 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Nov 25, 2024

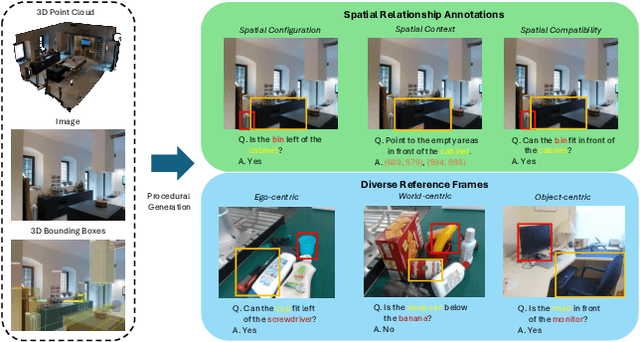

Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.
Diff-DOPE: Differentiable Deep Object Pose Estimation
Sep 30, 2023
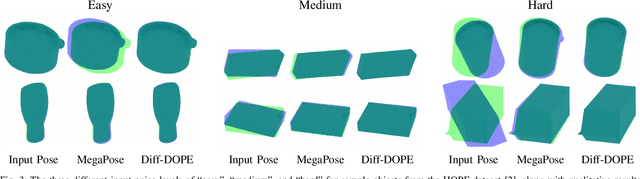
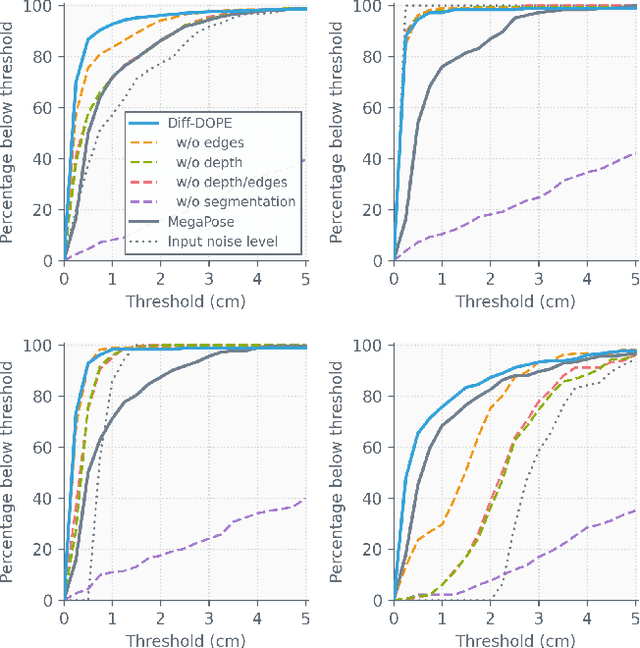

We introduce Diff-DOPE, a 6-DoF pose refiner that takes as input an image, a 3D textured model of an object, and an initial pose of the object. The method uses differentiable rendering to update the object pose to minimize the visual error between the image and the projection of the model. We show that this simple, yet effective, idea is able to achieve state-of-the-art results on pose estimation datasets. Our approach is a departure from recent methods in which the pose refiner is a deep neural network trained on a large synthetic dataset to map inputs to refinement steps. Rather, our use of differentiable rendering allows us to avoid training altogether. Our approach performs multiple gradient descent optimizations in parallel with different random learning rates to avoid local minima from symmetric objects, similar appearances, or wrong step size. Various modalities can be used, e.g., RGB, depth, intensity edges, and object segmentation masks. We present experiments examining the effect of various choices, showing that the best results are found when the RGB image is accompanied by an object mask and depth image to guide the optimization process.
HANDAL: A Dataset of Real-World Manipulable Object Categories with Pose Annotations, Affordances, and Reconstructions
Aug 02, 2023We present the HANDAL dataset for category-level object pose estimation and affordance prediction. Unlike previous datasets, ours is focused on robotics-ready manipulable objects that are of the proper size and shape for functional grasping by robot manipulators, such as pliers, utensils, and screwdrivers. Our annotation process is streamlined, requiring only a single off-the-shelf camera and semi-automated processing, allowing us to produce high-quality 3D annotations without crowd-sourcing. The dataset consists of 308k annotated image frames from 2.2k videos of 212 real-world objects in 17 categories. We focus on hardware and kitchen tool objects to facilitate research in practical scenarios in which a robot manipulator needs to interact with the environment beyond simple pushing or indiscriminate grasping. We outline the usefulness of our dataset for 6-DoF category-level pose+scale estimation and related tasks. We also provide 3D reconstructed meshes of all objects, and we outline some of the bottlenecks to be addressed for democratizing the collection of datasets like this one.
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Dec 13, 2022



We introduce MegaPose, a method to estimate the 6D pose of novel objects, that is, objects unseen during training. At inference time, the method only assumes knowledge of (i) a region of interest displaying the object in the image and (ii) a CAD model of the observed object. The contributions of this work are threefold. First, we present a 6D pose refiner based on a render&compare strategy which can be applied to novel objects. The shape and coordinate system of the novel object are provided as inputs to the network by rendering multiple synthetic views of the object's CAD model. Second, we introduce a novel approach for coarse pose estimation which leverages a network trained to classify whether the pose error between a synthetic rendering and an observed image of the same object can be corrected by the refiner. Third, we introduce a large-scale synthetic dataset of photorealistic images of thousands of objects with diverse visual and shape properties and show that this diversity is crucial to obtain good generalization performance on novel objects. We train our approach on this large synthetic dataset and apply it without retraining to hundreds of novel objects in real images from several pose estimation benchmarks. Our approach achieves state-of-the-art performance on the ModelNet and YCB-Video datasets. An extensive evaluation on the 7 core datasets of the BOP challenge demonstrates that our approach achieves performance competitive with existing approaches that require access to the target objects during training. Code, dataset and trained models are available on the project page: https://megapose6d.github.io/.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022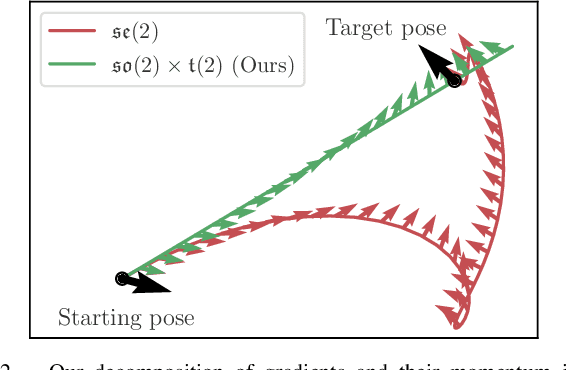
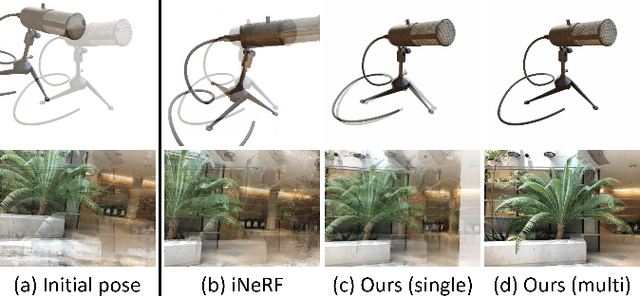
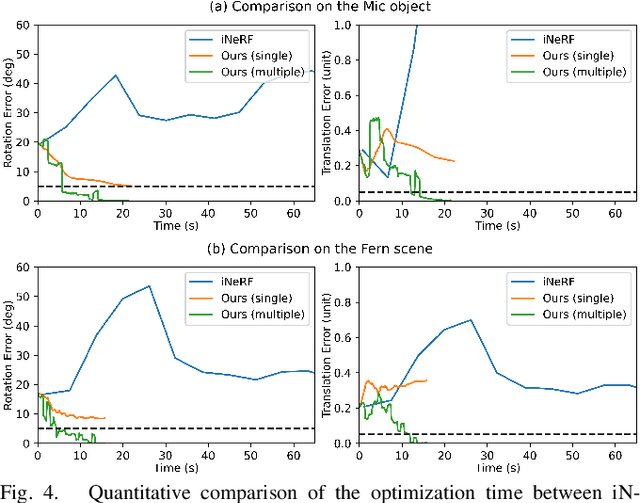

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Keypoint-Based Category-Level Object Pose Tracking from an RGB Sequence with Uncertainty Estimation
May 23, 2022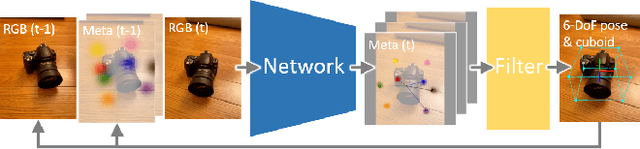
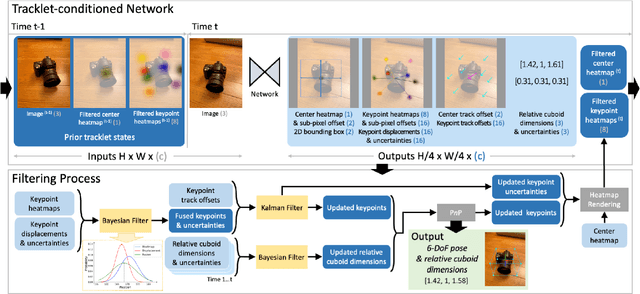
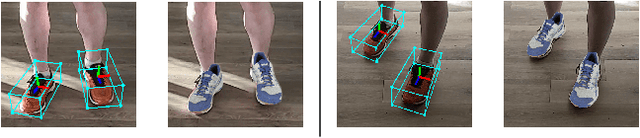
We propose a single-stage, category-level 6-DoF pose estimation algorithm that simultaneously detects and tracks instances of objects within a known category. Our method takes as input the previous and current frame from a monocular RGB video, as well as predictions from the previous frame, to predict the bounding cuboid and 6-DoF pose (up to scale). Internally, a deep network predicts distributions over object keypoints (vertices of the bounding cuboid) in image coordinates, after which a novel probabilistic filtering process integrates across estimates before computing the final pose using PnP. Our framework allows the system to take previous uncertainties into consideration when predicting the current frame, resulting in predictions that are more accurate and stable than single frame methods. Extensive experiments show that our method outperforms existing approaches on the challenging Objectron benchmark of annotated object videos. We also demonstrate the usability of our work in an augmented reality setting.
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
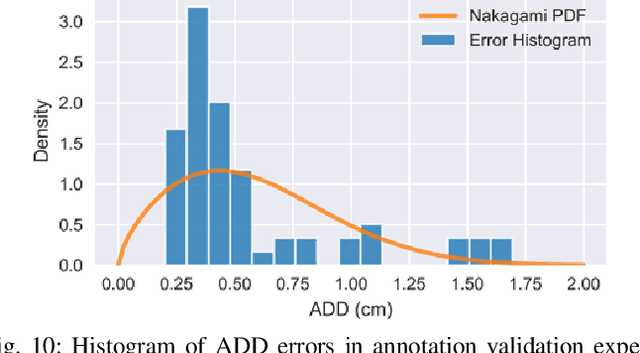
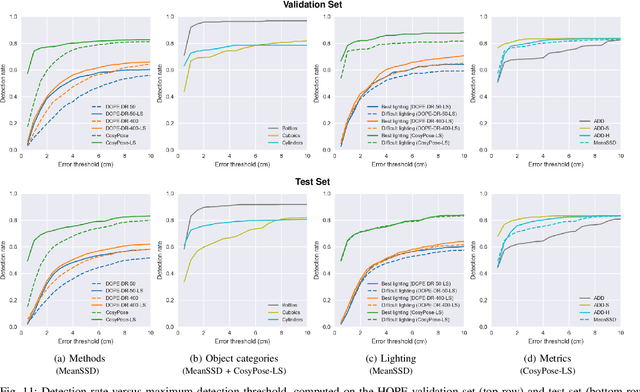
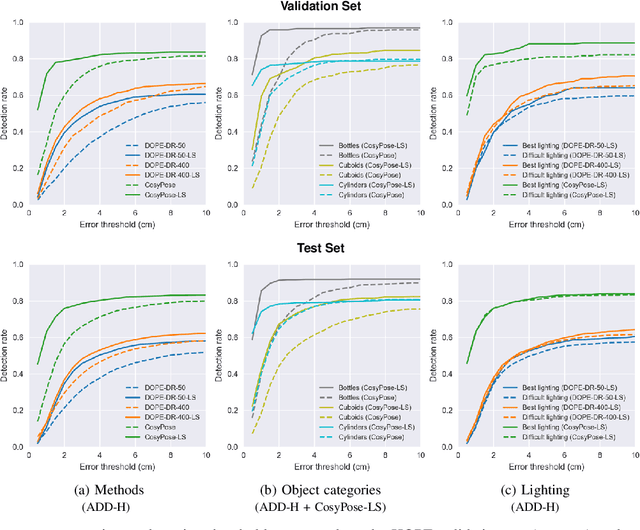
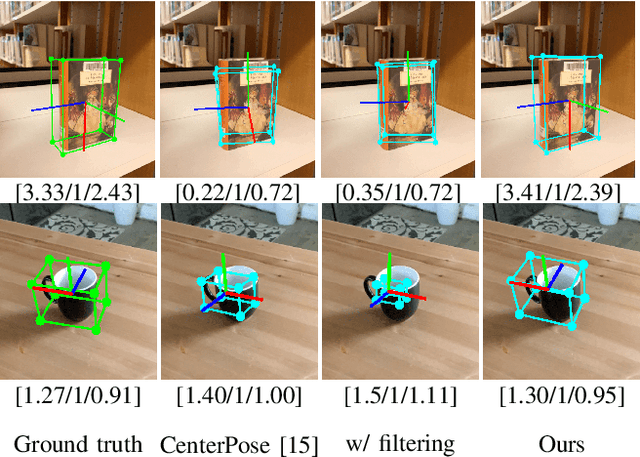
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
Single-stage Keypoint-based Category-level Object Pose Estimation from an RGB Image
Sep 13, 2021
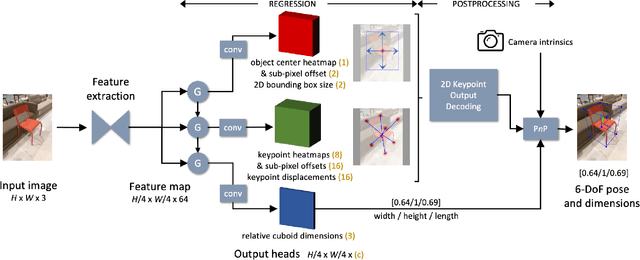

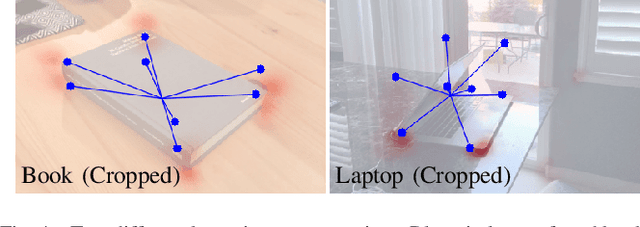
Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward developing robotic vision systems that operate in unstructured, real-world scenarios. In this work, we propose a single-stage, keypoint-based approach for category-level object pose estimation that operates on unknown object instances within a known category using a single RGB image as input. The proposed network performs 2D object detection, detects 2D keypoints, estimates 6-DoF pose, and regresses relative bounding cuboid dimensions. These quantities are estimated in a sequential fashion, leveraging the recent idea of convGRU for propagating information from easier tasks to those that are more difficult. We favor simplicity in our design choices: generic cuboid vertex coordinates, single-stage network, and monocular RGB input. We conduct extensive experiments on the challenging Objectron benchmark, outperforming state-of-the-art methods on the 3D IoU metric (27.6% higher than the MobilePose single-stage approach and 7.1% higher than the related two-stage approach).