 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Crash Course: Learning Soft and Stylized Falling
Nov 13, 2025Despite recent advances in robust locomotion, bipedal robots operating in the real world remain at risk of falling. While most research focuses on preventing such events, we instead concentrate on the phenomenon of falling itself. Specifically, we aim to reduce physical damage to the robot while providing users with control over a robot's end pose. To this end, we propose a robot agnostic reward function that balances the achievement of a desired end pose with impact minimization and the protection of critical robot parts during reinforcement learning. To make the policy robust to a broad range of initial falling conditions and to enable the specification of an arbitrary and unseen end pose at inference time, we introduce a simulation-based sampling strategy of initial and end poses. Through simulated and real-world experiments, our work demonstrates that even bipedal robots can perform controlled, soft falls.
RobustDexGrasp: Robust Dexterous Grasping of General Objects from Single-view Perception
Apr 07, 2025
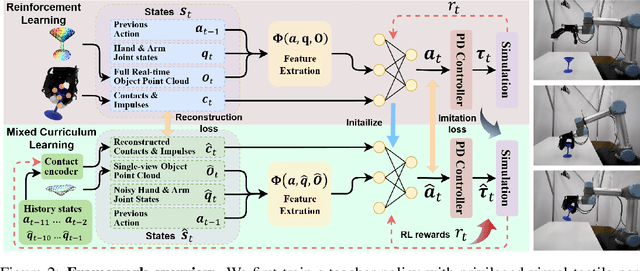
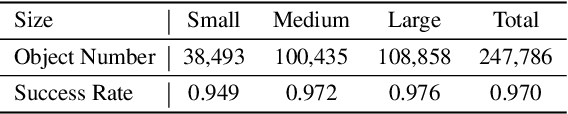
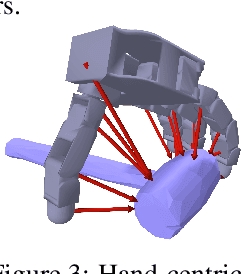
Robust grasping of various objects from single-view perception is fundamental for dexterous robots. Previous works often rely on fully observable objects, expert demonstrations, or static grasping poses, which restrict their generalization ability and adaptability to external disturbances. In this paper, we present a reinforcement-learning-based framework that enables zero-shot dynamic dexterous grasping of a wide range of unseen objects from single-view perception, while performing adaptive motions to external disturbances. We utilize a hand-centric object representation for shape feature extraction that emphasizes interaction-relevant local shapes, enhancing robustness to shape variance and uncertainty. To enable effective hand adaptation to disturbances with limited observations, we propose a mixed curriculum learning strategy, which first utilizes imitation learning to distill a policy trained with privileged real-time visual-tactile feedback, and gradually transfers to reinforcement learning to learn adaptive motions under disturbances caused by observation noises and dynamic randomization. Our experiments demonstrate strong generalization in grasping unseen objects with random poses, achieving success rates of 97.0% across 247,786 simulated objects and 94.6% across 512 real objects. We also demonstrate the robustness of our method to various disturbances, including unobserved object movement and external forces, through both quantitative and qualitative evaluations. Project Page: https://zdchan.github.io/Robust_DexGrasp/
Autonomous Human-Robot Interaction via Operator Imitation
Apr 03, 2025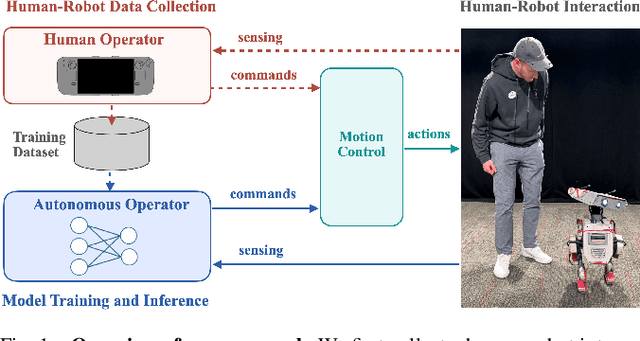



Teleoperated robotic characters can perform expressive interactions with humans, relying on the operators' experience and social intuition. In this work, we propose to create autonomous interactive robots, by training a model to imitate operator data. Our model is trained on a dataset of human-robot interactions, where an expert operator is asked to vary the interactions and mood of the robot, while the operator commands as well as the pose of the human and robot are recorded. Our approach learns to predict continuous operator commands through a diffusion process and discrete commands through a classifier, all unified within a single transformer architecture. We evaluate the resulting model in simulation and with a user study on the real system. We show that our method enables simple autonomous human-robot interactions that are comparable to the expert-operator baseline, and that users can recognize the different robot moods as generated by our model. Finally, we demonstrate a zero-shot transfer of our model onto a different robotic platform with the same operator interface.
Modeling Dynamic Hand-Object Interactions with Applications to Human-Robot Handovers
Mar 06, 2025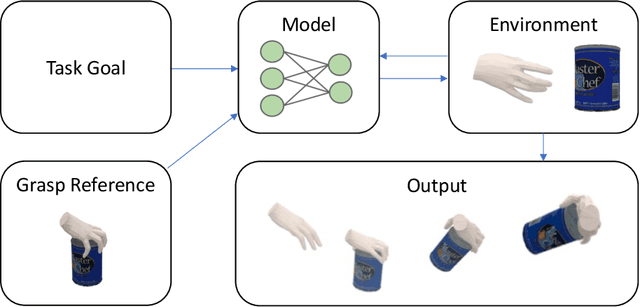
Humans frequently grasp, manipulate, and move objects. Interactive systems assist humans in these tasks, enabling applications in Embodied AI, human-robot interaction, and virtual reality. However, current methods in hand-object synthesis often neglect dynamics and focus on generating static grasps. The first part of this dissertation introduces dynamic grasp synthesis, where a hand grasps and moves an object to a target pose. We approach this task using physical simulation and reinforcement learning. We then extend this to bimanual manipulation and articulated objects, requiring fine-grained coordination between hands. In the second part of this dissertation, we study human-to-robot handovers. We integrate captured human motion into simulation and introduce a student-teacher framework that adapts to human behavior and transfers from sim to real. To overcome data scarcity, we generate synthetic interactions, increasing training diversity by 100x. Our user study finds no difference between policies trained on synthetic vs. real motions.
FunGrasp: Functional Grasping for Diverse Dexterous Hands
Nov 24, 2024



Functional grasping is essential for humans to perform specific tasks, such as grasping scissors by the finger holes to cut materials or by the blade to safely hand them over. Enabling dexterous robot hands with functional grasping capabilities is crucial for their deployment to accomplish diverse real-world tasks. Recent research in dexterous grasping, however, often focuses on power grasps while overlooking task- and object-specific functional grasping poses. In this paper, we introduce FunGrasp, a system that enables functional dexterous grasping across various robot hands and performs one-shot transfer to unseen objects. Given a single RGBD image of functional human grasping, our system estimates the hand pose and transfers it to different robotic hands via a human-to-robot (H2R) grasp retargeting module. Guided by the retargeted grasping poses, a policy is trained through reinforcement learning in simulation for dynamic grasping control. To achieve robust sim-to-real transfer, we employ several techniques including privileged learning, system identification, domain randomization, and gravity compensation. In our experiments, we demonstrate that our system enables diverse functional grasping of unseen objects using single RGBD images, and can be successfully deployed across various dexterous robot hands. The significance of the components is validated through comprehensive ablation studies. Project page: https://hly-123.github.io/FunGrasp/ .
EgoHDM: An Online Egocentric-Inertial Human Motion Capture, Localization, and Dense Mapping System
Aug 31, 2024



We present EgoHDM, an online egocentric-inertial human motion capture (mocap), localization, and dense mapping system. Our system uses 6 inertial measurement units (IMUs) and a commodity head-mounted RGB camera. EgoHDM is the first human mocap system that offers dense scene mapping in near real-time. Further, it is fast and robust to initialize and fully closes the loop between physically plausible map-aware global human motion estimation and mocap-aware 3D scene reconstruction. Our key idea is integrating camera localization and mapping information with inertial human motion capture bidirectionally in our system. To achieve this, we design a tightly coupled mocap-aware dense bundle adjustment and physics-based body pose correction module leveraging a local body-centric elevation map. The latter introduces a novel terrain-aware contact PD controller, which enables characters to physically contact the given local elevation map thereby reducing human floating or penetration. We demonstrate the performance of our system on established synthetic and real-world benchmarks. The results show that our method reduces human localization, camera pose, and mapping accuracy error by 41%, 71%, 46%, respectively, compared to the state of the art. Our qualitative evaluations on newly captured data further demonstrate that EgoHDM can cover challenging scenarios in non-flat terrain including stepping over stairs and outdoor scenes in the wild.
Grasping Diverse Objects with Simulated Humanoids
Jul 16, 2024We present a method for controlling a simulated humanoid to grasp an object and move it to follow an object trajectory. Due to the challenges in controlling a humanoid with dexterous hands, prior methods often use a disembodied hand and only consider vertical lifts or short trajectories. This limited scope hampers their applicability for object manipulation required for animation and simulation. To close this gap, we learn a controller that can pick up a large number (>1200) of objects and carry them to follow randomly generated trajectories. Our key insight is to leverage a humanoid motion representation that provides human-like motor skills and significantly speeds up training. Using only simplistic reward, state, and object representations, our method shows favorable scalability on diverse object and trajectories. For training, we do not need dataset of paired full-body motion and object trajectories. At test time, we only require the object mesh and desired trajectories for grasping and transporting. To demonstrate the capabilities of our method, we show state-of-the-art success rates in following object trajectories and generalizing to unseen objects. Code and models will be released.
RILe: Reinforced Imitation Learning
Jun 12, 2024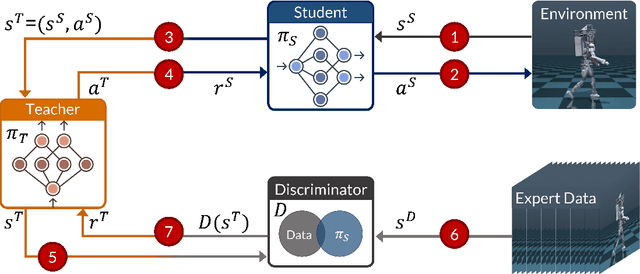
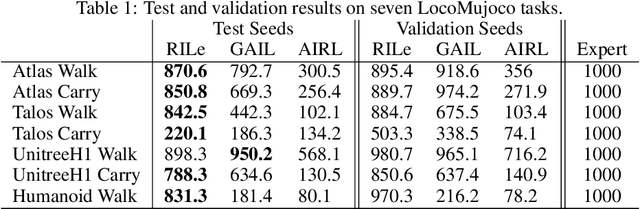
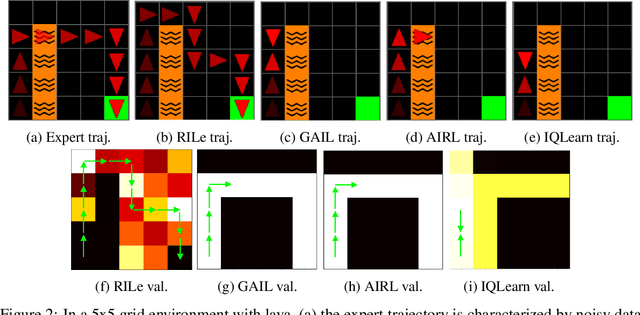
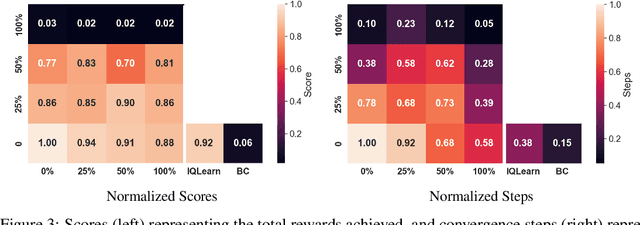
Reinforcement Learning has achieved significant success in generating complex behavior but often requires extensive reward function engineering. Adversarial variants of Imitation Learning and Inverse Reinforcement Learning offer an alternative by learning policies from expert demonstrations via a discriminator. Employing discriminators increases their data- and computational efficiency over the standard approaches; however, results in sensitivity to imperfections in expert data. We propose RILe, a teacher-student system that achieves both robustness to imperfect data and efficiency. In RILe, the student learns an action policy while the teacher dynamically adjusts a reward function based on the student's performance and its alignment with expert demonstrations. By tailoring the reward function to both performance of the student and expert similarity, our system reduces dependence on the discriminator and, hence, increases robustness against data imperfections. Experiments show that RILe outperforms existing methods by 2x in settings with limited or noisy expert data.
GraspXL: Generating Grasping Motions for Diverse Objects at Scale
Mar 28, 2024

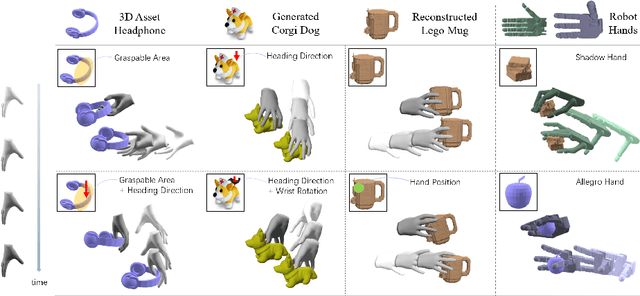
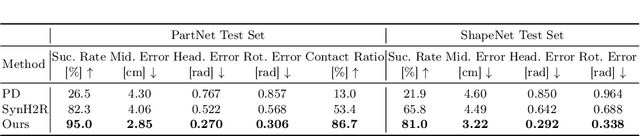
Human hands possess the dexterity to interact with diverse objects such as grasping specific parts of the objects and/or approaching them from desired directions. More importantly, humans can grasp objects of any shape without object-specific skills. Recent works synthesize grasping motions following single objectives such as a desired approach heading direction or a grasping area. Moreover, they usually rely on expensive 3D hand-object data during training and inference, which limits their capability to synthesize grasping motions for unseen objects at scale. In this paper, we unify the generation of hand-object grasping motions across multiple motion objectives, diverse object shapes and dexterous hand morphologies in a policy learning framework GraspXL. The objectives are composed of the graspable area, heading direction during approach, wrist rotation, and hand position. Without requiring any 3D hand-object interaction data, our policy trained with 58 objects can robustly synthesize diverse grasping motions for more than 500k unseen objects with a success rate of 82.2%. At the same time, the policy adheres to objectives, which enables the generation of diverse grasps per object. Moreover, we show that our framework can be deployed to different dexterous hands and work with reconstructed or generated objects. We quantitatively and qualitatively evaluate our method to show the efficacy of our approach. Our model and code will be available.
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
Mar 26, 2024



Generating natural hand-object interactions in 3D is challenging as the resulting hand and object motions are expected to be physically plausible and semantically meaningful. Furthermore, generalization to unseen objects is hindered by the limited scale of available hand-object interaction datasets. We propose DiffH2O, a novel method to synthesize realistic, one or two-handed object interactions from provided text prompts and geometry of the object. The method introduces three techniques that enable effective learning from limited data. First, we decompose the task into a grasping stage and a text-based interaction stage and use separate diffusion models for each. In the grasping stage, the model only generates hand motions, whereas in the interaction phase both hand and object poses are synthesized. Second, we propose a compact representation that tightly couples hand and object poses. Third, we propose two different guidance schemes to allow more control of the generated motions: grasp guidance and detailed textual guidance. Grasp guidance takes a single target grasping pose and guides the diffusion model to reach this grasp at the end of the grasping stage, which provides control over the grasping pose. Given a grasping motion from this stage, multiple different actions can be prompted in the interaction phase. For textual guidance, we contribute comprehensive text descriptions to the GRAB dataset and show that they enable our method to have more fine-grained control over hand-object interactions. Our quantitative and qualitative evaluation demonstrates that the proposed method outperforms baseline methods and leads to natural hand-object motions. Moreover, we demonstrate the practicality of our framework by utilizing a hand pose estimate from an off-the-shelf pose estimator for guidance, and then sampling multiple different actions in the interaction stage.