 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Mixture-of-Experts Specialization via Cluster-Aware Upcycling
Apr 15, 2026Sparse Upcycling provides an efficient way to initialize a Mixture-of-Experts (MoE) model from pretrained dense weights instead of training from scratch. However, since all experts start from identical weights and the router is randomly initialized, the model suffers from expert symmetry and limited early specialization. We propose Cluster-aware Upcycling, a strategy that incorporates semantic structure into MoE initialization. Our method first partitions the dense model's input activations into semantic clusters. Each expert is then initialized using the subspace representations of its corresponding cluster via truncated SVD, while setting the router's initial weights to the cluster centroids. This cluster-aware initialization breaks expert symmetry and encourages early specialization aligned with the data distribution. Furthermore, we introduce an expert-ensemble self-distillation loss that stabilizes training by providing reliable routing guidance using an ensemble teacher. When evaluated on CLIP ViT-B/32 and ViT-B/16, Cluster-aware Upcycling consistently outperforms existing methods across both zero-shot and few-shot benchmarks. The proposed method also produces more diverse and disentangled expert representations, reduces inter-expert similarity, and leads to more confident routing behavior.
Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Jun 13, 2024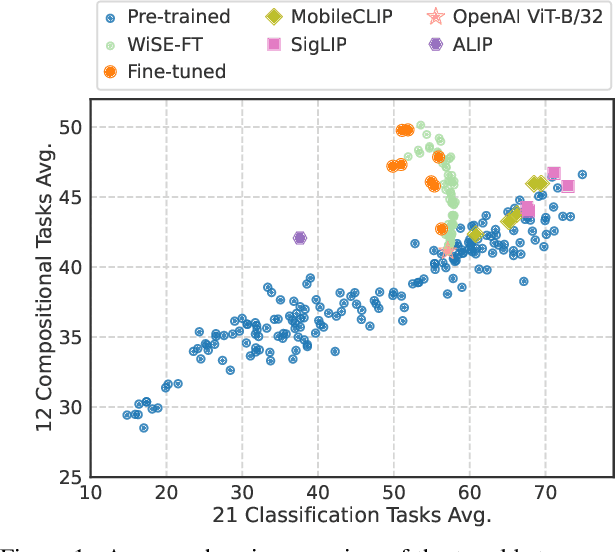
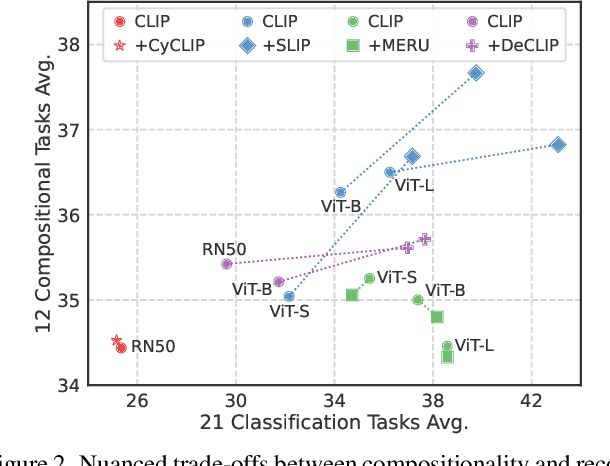
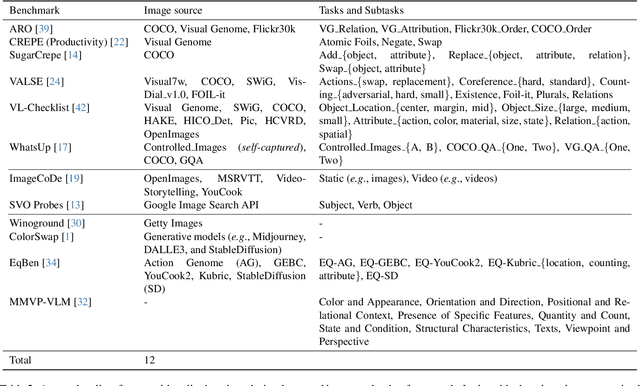
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
ContextMix: A context-aware data augmentation method for industrial visual inspection systems
Jan 18, 2024



While deep neural networks have achieved remarkable performance, data augmentation has emerged as a crucial strategy to mitigate overfitting and enhance network performance. These techniques hold particular significance in industrial manufacturing contexts. Recently, image mixing-based methods have been introduced, exhibiting improved performance on public benchmark datasets. However, their application to industrial tasks remains challenging. The manufacturing environment generates massive amounts of unlabeled data on a daily basis, with only a few instances of abnormal data occurrences. This leads to severe data imbalance. Thus, creating well-balanced datasets is not straightforward due to the high costs associated with labeling. Nonetheless, this is a crucial step for enhancing productivity. For this reason, we introduce ContextMix, a method tailored for industrial applications and benchmark datasets. ContextMix generates novel data by resizing entire images and integrating them into other images within the batch. This approach enables our method to learn discriminative features based on varying sizes from resized images and train informative secondary features for object recognition using occluded images. With the minimal additional computation cost of image resizing, ContextMix enhances performance compared to existing augmentation techniques. We evaluate its effectiveness across classification, detection, and segmentation tasks using various network architectures on public benchmark datasets. Our proposed method demonstrates improved results across a range of robustness tasks. Its efficacy in real industrial environments is particularly noteworthy, as demonstrated using the passive component dataset.
NICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Large-Scale Bidirectional Training for Zero-Shot Image Captioning
Nov 15, 2022
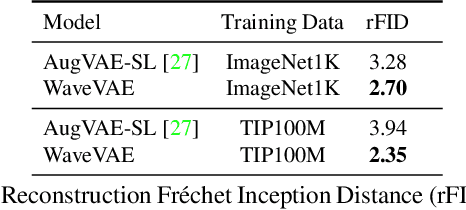
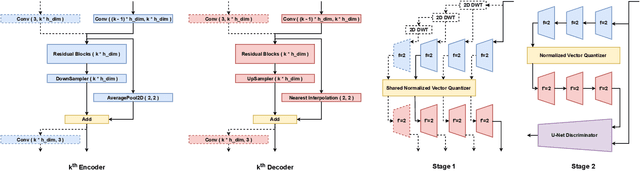
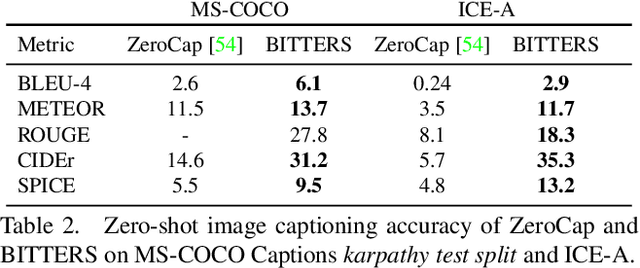
When trained on large-scale datasets, image captioning models can understand the content of images from a general domain but often fail to generate accurate, detailed captions. To improve performance, pretraining-and-finetuning has been a key strategy for image captioning. However, we find that large-scale bidirectional training between image and text enables zero-shot image captioning. In this paper, we introduce Bidirectional Image Text Training in largER Scale, BITTERS, an efficient training and inference framework for zero-shot image captioning. We also propose a new evaluation benchmark which comprises of high quality datasets and an extensive set of metrics to properly evaluate zero-shot captioning accuracy and societal bias. We additionally provide an efficient finetuning approach for keyword extraction. We show that careful selection of large-scale training set and model architecture is the key to achieving zero-shot image captioning.
Projection-based Point Convolution for Efficient Point Cloud Segmentation
Feb 04, 2022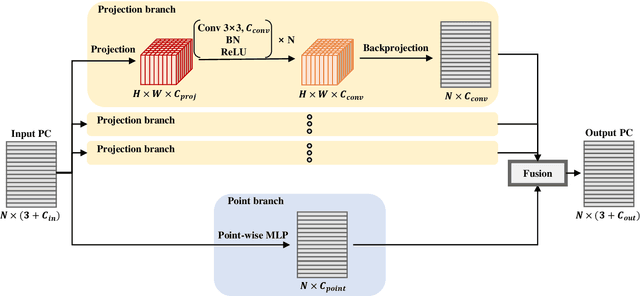
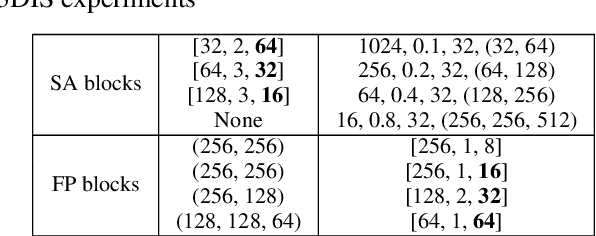
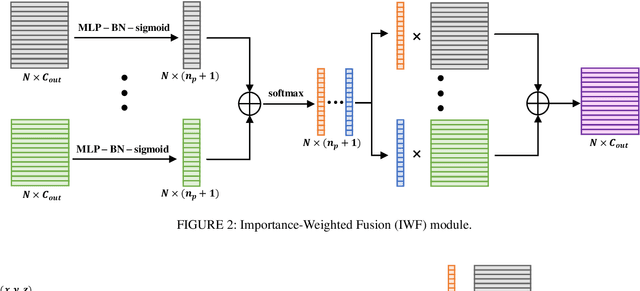
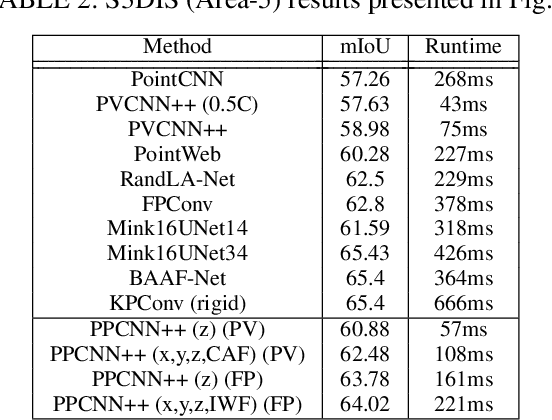
Understanding point cloud has recently gained huge interests following the development of 3D scanning devices and the accumulation of large-scale 3D data. Most point cloud processing algorithms can be classified as either point-based or voxel-based methods, both of which have severe limitations in processing time or memory, or both. To overcome these limitations, we propose Projection-based Point Convolution (PPConv), a point convolutional module that uses 2D convolutions and multi-layer perceptrons (MLPs) as its components. In PPConv, point features are processed through two branches: point branch and projection branch. Point branch consists of MLPs, while projection branch transforms point features into a 2D feature map and then apply 2D convolutions. As PPConv does not use point-based or voxel-based convolutions, it has advantages in fast point cloud processing. When combined with a learnable projection and effective feature fusion strategy, PPConv achieves superior efficiency compared to state-of-the-art methods, even with a simple architecture based on PointNet++. We demonstrate the efficiency of PPConv in terms of the trade-off between inference time and segmentation performance. The experimental results on S3DIS and ShapeNetPart show that PPConv is the most efficient method among the compared ones. The code is available at github.com/pahn04/PPConv.
Progressive Seed Generation Auto-encoder for Unsupervised Point Cloud Learning
Dec 09, 2021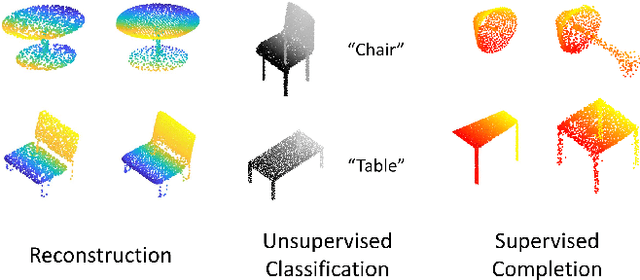
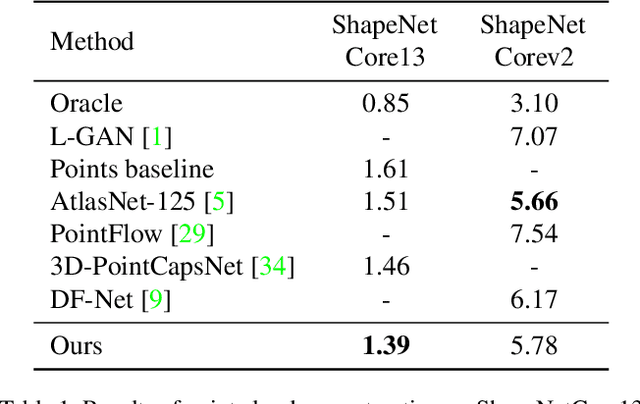
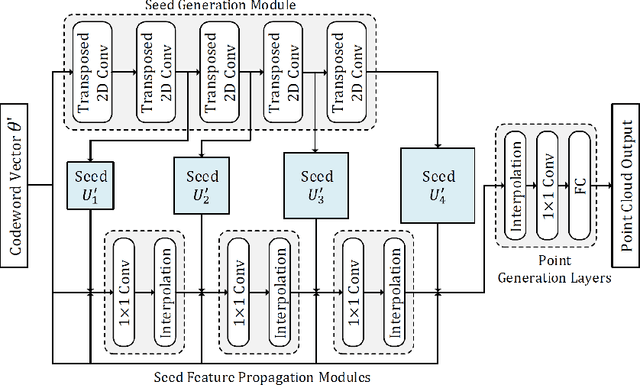
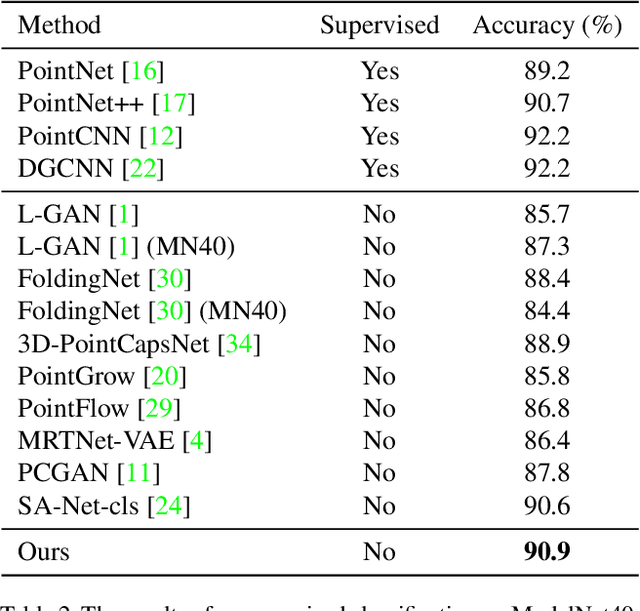
With the development of 3D scanning technologies, 3D vision tasks have become a popular research area. Owing to the large amount of data acquired by sensors, unsupervised learning is essential for understanding and utilizing point clouds without an expensive annotation process. In this paper, we propose a novel framework and an effective auto-encoder architecture named "PSG-Net" for reconstruction-based learning of point clouds. Unlike existing studies that used fixed or random 2D points, our framework generates input-dependent point-wise features for the latent point set. PSG-Net uses the encoded input to produce point-wise features through the seed generation module and extracts richer features in multiple stages with gradually increasing resolution by applying the seed feature propagation module progressively. We prove the effectiveness of PSG-Net experimentally; PSG-Net shows state-of-the-art performances in point cloud reconstruction and unsupervised classification, and achieves comparable performance to counterpart methods in supervised completion.
PBP-Net: Point Projection and Back-Projection Network for 3D Point Cloud Segmentation
Nov 02, 2020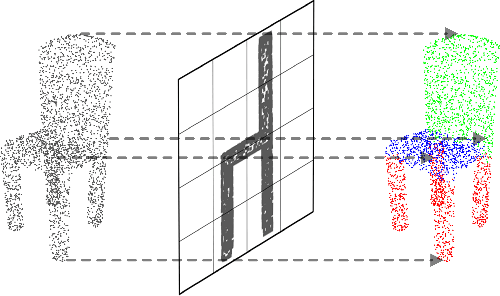
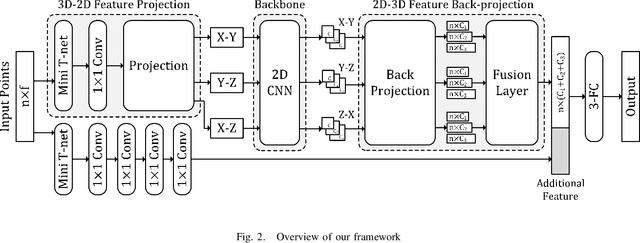
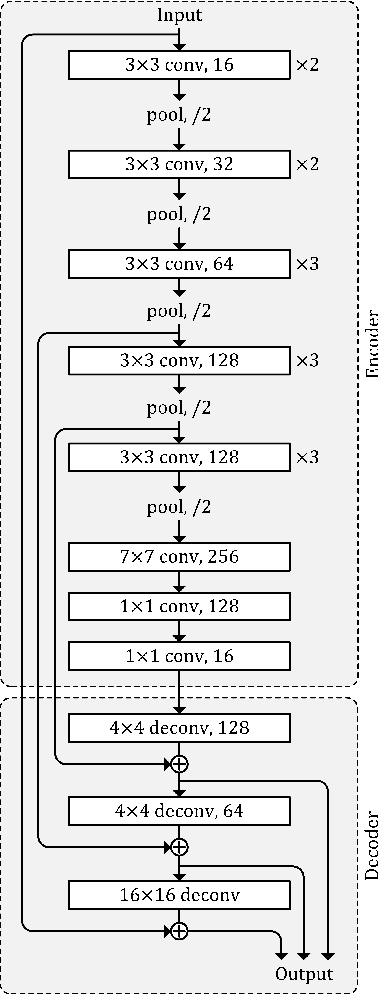

Following considerable development in 3D scanning technologies, many studies have recently been proposed with various approaches for 3D vision tasks, including some methods that utilize 2D convolutional neural networks (CNNs). However, even though 2D CNNs have achieved high performance in many 2D vision tasks, existing works have not effectively applied them onto 3D vision tasks. In particular, segmentation has not been well studied because of the difficulty of dense prediction for each point, which requires rich feature representation. In this paper, we propose a simple and efficient architecture named point projection and back-projection network (PBP-Net), which leverages 2D CNNs for the 3D point cloud segmentation. 3 modules are introduced, each of which projects 3D point cloud onto 2D planes, extracts features using a 2D CNN backbone, and back-projects features onto the original 3D point cloud. To demonstrate effective 3D feature extraction using 2D CNN, we perform various experiments including comparison to recent methods. We analyze the proposed modules through ablation studies and perform experiments on object part segmentation (ShapeNet-Part dataset) and indoor scene semantic segmentation (S3DIS dataset). The experimental results show that proposed PBP-Net achieves comparable performance to existing state-of-the-art methods.
EDAS: Efficient and Differentiable Architecture Search
Dec 04, 2019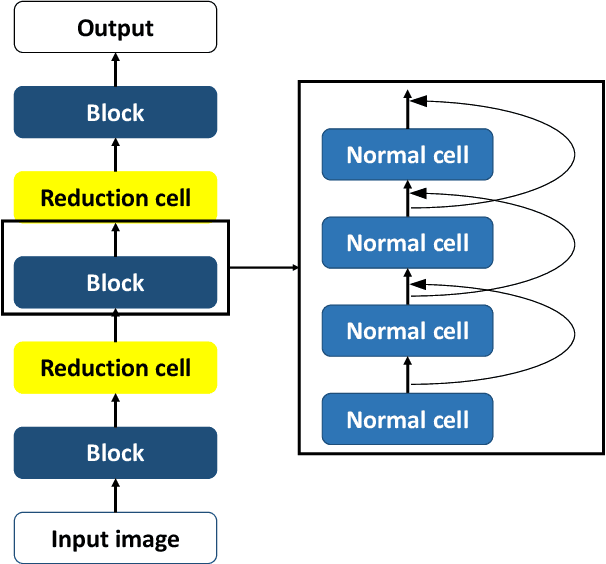

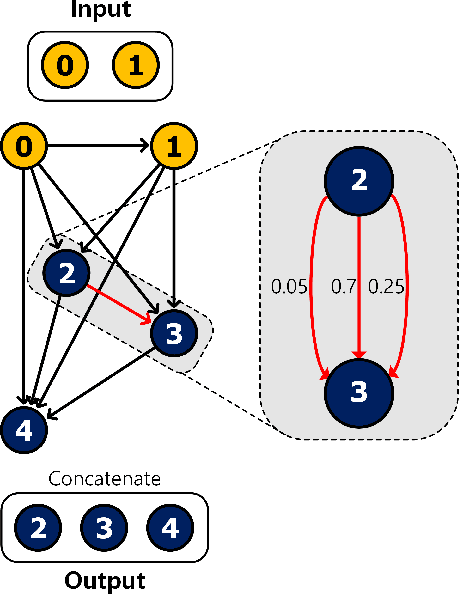
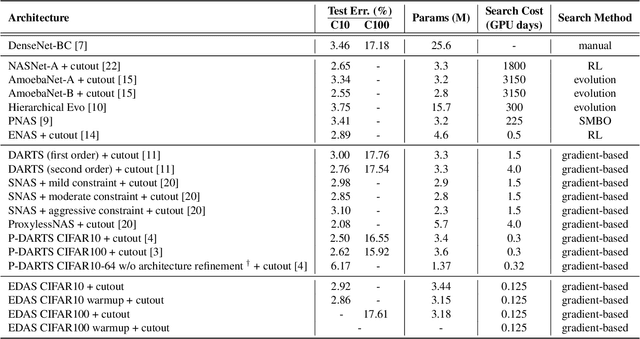
Transferrable neural architecture search can be viewed as a binary optimization problem where a single optimal path should be selected among candidate paths in each edge within the repeated cell block of the directed a cyclic graph form. Recently, the field of differentiable architecture search attempts to relax the search problem continuously using a one-shot network that combines all the candidate paths in search space. However, when the one-shot network is pruned to the model in the discrete architecture space by the derivation algorithm, performance is significantly degraded to an almost random estimator. To reduce the quantization error from the heavy use of relaxation, we only sample a single edge to relax the corresponding variable and clamp variables in the other edges to zero or one. By this method, there is no performance drop after pruning the one-shot network by derivation algorithm, due to the preservation of the discrete nature of optimization variables during the search. Furthermore, the minimization of relaxation degree allows searching in a deeper network to discover better performance with remarkable search cost reduction (0.125 GPU days) compared to previous methods. By adding several regularization methods that help explore within the search space, we could obtain the network with notable performances on CIFAR-10, CIFAR-100, and ImageNet.