 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustDexGrasp: Robust Dexterous Grasping of General Objects from Single-view Perception
Apr 07, 2025
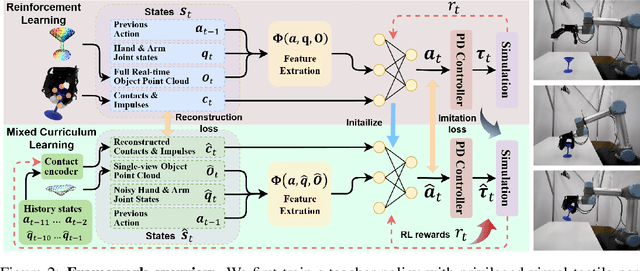
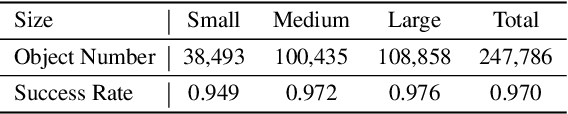
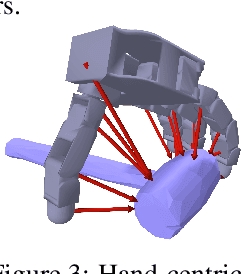
Robust grasping of various objects from single-view perception is fundamental for dexterous robots. Previous works often rely on fully observable objects, expert demonstrations, or static grasping poses, which restrict their generalization ability and adaptability to external disturbances. In this paper, we present a reinforcement-learning-based framework that enables zero-shot dynamic dexterous grasping of a wide range of unseen objects from single-view perception, while performing adaptive motions to external disturbances. We utilize a hand-centric object representation for shape feature extraction that emphasizes interaction-relevant local shapes, enhancing robustness to shape variance and uncertainty. To enable effective hand adaptation to disturbances with limited observations, we propose a mixed curriculum learning strategy, which first utilizes imitation learning to distill a policy trained with privileged real-time visual-tactile feedback, and gradually transfers to reinforcement learning to learn adaptive motions under disturbances caused by observation noises and dynamic randomization. Our experiments demonstrate strong generalization in grasping unseen objects with random poses, achieving success rates of 97.0% across 247,786 simulated objects and 94.6% across 512 real objects. We also demonstrate the robustness of our method to various disturbances, including unobserved object movement and external forces, through both quantitative and qualitative evaluations. Project Page: https://zdchan.github.io/Robust_DexGrasp/
FunGrasp: Functional Grasping for Diverse Dexterous Hands
Nov 24, 2024



Functional grasping is essential for humans to perform specific tasks, such as grasping scissors by the finger holes to cut materials or by the blade to safely hand them over. Enabling dexterous robot hands with functional grasping capabilities is crucial for their deployment to accomplish diverse real-world tasks. Recent research in dexterous grasping, however, often focuses on power grasps while overlooking task- and object-specific functional grasping poses. In this paper, we introduce FunGrasp, a system that enables functional dexterous grasping across various robot hands and performs one-shot transfer to unseen objects. Given a single RGBD image of functional human grasping, our system estimates the hand pose and transfers it to different robotic hands via a human-to-robot (H2R) grasp retargeting module. Guided by the retargeted grasping poses, a policy is trained through reinforcement learning in simulation for dynamic grasping control. To achieve robust sim-to-real transfer, we employ several techniques including privileged learning, system identification, domain randomization, and gravity compensation. In our experiments, we demonstrate that our system enables diverse functional grasping of unseen objects using single RGBD images, and can be successfully deployed across various dexterous robot hands. The significance of the components is validated through comprehensive ablation studies. Project page: https://hly-123.github.io/FunGrasp/ .
DGSNA: prompt-based Dynamic Generative Scene-based Noise Addition method
Nov 19, 2024



This paper addresses the challenges of accurately enumerating and describing scenes and the labor-intensive process required to replicate acoustic environments using non-generative methods. We introduce the prompt-based Dynamic Generative Sce-ne-based Noise Addition method (DGSNA), which innovatively combines the Dynamic Generation of Scene Information (DGSI) with Scene-based Noise Addition for Audio (SNAA). Employing generative chat models structured within the Back-ground-Examples-Task (BET) prompt framework, DGSI com-ponent facilitates the dynamic synthesis of tailored Scene Infor-mation (SI) for specific acoustic environments. Additionally, the SNAA component leverages Room Impulse Response (RIR) fil-ters and Text-To-Audio (TTA) systems to generate realistic, scene-based noise that can be adapted for both indoor and out-door environments. Through comprehensive experiments, the adaptability of DGSNA across different generative chat models was demonstrated. The results, assessed through both objective and subjective evaluations, show that DGSNA provides robust performance in dynamically generating precise SI and effectively enhancing scene-based noise addition capabilities, thus offering significant improvements over traditional methods in acoustic scene simulation. Our implementation and demos are available at https://dgsna.github.io.
Indoor Positioning System based on Visible Light Communication for Mobile Robot in Nuclear Power Plant
Nov 16, 2020
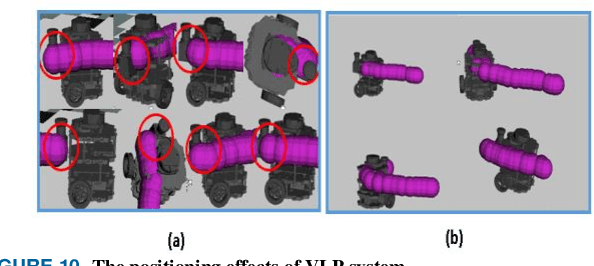

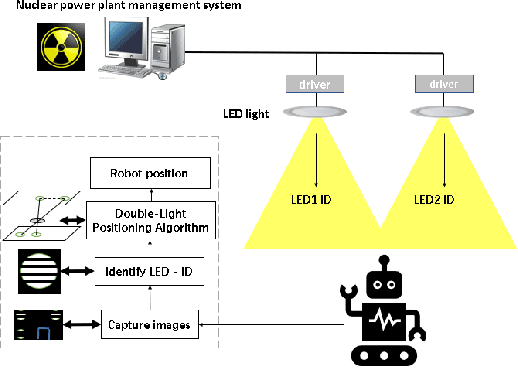
Visible light positioning (VLP) is widely believed to be a cost-effective answer to the growing demanded for robot indoor positioning. Considering that some extreme environments require robot to be equipped with a precise and radiation-resistance indoor positioning system for doing difficult work, a novel VLP system with high accuracy is proposed to realize the long-playing inspection and intervention under radiation environment. The proposed system with sufficient radiation-tolerance is critical for operational inspection, maintenance and intervention tasks in nuclear facilities. Firstly, we designed intelligent LED lamp with visible light communication (VLC) function to dynamically create the indoor GPS tracking system. By installing the proposed lamps that replace standard lighting in key locations in the nuclear power plant, the proposed system can strengthen the safety of mobile robot and help for efficient inspection in the large-scale field. Secondly, in order to enhance the radiation-tolerance and multi-scenario of the proposed system, we proposed a shielding protection method for the camera vertically installed on the robot, which ensures that the image elements of the camera namely the captured VLP information is not affected by radiation. Besides, with the optimized visible light positioning algorithm based on dispersion calibration method, the proposed VLP system can achieve an average positioning accuracy of 0.82cm and ensure that 90% positioning errors are less than 1.417cm. Therefore, the proposed system not only has sufficient radiation-tolerance but achieve state-of-the-art positioning accuracy in the visible light positioning field.