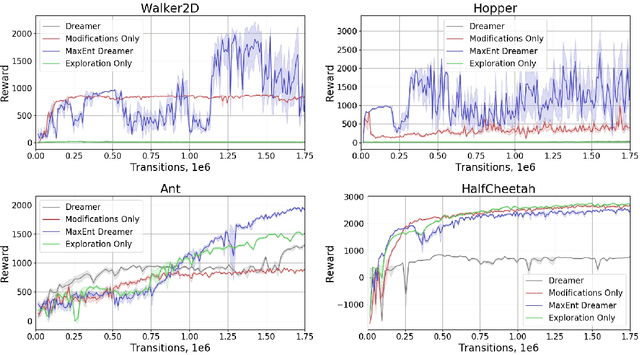
Recent advances in reinforcement learning have demonstrated its ability to solve hard agent-environment interaction tasks on a super-human level. However, the application of reinforcement learning methods to practical and real-world tasks is currently limited due to most RL state-of-art algorithms' sample inefficiency, i.e., the need for a vast number of training episodes. For example, OpenAI Five algorithm that has beaten human players in Dota 2 has trained for thousands of years of game time. Several approaches exist that tackle the issue of sample inefficiency, that either offers a more efficient usage of already gathered experience or aim to gain a more relevant and diverse experience via a better exploration of an environment. However, to our knowledge, no such approach exists for model-based algorithms, that showed their high sample efficiency in solving hard control tasks with high-dimensional state space. This work connects exploration techniques and model-based reinforcement learning. We have designed a novel exploration method that takes into account features of the model-based approach. We also demonstrate through experiments that our method significantly improves the performance of the model-based algorithm Dreamer.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021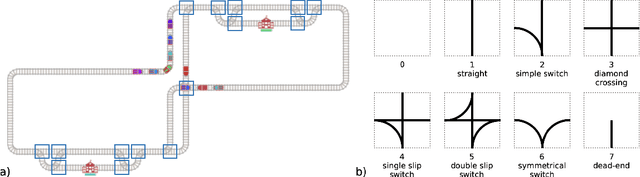
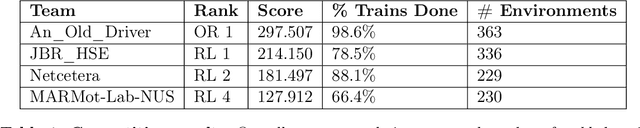
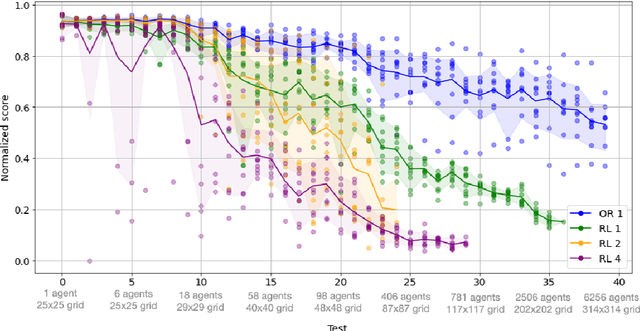
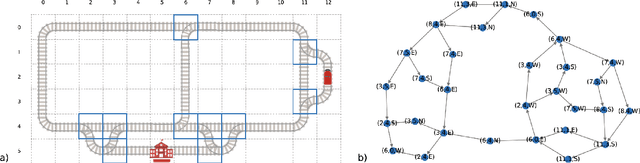
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
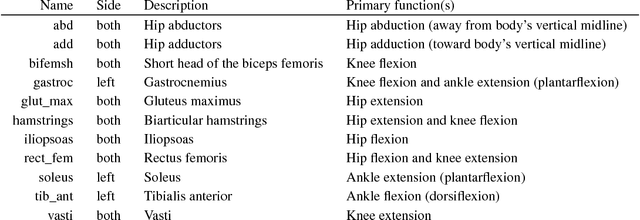
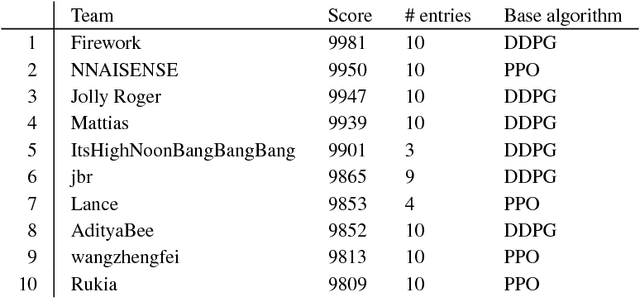

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.