 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Nov 25, 2024

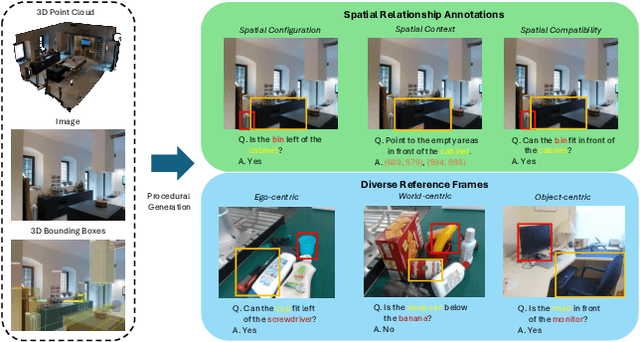

Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.
GRS: Generating Robotic Simulation Tasks from Real-World Images
Oct 20, 2024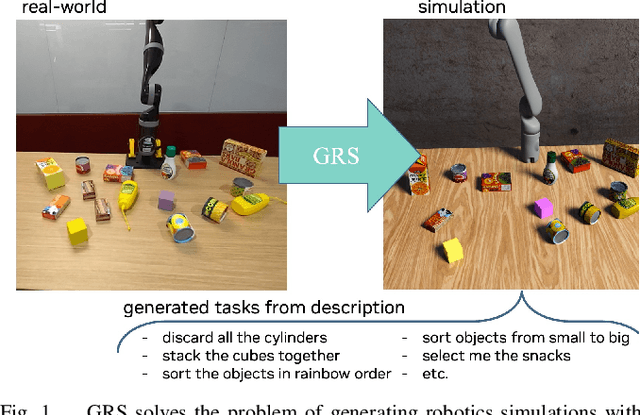
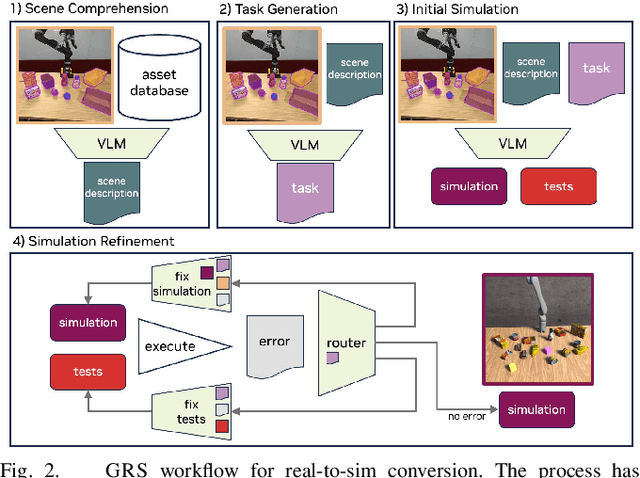


We introduce GRS (Generating Robotic Simulation tasks), a novel system to address the challenge of real-to-sim in robotics, computer vision, and AR/VR. GRS enables the creation of digital twin simulations from single real-world RGB-D observations, complete with diverse, solvable tasks for virtual agent training. We use state-of-the-art vision-language models (VLMs) to achieve a comprehensive real-to-sim pipeline. GRS operates in three stages: 1) scene comprehension using SAM2 for object segmentation and VLMs for object description, 2) matching identified objects with simulation-ready assets, and 3) generating contextually appropriate robotic tasks. Our approach ensures simulations align with task specifications by generating test suites designed to verify adherence to the task specification. We introduce a router that iteratively refines the simulation and test code to ensure the simulation is solvable by a robot policy while remaining aligned to the task specification. Our experiments demonstrate the system's efficacy in accurately identifying object correspondence, which allows us to generate task environments that closely match input environments, and enhance automated simulation task generation through our novel router mechanism.
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Jun 26, 2024



Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics
Jun 15, 2024From rearranging objects on a table to putting groceries into shelves, robots must plan precise action points to perform tasks accurately and reliably. In spite of the recent adoption of vision language models (VLMs) to control robot behavior, VLMs struggle to precisely articulate robot actions using language. We introduce an automatic synthetic data generation pipeline that instruction-tunes VLMs to robotic domains and needs. Using the pipeline, we train RoboPoint, a VLM that predicts image keypoint affordances given language instructions. Compared to alternative approaches, our method requires no real-world data collection or human demonstration, making it much more scalable to diverse environments and viewpoints. In addition, RoboPoint is a general model that enables several downstream applications such as robot navigation, manipulation, and augmented reality (AR) assistance. Our experiments demonstrate that RoboPoint outperforms state-of-the-art VLMs (GPT-4o) and visual prompting techniques (PIVOT) by 21.8% in the accuracy of predicting spatial affordance and by 30.5% in the success rate of downstream tasks. Project website: https://robo-point.github.io.
RVT-2: Learning Precise Manipulation from Few Demonstrations
Jun 12, 2024
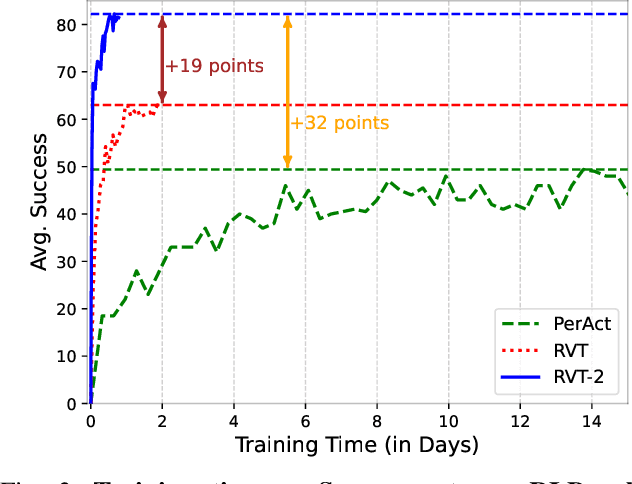


In this work, we study how to build a robotic system that can solve multiple 3D manipulation tasks given language instructions. To be useful in industrial and household domains, such a system should be capable of learning new tasks with few demonstrations and solving them precisely. Prior works, like PerAct and RVT, have studied this problem, however, they often struggle with tasks requiring high precision. We study how to make them more effective, precise, and fast. Using a combination of architectural and system-level improvements, we propose RVT-2, a multitask 3D manipulation model that is 6X faster in training and 2X faster in inference than its predecessor RVT. RVT-2 achieves a new state-of-the-art on RLBench, improving the success rate from 65% to 82%. RVT-2 is also effective in the real world, where it can learn tasks requiring high precision, like picking up and inserting plugs, with just 10 demonstrations. Visual results, code, and trained model are provided at: https://robotic-view-transformer-2.github.io/.
Neural Implicit Representation for Building Digital Twins of Unknown Articulated Objects
Apr 01, 2024We address the problem of building digital twins of unknown articulated objects from two RGBD scans of the object at different articulation states. We decompose the problem into two stages, each addressing distinct aspects. Our method first reconstructs object-level shape at each state, then recovers the underlying articulation model including part segmentation and joint articulations that associate the two states. By explicitly modeling point-level correspondences and exploiting cues from images, 3D reconstructions, and kinematics, our method yields more accurate and stable results compared to prior work. It also handles more than one movable part and does not rely on any object shape or structure priors. Project page: https://github.com/NVlabs/DigitalTwinArt
Snap-it, Tap-it, Splat-it: Tactile-Informed 3D Gaussian Splatting for Reconstructing Challenging Surfaces
Mar 29, 2024



Touch and vision go hand in hand, mutually enhancing our ability to understand the world. From a research perspective, the problem of mixing touch and vision is underexplored and presents interesting challenges. To this end, we propose Tactile-Informed 3DGS, a novel approach that incorporates touch data (local depth maps) with multi-view vision data to achieve surface reconstruction and novel view synthesis. Our method optimises 3D Gaussian primitives to accurately model the object's geometry at points of contact. By creating a framework that decreases the transmittance at touch locations, we achieve a refined surface reconstruction, ensuring a uniformly smooth depth map. Touch is particularly useful when considering non-Lambertian objects (e.g. shiny or reflective surfaces) since contemporary methods tend to fail to reconstruct with fidelity specular highlights. By combining vision and tactile sensing, we achieve more accurate geometry reconstructions with fewer images than prior methods. We conduct evaluation on objects with glossy and reflective surfaces and demonstrate the effectiveness of our approach, offering significant improvements in reconstruction quality.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023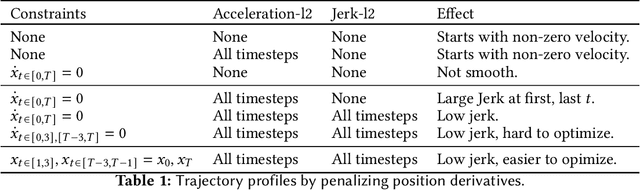
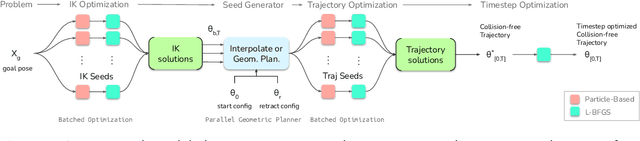
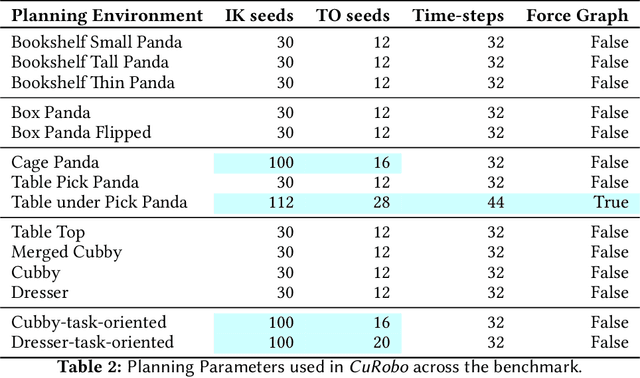
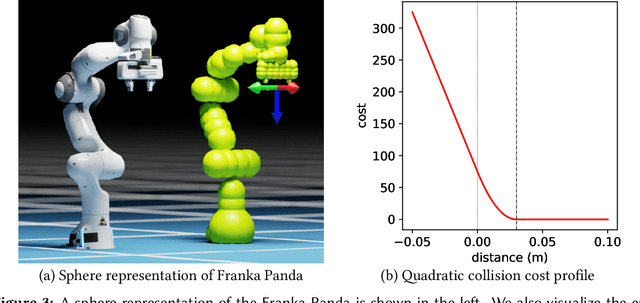
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
Diff-DOPE: Differentiable Deep Object Pose Estimation
Sep 30, 2023
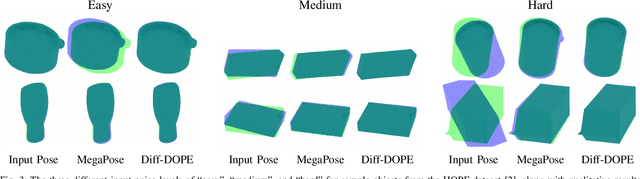
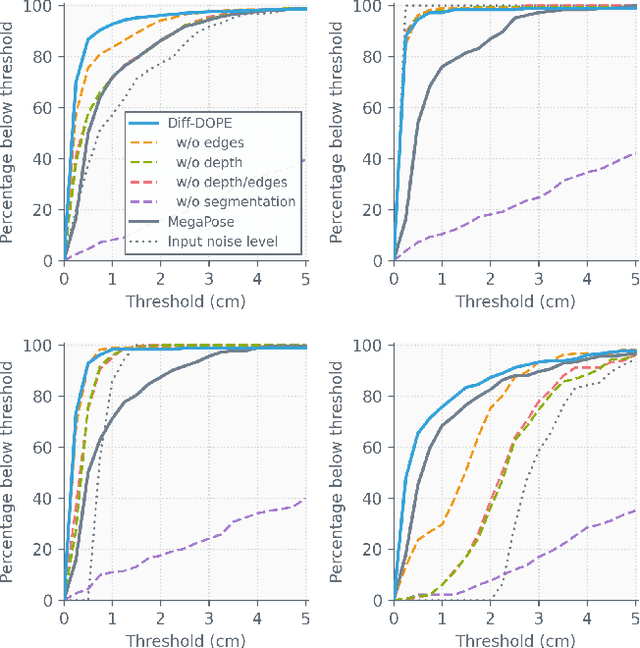

We introduce Diff-DOPE, a 6-DoF pose refiner that takes as input an image, a 3D textured model of an object, and an initial pose of the object. The method uses differentiable rendering to update the object pose to minimize the visual error between the image and the projection of the model. We show that this simple, yet effective, idea is able to achieve state-of-the-art results on pose estimation datasets. Our approach is a departure from recent methods in which the pose refiner is a deep neural network trained on a large synthetic dataset to map inputs to refinement steps. Rather, our use of differentiable rendering allows us to avoid training altogether. Our approach performs multiple gradient descent optimizations in parallel with different random learning rates to avoid local minima from symmetric objects, similar appearances, or wrong step size. Various modalities can be used, e.g., RGB, depth, intensity edges, and object segmentation masks. We present experiments examining the effect of various choices, showing that the best results are found when the RGB image is accompanied by an object mask and depth image to guide the optimization process.