 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent6D: Event-based Novel Object 6D Pose Tracking
Mar 30, 2026Event cameras provide microsecond latency, making them suitable for 6D object pose tracking in fast, dynamic scenes where conventional RGB and depth pipelines suffer from motion blur and large pixel displacements. We introduce EventTrack6D, an event-depth tracking framework that generalizes to novel objects without object-specific training by reconstructing both intensity and depth at arbitrary timestamps between depth frames. Conditioned on the most recent depth measurement, our dual reconstruction recovers dense photometric and geometric cues from sparse event streams. Our EventTrack6D operates at over 120 FPS and maintains temporal consistency under rapid motion. To support training and evaluation, we introduce a comprehensive benchmark suite: a large-scale synthetic dataset for training and two complementary evaluation sets, including real and simulated event datasets. Trained exclusively on synthetic data, EventTrack6D generalizes effectively to real-world scenarios without fine-tuning, maintaining accurate tracking across diverse objects and motion patterns. Our method and datasets validate the effectiveness of event cameras for event-based 6D pose tracking of novel objects. Code and datasets are publicly available at https://chohoonhee.github.io/Event6D.
GeoNVS: Geometry Grounded Video Diffusion for Novel View Synthesis
Mar 16, 2026Novel view synthesis requires strong 3D geometric consistency and the ability to generate visually coherent images across diverse viewpoints. While recent camera-controlled video diffusion models show promising results, they often suffer from geometric distortions and limited camera controllability. To overcome these challenges, we introduce GeoNVS, a geometry-grounded novel-view synthesizer that enhances both geometric fidelity and camera controllability through explicit 3D geometric guidance. Our key innovation is the Gaussian Splat Feature Adapter (GS-Adapter), which lifts input-view diffusion features into 3D Gaussian representations, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features to correct geometrically inconsistent representations. Unlike prior methods that inject geometry at the input level, GS-Adapter operates in feature space, avoiding view-dependent color noise that degrades structural consistency. Its plug-and-play design enables zero-shot compatibility with diverse feed-forward geometry models without additional training, and can be adapted to other video diffusion backbones. Experiments across 9 scenes and 18 settings demonstrate state-of-the-art performance, achieving 11.3% and 14.9% improvements over SEVA and CameraCtrl, with up to 2x reduction in translation error and 7x in Chamfer Distance.
GraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025
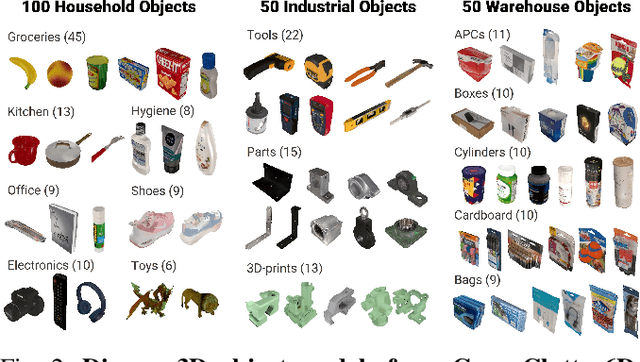
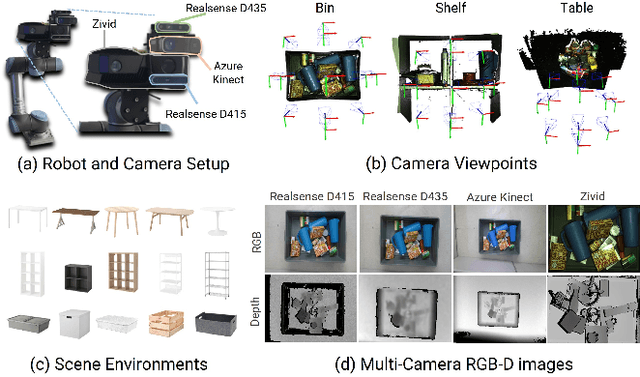
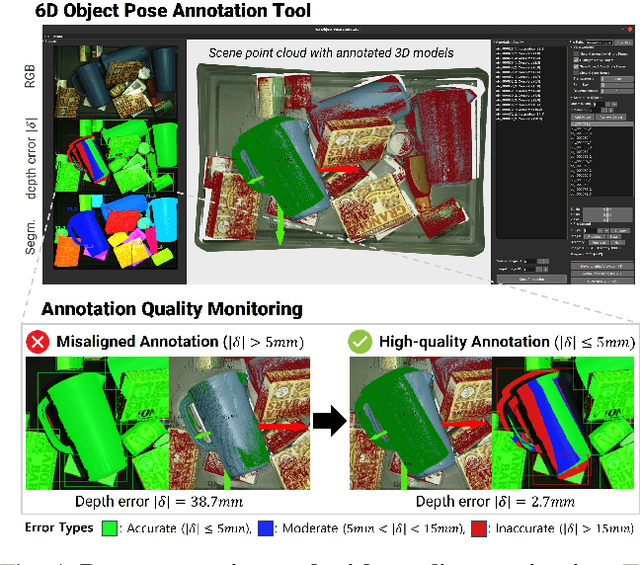
Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
BOP Challenge 2024 on Model-Based and Model-Free 6D Object Pose Estimation
Apr 03, 2025We present the evaluation methodology, datasets and results of the BOP Challenge 2024, the sixth in a series of public competitions organized to capture the state of the art in 6D object pose estimation and related tasks. In 2024, our goal was to transition BOP from lab-like setups to real-world scenarios. First, we introduced new model-free tasks, where no 3D object models are available and methods need to onboard objects just from provided reference videos. Second, we defined a new, more practical 6D object detection task where identities of objects visible in a test image are not provided as input. Third, we introduced new BOP-H3 datasets recorded with high-resolution sensors and AR/VR headsets, closely resembling real-world scenarios. BOP-H3 include 3D models and onboarding videos to support both model-based and model-free tasks. Participants competed on seven challenge tracks, each defined by a task, object onboarding setup, and dataset group. Notably, the best 2024 method for model-based 6D localization of unseen objects (FreeZeV2.1) achieves 22% higher accuracy on BOP-Classic-Core than the best 2023 method (GenFlow), and is only 4% behind the best 2023 method for seen objects (GPose2023) although being significantly slower (24.9 vs 2.7s per image). A more practical 2024 method for this task is Co-op which takes only 0.8s per image and is 25X faster and 13% more accurate than GenFlow. Methods have a similar ranking on 6D detection as on 6D localization but higher run time. On model-based 2D detection of unseen objects, the best 2024 method (MUSE) achieves 21% relative improvement compared to the best 2023 method (CNOS). However, the 2D detection accuracy for unseen objects is still noticealy (-53%) behind the accuracy for seen objects (GDet2023). The online evaluation system stays open and is available at http://bop.felk.cvut.cz/
Any6D: Model-free 6D Pose Estimation of Novel Objects
Mar 25, 2025We introduce Any6D, a model-free framework for 6D object pose estimation that requires only a single RGB-D anchor image to estimate both the 6D pose and size of unknown objects in novel scenes. Unlike existing methods that rely on textured 3D models or multiple viewpoints, Any6D leverages a joint object alignment process to enhance 2D-3D alignment and metric scale estimation for improved pose accuracy. Our approach integrates a render-and-compare strategy to generate and refine pose hypotheses, enabling robust performance in scenarios with occlusions, non-overlapping views, diverse lighting conditions, and large cross-environment variations. We evaluate our method on five challenging datasets: REAL275, Toyota-Light, HO3D, YCBINEOAT, and LM-O, demonstrating its effectiveness in significantly outperforming state-of-the-art methods for novel object pose estimation. Project page: https://taeyeop.com/any6d
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
TTA-COPE: Test-Time Adaptation for Category-Level Object Pose Estimation
Mar 29, 2023
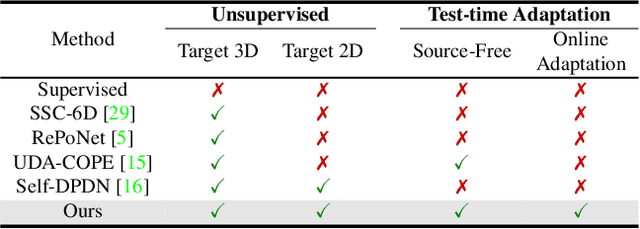
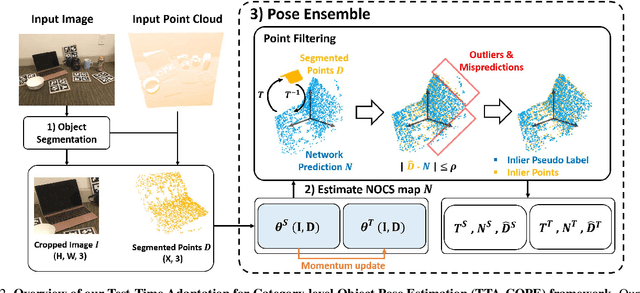
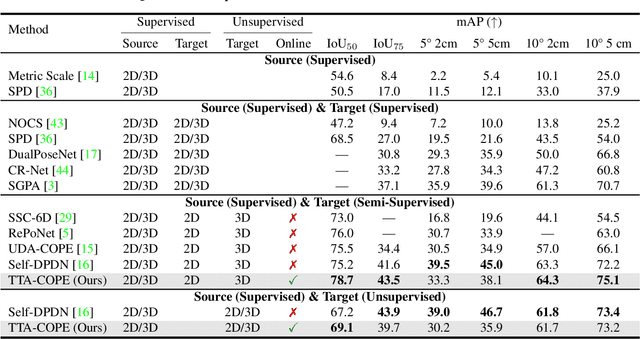
Test-time adaptation methods have been gaining attention recently as a practical solution for addressing source-to-target domain gaps by gradually updating the model without requiring labels on the target data. In this paper, we propose a method of test-time adaptation for category-level object pose estimation called TTA-COPE. We design a pose ensemble approach with a self-training loss using pose-aware confidence. Unlike previous unsupervised domain adaptation methods for category-level object pose estimation, our approach processes the test data in a sequential, online manner, and it does not require access to the source domain at runtime. Extensive experimental results demonstrate that the proposed pose ensemble and the self-training loss improve category-level object pose performance during test time under both semi-supervised and unsupervised settings. Project page: https://taeyeop.com/ttacope
UDA-COPE: Unsupervised Domain Adaptation for Category-level Object Pose Estimation
Nov 24, 2021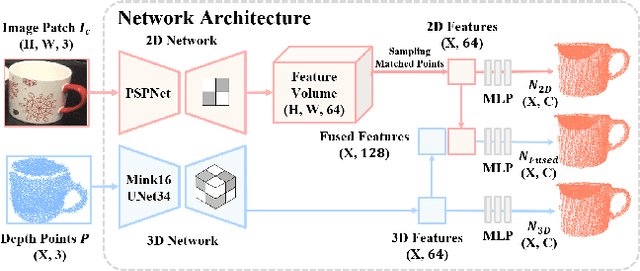
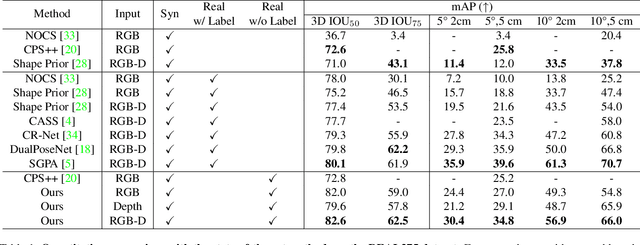
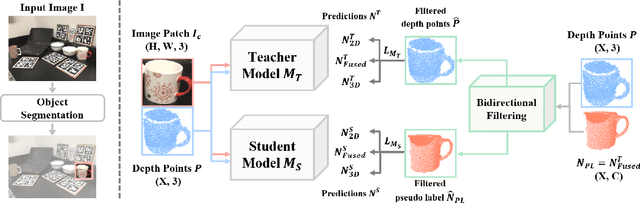

Learning to estimate object pose often requires ground-truth (GT) labels, such as CAD model and absolute-scale object pose, which is expensive and laborious to obtain in the real world. To tackle this problem, we propose an unsupervised domain adaptation (UDA) for category-level object pose estimation, called \textbf{UDA-COPE}. Inspired by the recent multi-modal UDA techniques, the proposed method exploits a teacher-student self-supervised learning scheme to train a pose estimation network without using target domain labels. We also introduce a bidirectional filtering method between predicted normalized object coordinate space (NOCS) map and observed point cloud, to not only make our teacher network more robust to the target domain but also to provide more reliable pseudo labels for the student network training. Extensive experimental results demonstrate the effectiveness of our proposed method both quantitatively and qualitatively. Notably, without leveraging target-domain GT labels, our proposed method achieves comparable or sometimes superior performance to existing methods that depend on the GT labels.
Category-Level Metric Scale Object Shape and Pose Estimation
Sep 01, 2021
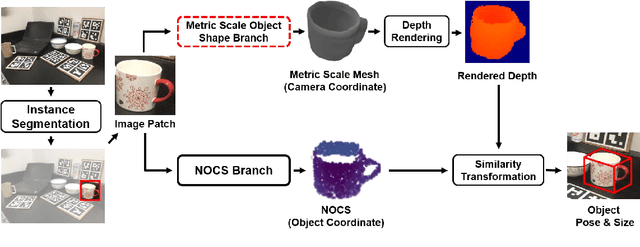
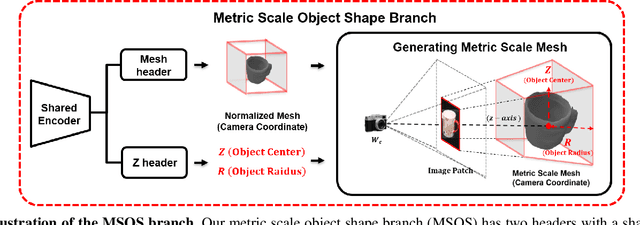
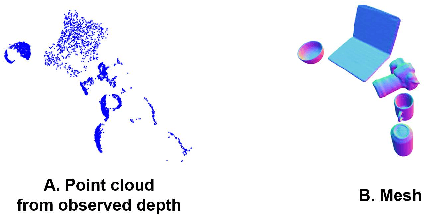
Advances in deep learning recognition have led to accurate object detection with 2D images. However, these 2D perception methods are insufficient for complete 3D world information. Concurrently, advanced 3D shape estimation approaches focus on the shape itself, without considering metric scale. These methods cannot determine the accurate location and orientation of objects. To tackle this problem, we propose a framework that jointly estimates a metric scale shape and pose from a single RGB image. Our framework has two branches: the Metric Scale Object Shape branch (MSOS) and the Normalized Object Coordinate Space branch (NOCS). The MSOS branch estimates the metric scale shape observed in the camera coordinates. The NOCS branch predicts the normalized object coordinate space (NOCS) map and performs similarity transformation with the rendered depth map from a predicted metric scale mesh to obtain 6d pose and size. Additionally, we introduce the Normalized Object Center Estimation (NOCE) to estimate the geometrically aligned distance from the camera to the object center. We validated our method on both synthetic and real-world datasets to evaluate category-level object pose and shape.