 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
Mar 25, 2026Autonomous mobile GUI agents have attracted increasing attention along with the advancement of Multimodal Large Language Models (MLLMs). However, existing methods still suffer from inefficient learning from failed trajectories and ambiguous credit assignment under sparse rewards for long-horizon GUI tasks. To that end, we propose UI-Voyager, a novel two-stage self-evolving mobile GUI agent. In the first stage, we employ Rejection Fine-Tuning (RFT), which enables the continuous co-evolution of data and models in a fully autonomous loop. The second stage introduces Group Relative Self-Distillation (GRSD), which identifies critical fork points in group rollouts and constructs dense step-level supervision from successful trajectories to correct failed ones. Extensive experiments on AndroidWorld show that our 4B model achieves an 81.0% Pass@1 success rate, outperforming numerous recent baselines and exceeding human-level performance. Ablation and case studies further verify the effectiveness of GRSD. Our method represents a significant leap toward efficient, self-evolving, and high-performance mobile GUI automation without expensive manual data annotation.
ProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
Yan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
Playable Game Generation
Dec 01, 2024



In recent years, Artificial Intelligence Generated Content (AIGC) has advanced from text-to-image generation to text-to-video and multimodal video synthesis. However, generating playable games presents significant challenges due to the stringent requirements for real-time interaction, high visual quality, and accurate simulation of game mechanics. Existing approaches often fall short, either lacking real-time capabilities or failing to accurately simulate interactive mechanics. To tackle the playability issue, we propose a novel method called \emph{PlayGen}, which encompasses game data generation, an autoregressive DiT-based diffusion model, and a comprehensive playability-based evaluation framework. Validated on well-known 2D and 3D games, PlayGen achieves real-time interaction, ensures sufficient visual quality, and provides accurate interactive mechanics simulation. Notably, these results are sustained even after over 1000 frames of gameplay on an NVIDIA RTX 2060 GPU. Our code is publicly available: https://github.com/GreatX3/Playable-Game-Generation. Our playable demo generated by AI is: http://124.156.151.207.
Nuance Matters: Probing Epistemic Consistency in Causal Reasoning
Aug 27, 2024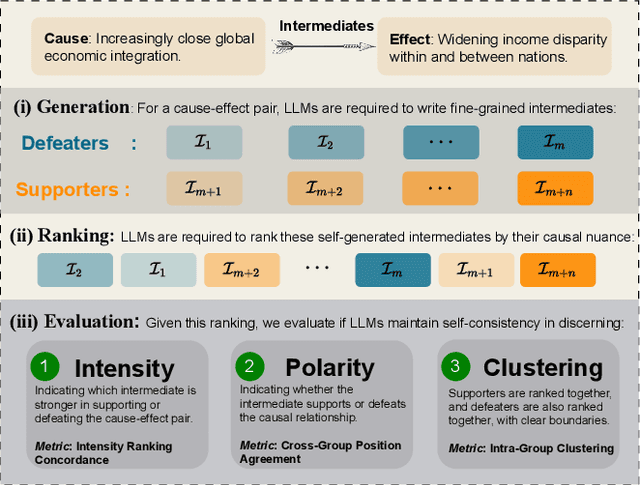
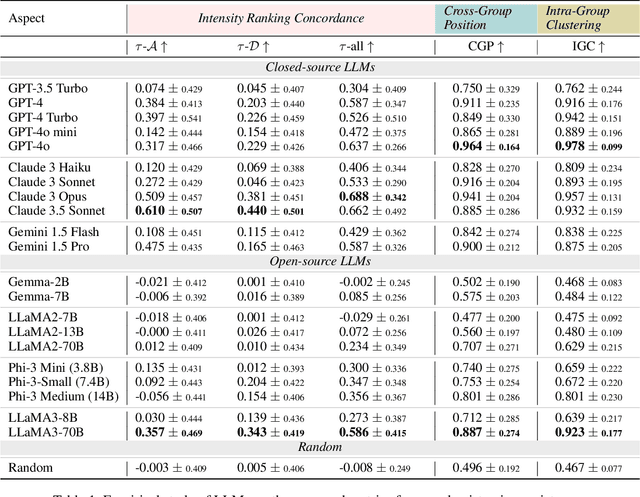
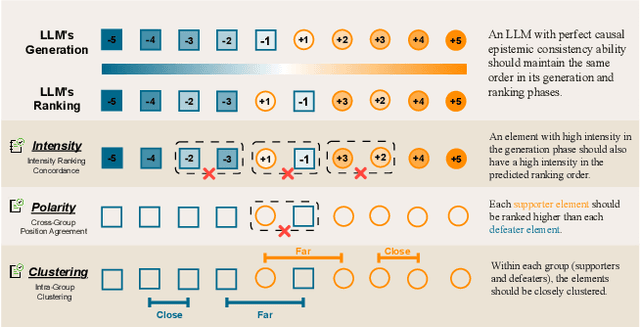
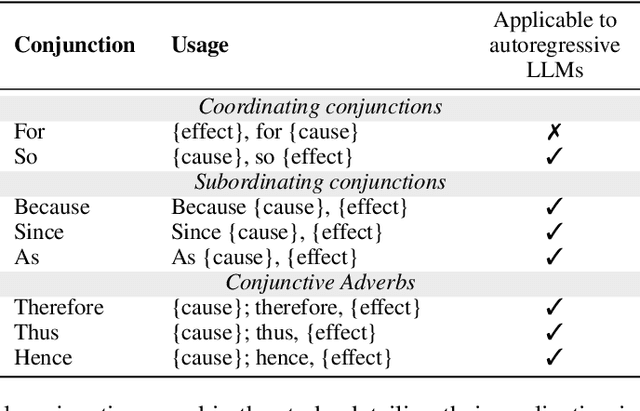
To address this gap, our study introduces the concept of causal epistemic consistency, which focuses on the self-consistency of Large Language Models (LLMs) in differentiating intermediates with nuanced differences in causal reasoning. We propose a suite of novel metrics -- intensity ranking concordance, cross-group position agreement, and intra-group clustering -- to evaluate LLMs on this front. Through extensive empirical studies on 21 high-profile LLMs, including GPT-4, Claude3, and LLaMA3-70B, we have favoring evidence that current models struggle to maintain epistemic consistency in identifying the polarity and intensity of intermediates in causal reasoning. Additionally, we explore the potential of using internal token probabilities as an auxiliary tool to maintain causal epistemic consistency. In summary, our study bridges a critical gap in AI research by investigating the self-consistency over fine-grained intermediates involved in causal reasoning.
Improving Sample Efficiency of Reinforcement Learning with Background Knowledge from Large Language Models
Jul 04, 2024



Low sample efficiency is an enduring challenge of reinforcement learning (RL). With the advent of versatile large language models (LLMs), recent works impart common-sense knowledge to accelerate policy learning for RL processes. However, we note that such guidance is often tailored for one specific task but loses generalizability. In this paper, we introduce a framework that harnesses LLMs to extract background knowledge of an environment, which contains general understandings of the entire environment, making various downstream RL tasks benefit from one-time knowledge representation. We ground LLMs by feeding a few pre-collected experiences and requesting them to delineate background knowledge of the environment. Afterward, we represent the output knowledge as potential functions for potential-based reward shaping, which has a good property for maintaining policy optimality from task rewards. We instantiate three variants to prompt LLMs for background knowledge, including writing code, annotating preferences, and assigning goals. Our experiments show that these methods achieve significant sample efficiency improvements in a spectrum of downstream tasks from Minigrid and Crafter domains.
An Autonomous Large Language Model Agent for Chemical Literature Data Mining
Feb 20, 2024



Chemical synthesis, which is crucial for advancing material synthesis and drug discovery, impacts various sectors including environmental science and healthcare. The rise of technology in chemistry has generated extensive chemical data, challenging researchers to discern patterns and refine synthesis processes. Artificial intelligence (AI) helps by analyzing data to optimize synthesis and increase yields. However, AI faces challenges in processing literature data due to the unstructured format and diverse writing style of chemical literature. To overcome these difficulties, we introduce an end-to-end AI agent framework capable of high-fidelity extraction from extensive chemical literature. This AI agent employs large language models (LLMs) for prompt generation and iterative optimization. It functions as a chemistry assistant, automating data collection and analysis, thereby saving manpower and enhancing performance. Our framework's efficacy is evaluated using accuracy, recall, and F1 score of reaction condition data, and we compared our method with human experts in terms of content correctness and time efficiency. The proposed approach marks a significant advancement in automating chemical literature extraction and demonstrates the potential for AI to revolutionize data management and utilization in chemistry.
Affordable Generative Agents
Feb 03, 2024



The emergence of large language models (LLMs) has significantly advanced the simulation of believable interactive agents. However, the substantial cost on maintaining the prolonged agent interactions poses challenge over the deployment of believable LLM-based agents. Therefore, in this paper, we develop Affordable Generative Agents (AGA), a framework for enabling the generation of believable and low-cost interactions on both agent-environment and inter-agents levels. Specifically, for agent-environment interactions, we substitute repetitive LLM inferences with learned policies; while for inter-agent interactions, we model the social relationships between agents and compress auxiliary dialogue information. Extensive experiments on multiple environments show the effectiveness and efficiency of our proposed framework. Also, we delve into the mechanisms of emergent believable behaviors lying in LLM agents, demonstrating that agents can only generate finite behaviors in fixed environments, based upon which, we understand ways to facilitate emergent interaction behaviors. Our code is publicly available at: \url{https://github.com/AffordableGenerativeAgents/Affordable-Generative-Agents}.
More Agents Is All You Need
Feb 03, 2024We find that, simply via a sampling-and-voting method, the performance of large language models (LLMs) scales with the number of agents instantiated. Also, this method is orthogonal to existing complicated methods to further enhance LLMs, while the degree of enhancement is correlated to the task difficulty. We conduct comprehensive experiments on a wide range of LLM benchmarks to verify the presence of our finding, and to study the properties that can facilitate its occurrence. Our code is publicly available at: \url{https://anonymous.4open.science/r/more_agent_is_all_you_need}.
Towards an Automatic AI Agent for Reaction Condition Recommendation in Chemical Synthesis
Nov 28, 2023



Artificial intelligence (AI) for reaction condition optimization has become an important topic in the pharmaceutical industry, given that a data-driven AI model can assist drug discovery and accelerate reaction design. However, existing AI models lack the chemical insights and real-time knowledge acquisition abilities of experienced human chemists. This paper proposes a Large Language Model (LLM) empowered AI agent to bridge this gap. We put forth a novel three-phase paradigm and applied advanced intelligence-enhancement methods like in-context learning and multi-LLM debate so that the AI agent can borrow human insight and update its knowledge by searching the latest chemical literature. Additionally, we introduce a novel Coarse-label Contrastive Learning (CCL) based chemical fingerprint that greatly enhances the agent's performance in optimizing the reaction condition. With the above efforts, the proposed AI agent can autonomously generate the optimal reaction condition recommendation without any human interaction. Further, the agent is highly professional in terms of chemical reactions. It demonstrates close-to-human performance and strong generalization capability in both dry-lab and wet-lab experiments. As the first attempt in the chemical AI agent, this work goes a step further in the field of "AI for chemistry" and opens up new possibilities for computer-aided synthesis planning.