 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACER: Texture-Robust Affordance Chain-of-Thought for Deformable-Object Refinement
Jan 28, 2026The central challenge in robotic manipulation of deformable objects lies in aligning high-level semantic instructions with physical interaction points under complex appearance and texture variations. Due to near-infinite degrees of freedom, complex dynamics, and heterogeneous patterns, existing vision-based affordance prediction methods often suffer from boundary overflow and fragmented functional regions. To address these issues, we propose TRACER, a Texture-Robust Affordance Chain-of-thought with dEformable-object Refinement framework, which establishes a cross-hierarchical mapping from hierarchical semantic reasoning to appearance-robust and physically consistent functional region refinement. Specifically, a Tree-structured Affordance Chain-of-Thought (TA-CoT) is formulated to decompose high-level task intentions into hierarchical sub-task semantics, providing consistent guidance across various execution stages. To ensure spatial integrity, a Spatial-Constrained Boundary Refinement (SCBR) mechanism is introduced to suppress prediction spillover, guiding the perceptual response to converge toward authentic interaction manifolds. Furthermore, an Interactive Convergence Refinement Flow (ICRF) is developed to aggregate discrete pixels corrupted by appearance noise, significantly enhancing the spatial continuity and physical plausibility of the identified functional regions. Extensive experiments conducted on the Fine-AGDDO15 dataset and a real-world robotic platform demonstrate that TRACER significantly improves affordance grounding precision across diverse textures and patterns inherent to deformable objects. More importantly, it enhances the success rate of long-horizon tasks, effectively bridging the gap between high-level semantic reasoning and low-level physical execution. The source code and dataset will be made publicly available at https://github.com/Dikay1/TRACER.
CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning
Jan 05, 2026Large Language Models (LLMs) are increasingly deployed as long-term interactive agents, yet their limited context windows make it difficult to sustain coherent behavior over extended interactions. Existing memory systems often store isolated records and retrieve fragments, limiting their ability to consolidate evolving user states and resolve conflicts. We introduce EverMemOS, a self-organizing memory operating system that implements an engram-inspired lifecycle for computational memory. Episodic Trace Formation converts dialogue streams into MemCells that capture episodic traces, atomic facts, and time-bounded Foresight signals. Semantic Consolidation organizes MemCells into thematic MemScenes, distilling stable semantic structures and updating user profiles. Reconstructive Recollection performs MemScene-guided agentic retrieval to compose the necessary and sufficient context for downstream reasoning. Experiments on LoCoMo and LongMemEval show that EverMemOS achieves state-of-the-art performance on memory-augmented reasoning tasks. We further report a profile study on PersonaMem v2 and qualitative case studies illustrating chat-oriented capabilities such as user profiling and Foresight. Code is available at https://github.com/EverMind-AI/EverMemOS.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
Latent-Space Autoregressive World Model for Efficient and Robust Image-Goal Navigation
Nov 14, 2025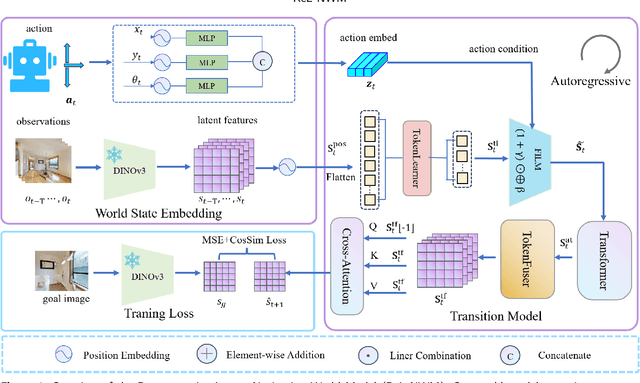
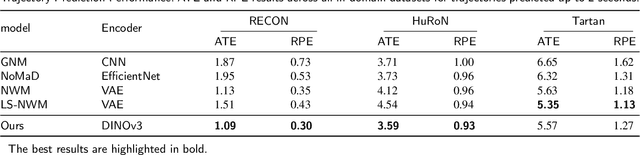

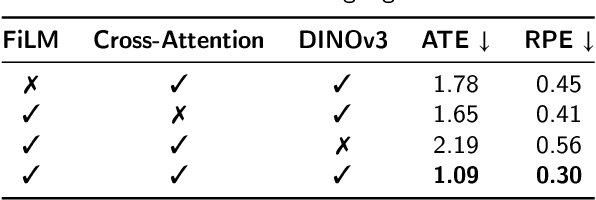
Traditional navigation methods rely heavily on accurate localization and mapping. In contrast, world models that capture environmental dynamics in latent space have opened up new perspectives for navigation tasks, enabling systems to move beyond traditional multi-module pipelines. However, world model often suffers from high computational costs in both training and inference. To address this, we propose LS-NWM - a lightweight latent space navigation world model that is trained and operates entirely in latent space, compared to the state-of-the-art baseline, our method reduces training time by approximately 3.2x and planning time by about 447x,while further improving navigation performance with a 35% higher SR and an 11% higher SPL. The key idea is that accurate pixel-wise environmental prediction is unnecessary for navigation. Instead, the model predicts future latent states based on current observational features and action inputs, then performs path planning and decision-making within this compact representation, significantly improving computational efficiency. By incorporating an autoregressive multi-frame prediction strategy during training, the model effectively captures long-term spatiotemporal dependencies, thereby enhancing navigation performance in complex scenarios. Experimental results demonstrate that our method achieves state-of-the-art navigation performance while maintaining a substantial efficiency advantage over existing approaches.
Remember Me: Bridging the Long-Range Gap in LVLMs with Three-Step Inference-Only Decay Resilience Strategies
Nov 13, 2025Large Vision-Language Models (LVLMs) have achieved impressive performance across a wide range of multimodal tasks. However, they still face critical challenges in modeling long-range dependencies under the usage of Rotary Positional Encoding (ROPE). Although it can facilitate precise modeling of token positions, it induces progressive attention decay as token distance increases, especially with progressive attention decay over distant token pairs, which severely impairs the model's ability to remember global context. To alleviate this issue, we propose inference-only Three-step Decay Resilience Strategies (T-DRS), comprising (1) Semantic-Driven DRS (SD-DRS), amplifying semantically meaningful but distant signals via content-aware residuals, (2) Distance-aware Control DRS (DC-DRS), which can purify attention by smoothly modulating weights based on positional distances, suppressing noise while preserving locality, and (3) re-Reinforce Distant DRS (reRD-DRS), consolidating the remaining informative remote dependencies to maintain global coherence. Together, the T-DRS recover suppressed long-range token pairs without harming local inductive biases. Extensive experiments on Vision Question Answering (VQA) benchmarks demonstrate that T-DRS can consistently improve performance in a training-free manner. The code can be accessed in https://github.com/labixiaoq-qq/Remember-me
Anomagic: Crossmodal Prompt-driven Zero-shot Anomaly Generation
Nov 13, 2025We propose Anomagic, a zero-shot anomaly generation method that produces semantically coherent anomalies without requiring any exemplar anomalies. By unifying both visual and textual cues through a crossmodal prompt encoding scheme, Anomagic leverages rich contextual information to steer an inpainting-based generation pipeline. A subsequent contrastive refinement strategy enforces precise alignment between synthesized anomalies and their masks, thereby bolstering downstream anomaly detection accuracy. To facilitate training, we introduce AnomVerse, a collection of 12,987 anomaly-mask-caption triplets assembled from 13 publicly available datasets, where captions are automatically generated by multimodal large language models using structured visual prompts and template-based textual hints. Extensive experiments demonstrate that Anomagic trained on AnomVerse can synthesize more realistic and varied anomalies than prior methods, yielding superior improvements in downstream anomaly detection. Furthermore, Anomagic can generate anomalies for any normal-category image using user-defined prompts, establishing a versatile foundation model for anomaly generation.
FedSDWC: Federated Synergistic Dual-Representation Weak Causal Learning for OOD
Nov 12, 2025
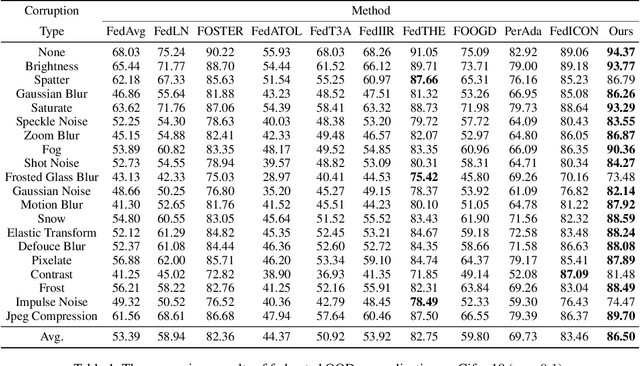
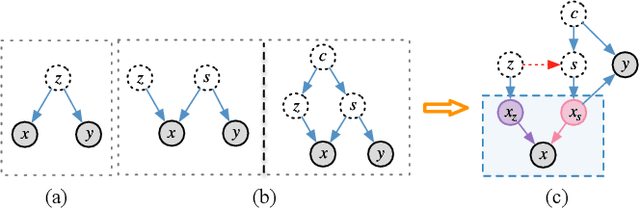
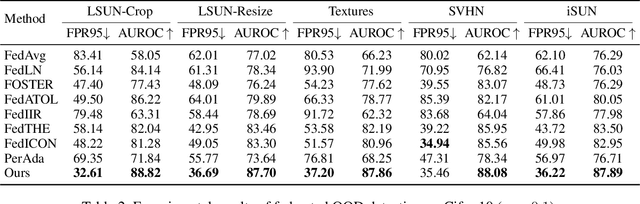
Amid growing demands for data privacy and advances in computational infrastructure, federated learning (FL) has emerged as a prominent distributed learning paradigm. Nevertheless, differences in data distribution (such as covariate and semantic shifts) severely affect its reliability in real-world deployments. To address this issue, we propose FedSDWC, a causal inference method that integrates both invariant and variant features. FedSDWC infers causal semantic representations by modeling the weak causal influence between invariant and variant features, effectively overcoming the limitations of existing invariant learning methods in accurately capturing invariant features and directly constructing causal representations. This approach significantly enhances FL's ability to generalize and detect OOD data. Theoretically, we derive FedSDWC's generalization error bound under specific conditions and, for the first time, establish its relationship with client prior distributions. Moreover, extensive experiments conducted on multiple benchmark datasets validate the superior performance of FedSDWC in handling covariate and semantic shifts. For example, FedSDWC outperforms FedICON, the next best baseline, by an average of 3.04% on CIFAR-10 and 8.11% on CIFAR-100.
CrossAD: Time Series Anomaly Detection with Cross-scale Associations and Cross-window Modeling
Oct 14, 2025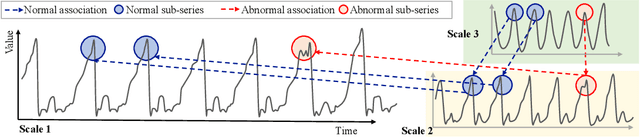
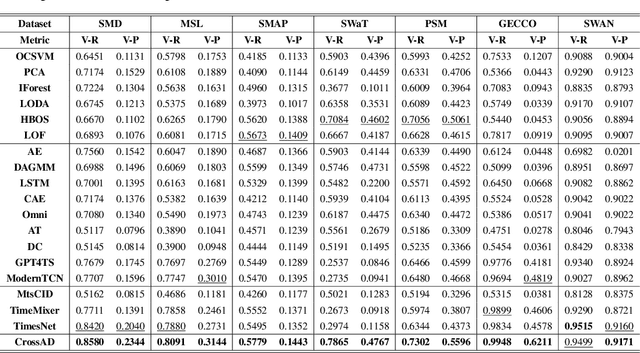
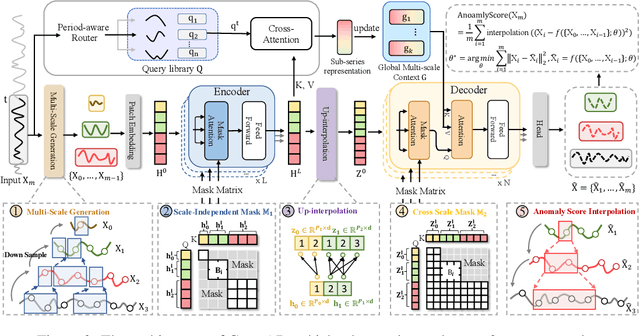
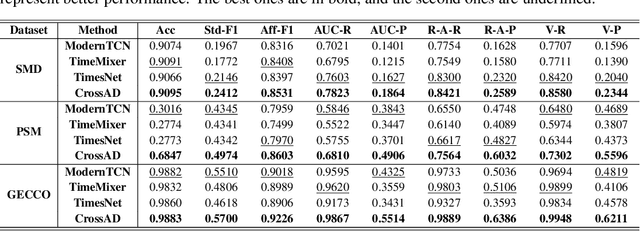
Time series anomaly detection plays a crucial role in a wide range of real-world applications. Given that time series data can exhibit different patterns at different sampling granularities, multi-scale modeling has proven beneficial for uncovering latent anomaly patterns that may not be apparent at a single scale. However, existing methods often model multi-scale information independently or rely on simple feature fusion strategies, neglecting the dynamic changes in cross-scale associations that occur during anomalies. Moreover, most approaches perform multi-scale modeling based on fixed sliding windows, which limits their ability to capture comprehensive contextual information. In this work, we propose CrossAD, a novel framework for time series Anomaly Detection that takes Cross-scale associations and Cross-window modeling into account. We propose a cross-scale reconstruction that reconstructs fine-grained series from coarser series, explicitly capturing cross-scale associations. Furthermore, we design a query library and incorporate global multi-scale context to overcome the limitations imposed by fixed window sizes. Extensive experiments conducted on multiple real-world datasets using nine evaluation metrics validate the effectiveness of CrossAD, demonstrating state-of-the-art performance in anomaly detection.