 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Lead Optimization: Leveraging Generative AI for Structural Modification
Apr 30, 2024The idea of using deep-learning-based molecular generation to accelerate discovery of drug candidates has attracted extraordinary attention, and many deep generative models have been developed for automated drug design, termed molecular generation. In general, molecular generation encompasses two main strategies: de novo design, which generates novel molecular structures from scratch, and lead optimization, which refines existing molecules into drug candidates. Among them, lead optimization plays an important role in real-world drug design. For example, it can enable the development of me-better drugs that are chemically distinct yet more effective than the original drugs. It can also facilitate fragment-based drug design, transforming virtual-screened small ligands with low affinity into first-in-class medicines. Despite its importance, automated lead optimization remains underexplored compared to the well-established de novo generative models, due to its reliance on complex biological and chemical knowledge. To bridge this gap, we conduct a systematic review of traditional computational methods for lead optimization, organizing these strategies into four principal sub-tasks with defined inputs and outputs. This review delves into the basic concepts, goals, conventional CADD techniques, and recent advancements in AIDD. Additionally, we introduce a unified perspective based on constrained subgraph generation to harmonize the methodologies of de novo design and lead optimization. Through this lens, de novo design can incorporate strategies from lead optimization to address the challenge of generating hard-to-synthesize molecules; inversely, lead optimization can benefit from the innovations in de novo design by approaching it as a task of generating molecules conditioned on certain substructures.
MetaRF: Differentiable Random Forest for Reaction Yield Prediction with a Few Trails
Aug 22, 2022

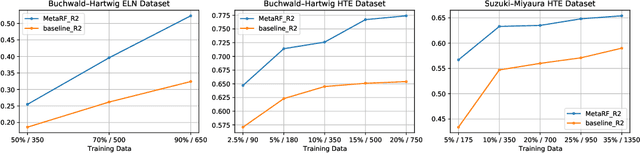
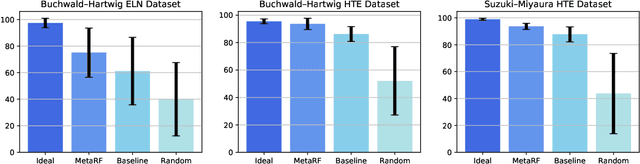
Artificial intelligence has deeply revolutionized the field of medicinal chemistry with many impressive applications, but the success of these applications requires a massive amount of training samples with high-quality annotations, which seriously limits the wide usage of data-driven methods. In this paper, we focus on the reaction yield prediction problem, which assists chemists in selecting high-yield reactions in a new chemical space only with a few experimental trials. To attack this challenge, we first put forth MetaRF, an attention-based differentiable random forest model specially designed for the few-shot yield prediction, where the attention weight of a random forest is automatically optimized by the meta-learning framework and can be quickly adapted to predict the performance of new reagents while given a few additional samples. To improve the few-shot learning performance, we further introduce a dimension-reduction based sampling method to determine valuable samples to be experimentally tested and then learned. Our methodology is evaluated on three different datasets and acquires satisfactory performance on few-shot prediction. In high-throughput experimentation (HTE) datasets, the average yield of our methodology's top 10 high-yield reactions is relatively close to the results of ideal yield selection.