 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGOS: Who, Where, and When in Agentic Multi-Camera Person Search
Apr 14, 2026We introduce ARGOS, the first benchmark and framework that reformulates multi-camera person search as an interactive reasoning problem requiring an agent to plan, question, and eliminate candidates under information asymmetry. An ARGOS agent receives a vague witness statement and must decide what to ask, when to invoke spatial or temporal tools, and how to interpret ambiguous responses, all within a limited turn budget. Reasoning is grounded in a Spatio-Temporal Topology Graph (STTG) encoding camera connectivity and empirically validated transition times. The benchmark comprises 2,691 tasks across 14 real-world scenarios in three progressive tracks: semantic perception (Who), spatial reasoning (Where), and temporal reasoning (When). Experiments with four LLM backbones show the benchmark is far from solved (best TWS: 0.383 on Track 2, 0.590 on Track 3), and ablations confirm that removing domain-specific tools drops accuracy by up to 49.6 percentage points.
GeoNVS: Geometry Grounded Video Diffusion for Novel View Synthesis
Mar 16, 2026Novel view synthesis requires strong 3D geometric consistency and the ability to generate visually coherent images across diverse viewpoints. While recent camera-controlled video diffusion models show promising results, they often suffer from geometric distortions and limited camera controllability. To overcome these challenges, we introduce GeoNVS, a geometry-grounded novel-view synthesizer that enhances both geometric fidelity and camera controllability through explicit 3D geometric guidance. Our key innovation is the Gaussian Splat Feature Adapter (GS-Adapter), which lifts input-view diffusion features into 3D Gaussian representations, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features to correct geometrically inconsistent representations. Unlike prior methods that inject geometry at the input level, GS-Adapter operates in feature space, avoiding view-dependent color noise that degrades structural consistency. Its plug-and-play design enables zero-shot compatibility with diverse feed-forward geometry models without additional training, and can be adapted to other video diffusion backbones. Experiments across 9 scenes and 18 settings demonstrate state-of-the-art performance, achieving 11.3% and 14.9% improvements over SEVA and CameraCtrl, with up to 2x reduction in translation error and 7x in Chamfer Distance.
Any6D: Model-free 6D Pose Estimation of Novel Objects
Mar 25, 2025We introduce Any6D, a model-free framework for 6D object pose estimation that requires only a single RGB-D anchor image to estimate both the 6D pose and size of unknown objects in novel scenes. Unlike existing methods that rely on textured 3D models or multiple viewpoints, Any6D leverages a joint object alignment process to enhance 2D-3D alignment and metric scale estimation for improved pose accuracy. Our approach integrates a render-and-compare strategy to generate and refine pose hypotheses, enabling robust performance in scenarios with occlusions, non-overlapping views, diverse lighting conditions, and large cross-environment variations. We evaluate our method on five challenging datasets: REAL275, Toyota-Light, HO3D, YCBINEOAT, and LM-O, demonstrating its effectiveness in significantly outperforming state-of-the-art methods for novel object pose estimation. Project page: https://taeyeop.com/any6d
Preserving Multi-Modal Capabilities of Pre-trained VLMs for Improving Vision-Linguistic Compositionality
Oct 07, 2024



In this paper, we propose a new method to enhance compositional understanding in pre-trained vision and language models (VLMs) without sacrificing performance in zero-shot multi-modal tasks. Traditional fine-tuning approaches often improve compositional reasoning at the cost of degrading multi-modal capabilities, primarily due to the use of global hard negative (HN) loss, which contrasts global representations of images and texts. This global HN loss pushes HN texts that are highly similar to the original ones, damaging the model's multi-modal representations. To overcome this limitation, we propose Fine-grained Selective Calibrated CLIP (FSC-CLIP), which integrates local hard negative loss and selective calibrated regularization. These innovations provide fine-grained negative supervision while preserving the model's representational integrity. Our extensive evaluations across diverse benchmarks for both compositionality and multi-modal tasks show that FSC-CLIP not only achieves compositionality on par with state-of-the-art models but also retains strong multi-modal capabilities. Code is available at: https://github.com/ytaek-oh/fsc-clip.
360 in the Wild: Dataset for Depth Prediction and View Synthesis
Jun 27, 2024



The large abundance of perspective camera datasets facilitated the emergence of novel learning-based strategies for various tasks, such as camera localization, single image depth estimation, or view synthesis. However, panoramic or omnidirectional image datasets, including essential information, such as pose and depth, are mostly made with synthetic scenes. In this work, we introduce a large scale 360$^{\circ}$ videos dataset in the wild. This dataset has been carefully scraped from the Internet and has been captured from various locations worldwide. Hence, this dataset exhibits very diversified environments (e.g., indoor and outdoor) and contexts (e.g., with and without moving objects). Each of the 25K images constituting our dataset is provided with its respective camera's pose and depth map. We illustrate the relevance of our dataset for two main tasks, namely, single image depth estimation and view synthesis.
Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Jun 13, 2024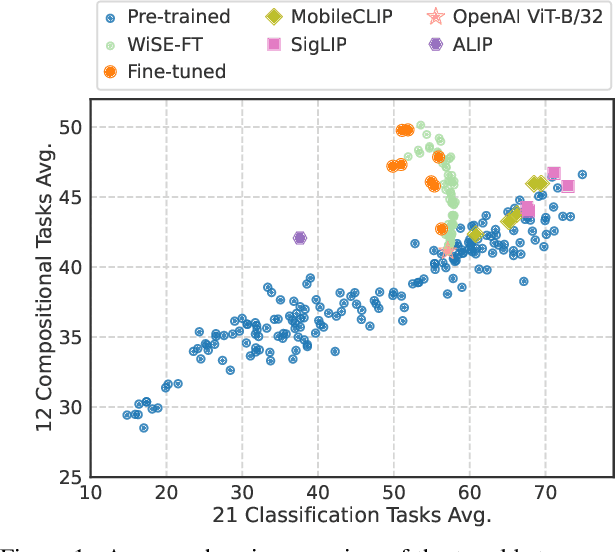
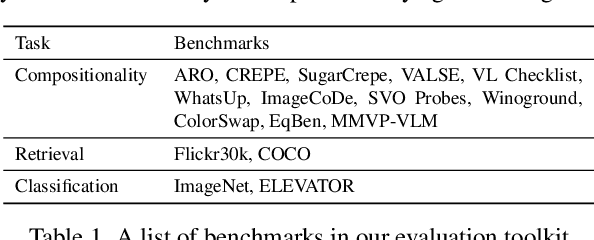
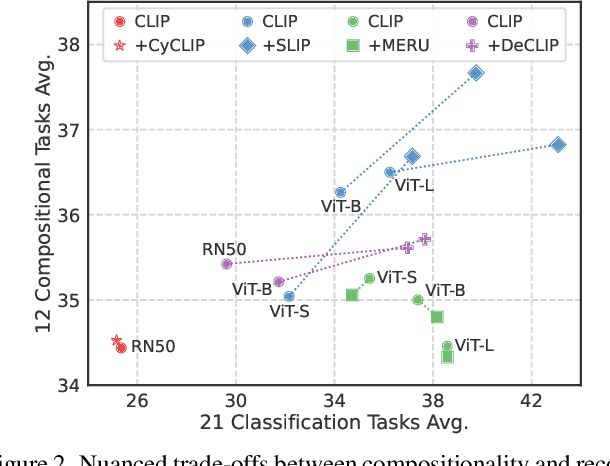
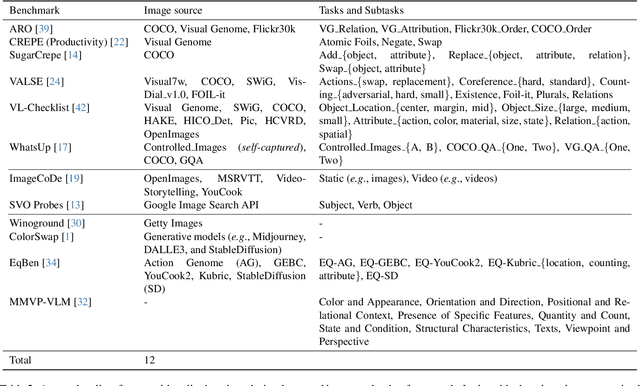
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Jun 04, 2024



Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
Stable Surface Regularization for Fast Few-Shot NeRF
Mar 29, 2024This paper proposes an algorithm for synthesizing novel views under few-shot setup. The main concept is to develop a stable surface regularization technique called Annealing Signed Distance Function (ASDF), which anneals the surface in a coarse-to-fine manner to accelerate convergence speed. We observe that the Eikonal loss - which is a widely known geometric regularization - requires dense training signal to shape different level-sets of SDF, leading to low-fidelity results under few-shot training. In contrast, the proposed surface regularization successfully reconstructs scenes and produce high-fidelity geometry with stable training. Our method is further accelerated by utilizing grid representation and monocular geometric priors. Finally, the proposed approach is up to 45 times faster than existing few-shot novel view synthesis methods, and it produces comparable results in the ScanNet dataset and NeRF-Real dataset.
Towards Understanding Dual BN In Hybrid Adversarial Training
Mar 28, 2024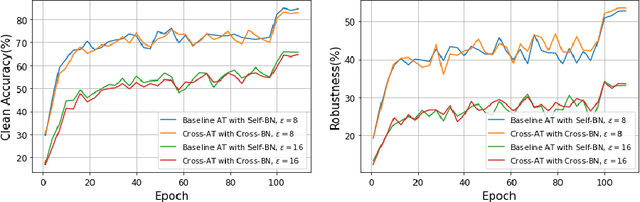


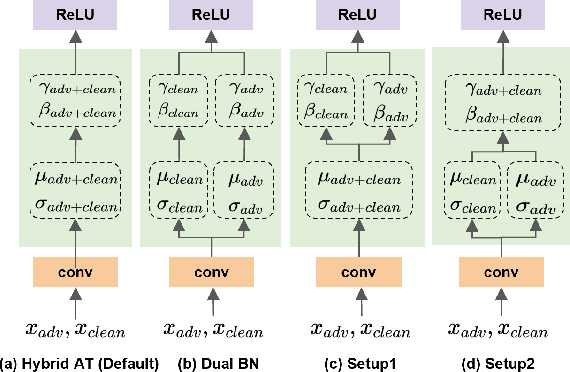
There is a growing concern about applying batch normalization (BN) in adversarial training (AT), especially when the model is trained on both adversarial samples and clean samples (termed Hybrid-AT). With the assumption that adversarial and clean samples are from two different domains, a common practice in prior works is to adopt Dual BN, where BN and BN are used for adversarial and clean branches, respectively. A popular belief for motivating Dual BN is that estimating normalization statistics of this mixture distribution is challenging and thus disentangling it for normalization achieves stronger robustness. In contrast to this belief, we reveal that disentangling statistics plays a less role than disentangling affine parameters in model training. This finding aligns with prior work (Rebuffi et al., 2023), and we build upon their research for further investigations. We demonstrate that the domain gap between adversarial and clean samples is not very large, which is counter-intuitive considering the significant influence of adversarial perturbation on the model accuracy. We further propose a two-task hypothesis which serves as the empirical foundation and a unified framework for Hybrid-AT improvement. We also investigate Dual BN in test-time and reveal that affine parameters characterize the robustness during inference. Overall, our work sheds new light on understanding the mechanism of Dual BN in Hybrid-AT and its underlying justification.