 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
Jan 07, 2026Humans anticipate, from a glance and a contemplated action of their bodies, how the 3D world will respond, a capability that is equally vital for robotic manipulation. We introduce PointWorld, a large pre-trained 3D world model that unifies state and action in a shared 3D space as 3D point flows: given one or few RGB-D images and a sequence of low-level robot action commands, PointWorld forecasts per-pixel displacements in 3D that respond to the given actions. By representing actions as 3D point flows instead of embodiment-specific action spaces (e.g., joint positions), this formulation directly conditions on physical geometries of robots while seamlessly integrating learning across embodiments. To train our 3D world model, we curate a large-scale dataset spanning real and simulated robotic manipulation in open-world environments, enabled by recent advances in 3D vision and simulated environments, totaling about 2M trajectories and 500 hours across a single-arm Franka and a bimanual humanoid. Through rigorous, large-scale empirical studies of backbones, action representations, learning objectives, partial observability, data mixtures, domain transfers, and scaling, we distill design principles for large-scale 3D world modeling. With a real-time (0.1s) inference speed, PointWorld can be efficiently integrated in the model-predictive control (MPC) framework for manipulation. We demonstrate that a single pre-trained checkpoint enables a real-world Franka robot to perform rigid-body pushing, deformable and articulated object manipulation, and tool use, without requiring any demonstrations or post-training and all from a single image captured in-the-wild. Project website at https://point-world.github.io/.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks
Oct 01, 2025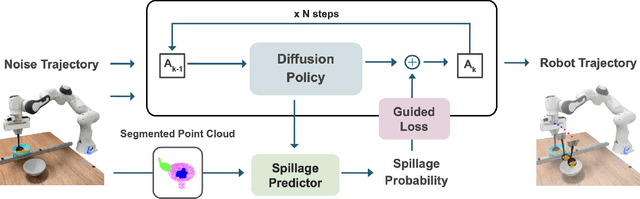
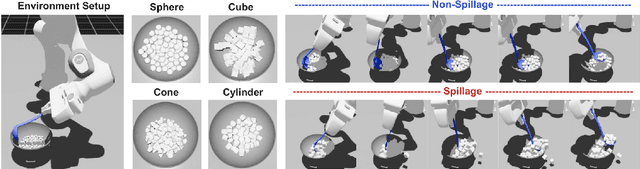


Robotic food scooping is a critical manipulation skill for food preparation and service robots. However, existing robot learning algorithms, especially learn-from-demonstration methods, still struggle to handle diverse and dynamic food states, which often results in spillage and reduced reliability. In this work, we introduce GRITS: A Spillage-Aware Guided Diffusion Policy for Robot Food Scooping Tasks. This framework leverages guided diffusion policy to minimize food spillage during scooping and to ensure reliable transfer of food items from the initial to the target location. Specifically, we design a spillage predictor that estimates the probability of spillage given current observation and action rollout. The predictor is trained on a simulated dataset with food spillage scenarios, constructed from four primitive shapes (spheres, cubes, cones, and cylinders) with varied physical properties such as mass, friction, and particle size. At inference time, the predictor serves as a differentiable guidance signal, steering the diffusion sampling process toward safer trajectories while preserving task success. We validate GRITS on a real-world robotic food scooping platform. GRITS is trained on six food categories and evaluated on ten unseen categories with different shapes and quantities. GRITS achieves an 82% task success rate and a 4% spillage rate, reducing spillage by over 40% compared to baselines without guidance, thereby demonstrating its effectiveness.
Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped Exploration
Sep 11, 2025Hand-object motion-capture (MoCap) repositories offer large-scale, contact-rich demonstrations and hold promise for scaling dexterous robotic manipulation. Yet demonstration inaccuracies and embodiment gaps between human and robot hands limit the straightforward use of these data. Existing methods adopt a three-stage workflow, including retargeting, tracking, and residual correction, which often leaves demonstrations underused and compound errors across stages. We introduce Dexplore, a unified single-loop optimization that jointly performs retargeting and tracking to learn robot control policies directly from MoCap at scale. Rather than treating demonstrations as ground truth, we use them as soft guidance. From raw trajectories, we derive adaptive spatial scopes, and train with reinforcement learning to keep the policy in-scope while minimizing control effort and accomplishing the task. This unified formulation preserves demonstration intent, enables robot-specific strategies to emerge, improves robustness to noise, and scales to large demonstration corpora. We distill the scaled tracking policy into a vision-based, skill-conditioned generative controller that encodes diverse manipulation skills in a rich latent representation, supporting generalization across objects and real-world deployment. Taken together, these contributions position Dexplore as a principled bridge that transforms imperfect demonstrations into effective training signals for dexterous manipulation.
GraspGen: A Diffusion-based Framework for 6-DOF Grasping with On-Generator Training
Jul 17, 2025Grasping is a fundamental robot skill, yet despite significant research advancements, learning-based 6-DOF grasping approaches are still not turnkey and struggle to generalize across different embodiments and in-the-wild settings. We build upon the recent success on modeling the object-centric grasp generation process as an iterative diffusion process. Our proposed framework, GraspGen, consists of a DiffusionTransformer architecture that enhances grasp generation, paired with an efficient discriminator to score and filter sampled grasps. We introduce a novel and performant on-generator training recipe for the discriminator. To scale GraspGen to both objects and grippers, we release a new simulated dataset consisting of over 53 million grasps. We demonstrate that GraspGen outperforms prior methods in simulations with singulated objects across different grippers, achieves state-of-the-art performance on the FetchBench grasping benchmark, and performs well on a real robot with noisy visual observations.
Slot-Level Robotic Placement via Visual Imitation from Single Human Video
Apr 02, 2025



The majority of modern robot learning methods focus on learning a set of pre-defined tasks with limited or no generalization to new tasks. Extending the robot skillset to novel tasks involves gathering an extensive amount of training data for additional tasks. In this paper, we address the problem of teaching new tasks to robots using human demonstration videos for repetitive tasks (e.g., packing). This task requires understanding the human video to identify which object is being manipulated (the pick object) and where it is being placed (the placement slot). In addition, it needs to re-identify the pick object and the placement slots during inference along with the relative poses to enable robot execution of the task. To tackle this, we propose SLeRP, a modular system that leverages several advanced visual foundation models and a novel slot-level placement detector Slot-Net, eliminating the need for expensive video demonstrations for training. We evaluate our system using a new benchmark of real-world videos. The evaluation results show that SLeRP outperforms several baselines and can be deployed on a real robot.
Inference-Time Policy Steering through Human Interactions
Nov 25, 2024



Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
Synthetica: Large Scale Synthetic Data for Robot Perception
Oct 28, 2024



Vision-based object detectors are a crucial basis for robotics applications as they provide valuable information about object localisation in the environment. These need to ensure high reliability in different lighting conditions, occlusions, and visual artifacts, all while running in real-time. Collecting and annotating real-world data for these networks is prohibitively time consuming and costly, especially for custom assets, such as industrial objects, making it untenable for generalization to in-the-wild scenarios. To this end, we present Synthetica, a method for large-scale synthetic data generation for training robust state estimators. This paper focuses on the task of object detection, an important problem which can serve as the front-end for most state estimation problems, such as pose estimation. Leveraging data from a photorealistic ray-tracing renderer, we scale up data generation, generating 2.7 million images, to train highly accurate real-time detection transformers. We present a collection of rendering randomization and training-time data augmentation techniques conducive to robust sim-to-real performance for vision tasks. We demonstrate state-of-the-art performance on the task of object detection while having detectors that run at 50-100Hz which is 9 times faster than the prior SOTA. We further demonstrate the usefulness of our training methodology for robotics applications by showcasing a pipeline for use in the real world with custom objects for which there do not exist prior datasets. Our work highlights the importance of scaling synthetic data generation for robust sim-to-real transfer while achieving the fastest real-time inference speeds. Videos and supplementary information can be found at this URL: https://sites.google.com/view/synthetica-vision.
Latent Action Pretraining from Videos
Oct 15, 2024



We introduce Latent Action Pretraining for general Action models (LAPA), an unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels. Existing Vision-Language-Action models require action labels typically collected by human teleoperators during pretraining, which significantly limits possible data sources and scale. In this work, we propose a method to learn from internet-scale videos that do not have robot action labels. We first train an action quantization model leveraging VQ-VAE-based objective to learn discrete latent actions between image frames, then pretrain a latent VLA model to predict these latent actions from observations and task descriptions, and finally finetune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that our method significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of-the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions. Training only on human manipulation videos also shows positive transfer, opening up the potential for leveraging web-scale data for robotics foundation model.
RVT-2: Learning Precise Manipulation from Few Demonstrations
Jun 12, 2024
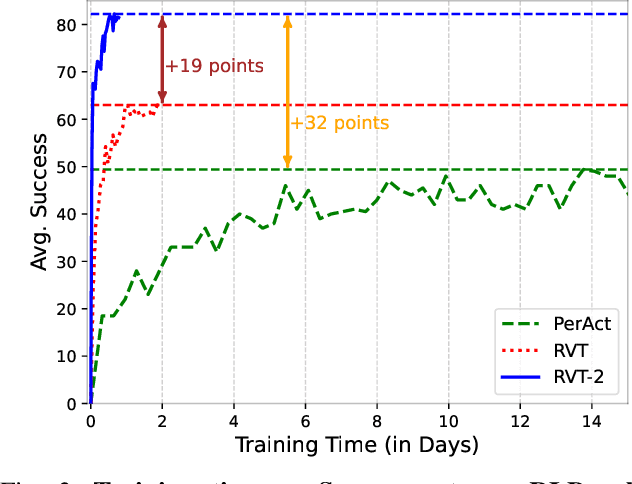


In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.