 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-SAM: Multi-view Promptable Segmentation using Pointmap Guidance
Jan 25, 2026Promptable segmentation has emerged as a powerful paradigm in computer vision, enabling users to guide models in parsing complex scenes with prompts such as clicks, boxes, or textual cues. Recent advances, exemplified by the Segment Anything Model (SAM), have extended this paradigm to videos and multi-view images. However, the lack of 3D awareness often leads to inconsistent results, necessitating costly per-scene optimization to enforce 3D consistency. In this work, we introduce MV-SAM, a framework for multi-view segmentation that achieves 3D consistency using pointmaps -- 3D points reconstructed from unposed images by recent visual geometry models. Leveraging the pixel-point one-to-one correspondence of pointmaps, MV-SAM lifts images and prompts into 3D space, eliminating the need for explicit 3D networks or annotated 3D data. Specifically, MV-SAM extends SAM by lifting image embeddings from its pretrained encoder into 3D point embeddings, which are decoded by a transformer using cross-attention with 3D prompt embeddings. This design aligns 2D interactions with 3D geometry, enabling the model to implicitly learn consistent masks across views through 3D positional embeddings. Trained on the SA-1B dataset, our method generalizes well across domains, outperforming SAM2-Video and achieving comparable performance with per-scene optimization baselines on NVOS, SPIn-NeRF, ScanNet++, uCo3D, and DL3DV benchmarks. Code will be released.
GaussExplorer: 3D Gaussian Splatting for Embodied Exploration and Reasoning
Jan 19, 2026We present GaussExplorer, a framework for embodied exploration and reasoning built on 3D Gaussian Splatting (3DGS). While prior approaches to language-embedded 3DGS have made meaningful progress in aligning simple text queries with Gaussian embeddings, they are generally optimized for relatively simple queries and struggle to interpret more complex, compositional language queries. Alternative studies based on object-centric RGB-D structured memories provide spatial grounding but are constrained by pre-fixed viewpoints. To address these issues, GaussExplorer introduces Vision-Language Models (VLMs) on top of 3DGS to enable question-driven exploration and reasoning within 3D scenes. We first identify pre-captured images that are most correlated with the query question, and subsequently adjust them into novel viewpoints to more accurately capture visual information for better reasoning by VLMs. Experiments show that ours outperforms existing methods on several benchmarks, demonstrating the effectiveness of integrating VLM-based reasoning with 3DGS for embodied tasks.
OpenVoxel: Training-Free Grouping and Captioning Voxels for Open-Vocabulary 3D Scene Understanding
Jan 14, 2026We propose OpenVoxel, a training-free algorithm for grouping and captioning sparse voxels for the open-vocabulary 3D scene understanding tasks. Given the sparse voxel rasterization (SVR) model obtained from multi-view images of a 3D scene, our OpenVoxel is able to produce meaningful groups that describe different objects in the scene. Also, by leveraging powerful Vision Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), our OpenVoxel successfully build an informative scene map by captioning each group, enabling further 3D scene understanding tasks such as open-vocabulary segmentation (OVS) or referring expression segmentation (RES). Unlike previous methods, our method is training-free and does not introduce embeddings from a CLIP/BERT text encoder. Instead, we directly proceed with text-to-text search using MLLMs. Through extensive experiments, our method demonstrates superior performance compared to recent studies, particularly in complex referring expression segmentation (RES) tasks. The code will be open.
Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian Splatting
Dec 24, 2025


Recent advancements in computer vision have successfully extended Open-vocabulary segmentation (OVS) to the 3D domain by leveraging 3D Gaussian Splatting (3D-GS). Despite this progress, efficiently rendering the high-dimensional features required for open-vocabulary queries poses a significant challenge. Existing methods employ codebooks or feature compression, causing information loss, thereby degrading segmentation quality. To address this limitation, we introduce Quantile Rendering (Q-Render), a novel rendering strategy for 3D Gaussians that efficiently handles high-dimensional features while maintaining high fidelity. Unlike conventional volume rendering, which densely samples all 3D Gaussians intersecting each ray, Q-Render sparsely samples only those with dominant influence along the ray. By integrating Q-Render into a generalizable 3D neural network, we also propose Gaussian Splatting Network (GS-Net), which predicts Gaussian features in a generalizable manner. Extensive experiments on ScanNet and LeRF demonstrate that our framework outperforms state-of-the-art methods, while enabling real-time rendering with an approximate ~43.7x speedup on 512-D feature maps. Code will be made publicly available.
Dr. Splat: Directly Referring 3D Gaussian Splatting via Direct Language Embedding Registration
Feb 23, 2025



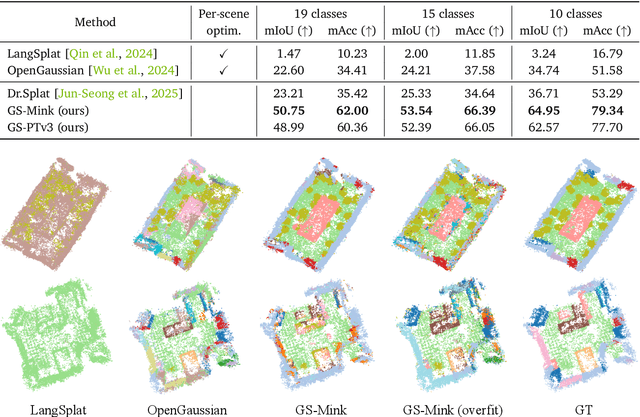
We introduce Dr. Splat, a novel approach for open-vocabulary 3D scene understanding leveraging 3D Gaussian Splatting. Unlike existing language-embedded 3DGS methods, which rely on a rendering process, our method directly associates language-aligned CLIP embeddings with 3D Gaussians for holistic 3D scene understanding. The key of our method is a language feature registration technique where CLIP embeddings are assigned to the dominant Gaussians intersected by each pixel-ray. Moreover, we integrate Product Quantization (PQ) trained on general large-scale image data to compactly represent embeddings without per-scene optimization. Experiments demonstrate that our approach significantly outperforms existing approaches in 3D perception benchmarks, such as open-vocabulary 3D semantic segmentation, 3D object localization, and 3D object selection tasks. For video results, please visit : https://drsplat.github.io/
Mosaic3D: Foundation Dataset and Model for Open-Vocabulary 3D Segmentation
Feb 04, 2025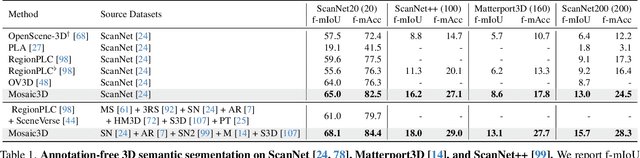

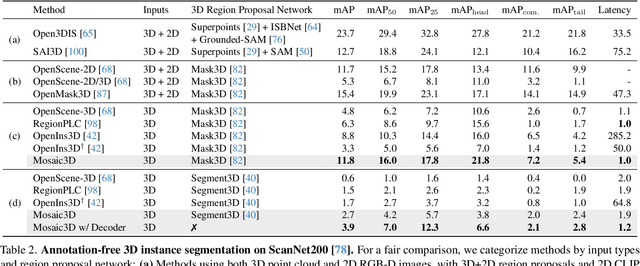
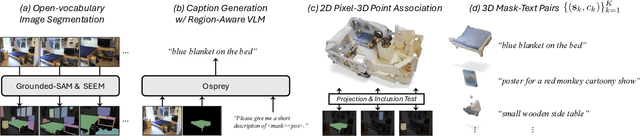
We tackle open-vocabulary 3D scene understanding by introducing a novel data generation pipeline and training framework. Our method addresses three critical requirements for effective training: precise 3D region segmentation, comprehensive textual descriptions, and sufficient dataset scale. By leveraging state-of-the-art open-vocabulary image segmentation models and region-aware Vision-Language Models, we develop an automatic pipeline that generates high-quality 3D mask-text pairs. Applying this pipeline to multiple 3D scene datasets, we create Mosaic3D-5.6M, a dataset of over 30K annotated scenes with 5.6M mask-text pairs, significantly larger than existing datasets. Building upon this data, we propose Mosaic3D, a foundation model combining a 3D encoder trained with contrastive learning and a lightweight mask decoder for open-vocabulary 3D semantic and instance segmentation. Our approach achieves state-of-the-art results on open-vocabulary 3D semantic and instance segmentation tasks including ScanNet200, Matterport3D, and ScanNet++, with ablation studies validating the effectiveness of our large-scale training data.
Sparse Voxels Rasterization: Real-time High-fidelity Radiance Field Rendering
Dec 05, 2024We propose an efficient radiance field rendering algorithm that incorporates a rasterization process on sparse voxels without neural networks or 3D Gaussians. There are two key contributions coupled with the proposed system. The first is to render sparse voxels in the correct depth order along pixel rays by using dynamic Morton ordering. This avoids the well-known popping artifact found in Gaussian splatting. Second, we adaptively fit sparse voxels to different levels of detail within scenes, faithfully reproducing scene details while achieving high rendering frame rates. Our method improves the previous neural-free voxel grid representation by over 4db PSNR and more than 10x rendering FPS speedup, achieving state-of-the-art comparable novel-view synthesis results. Additionally, our neural-free sparse voxels are seamlessly compatible with grid-based 3D processing algorithms. We achieve promising mesh reconstruction accuracy by integrating TSDF-Fusion and Marching Cubes into our sparse grid system.
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
MATE: Masked Autoencoders are Online 3D Test-Time Learners
Nov 24, 2022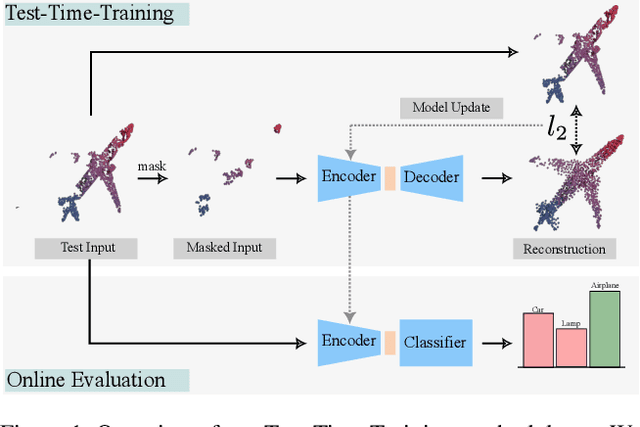



We propose MATE, the first Test-Time-Training (TTT) method designed for 3D data. It makes deep networks trained in point cloud classification robust to distribution shifts occurring in test data, which could not be anticipated during training. Like existing TTT methods, which focused on classifying 2D images in the presence of distribution shifts at test-time, MATE also leverages test data for adaptation. Its test-time objective is that of a Masked Autoencoder: Each test point cloud has a large portion of its points removed before it is fed to the network, tasked with reconstructing the full point cloud. Once the network is updated, it is used to classify the point cloud. We test MATE on several 3D object classification datasets and show that it significantly improves robustness of deep networks to several types of corruptions commonly occurring in 3D point clouds. Further, we show that MATE is very efficient in terms of the fraction of points it needs for the adaptation. It can effectively adapt given as few as 5% of tokens of each test sample, which reduces its memory footprint and makes it lightweight. We also highlight that MATE achieves competitive performance by adapting sparingly on the test data, which further reduces its computational overhead, making it ideal for real-time applications.
PointMixer: MLP-Mixer for Point Cloud Understanding
Nov 27, 2021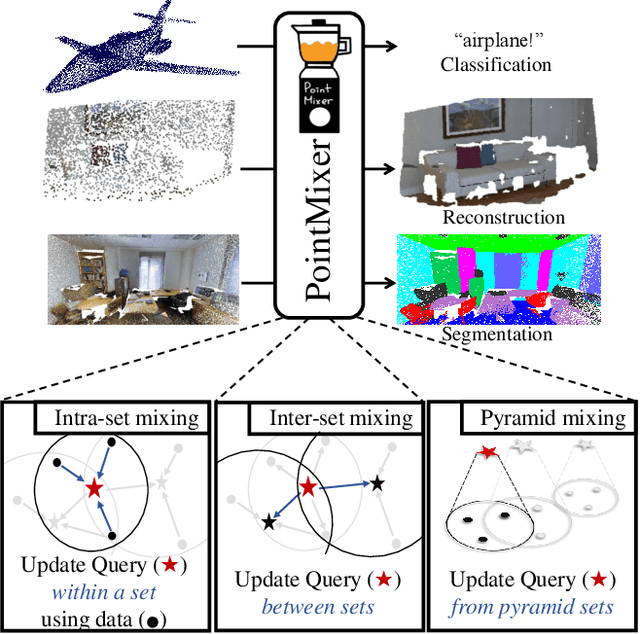

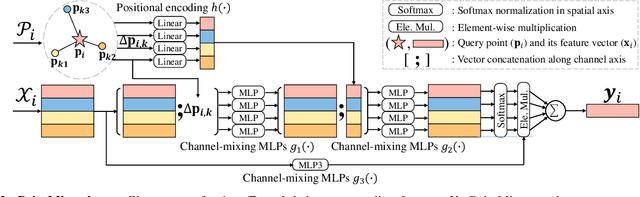

MLP-Mixer has newly appeared as a new challenger against the realm of CNNs and transformer. Despite its simplicity compared to transformer, the concept of channel-mixing MLPs and token-mixing MLPs achieves noticeable performance in visual recognition tasks. Unlike images, point clouds are inherently sparse, unordered and irregular, which limits the direct use of MLP-Mixer for point cloud understanding. In this paper, we propose PointMixer, a universal point set operator that facilitates information sharing among unstructured 3D points. By simply replacing token-mixing MLPs with a softmax function, PointMixer can "mix" features within/between point sets. By doing so, PointMixer can be broadly used in the network as inter-set mixing, intra-set mixing, and pyramid mixing. Extensive experiments show the competitive or superior performance of PointMixer in semantic segmentation, classification, and point reconstruction against transformer-based methods.