 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisposable Transfer Learning for Selective Source Task Unlearning
Aug 19, 2023Transfer learning is widely used for training deep neural networks (DNN) for building a powerful representation. Even after the pre-trained model is adapted for the target task, the representation performance of the feature extractor is retained to some extent. As the performance of the pre-trained model can be considered the private property of the owner, it is natural to seek the exclusive right of the generalized performance of the pre-trained weight. To address this issue, we suggest a new paradigm of transfer learning called disposable transfer learning (DTL), which disposes of only the source task without degrading the performance of the target task. To achieve knowledge disposal, we propose a novel loss named Gradient Collision loss (GC loss). GC loss selectively unlearns the source knowledge by leading the gradient vectors of mini-batches in different directions. Whether the model successfully unlearns the source task is measured by piggyback learning accuracy (PL accuracy). PL accuracy estimates the vulnerability of knowledge leakage by retraining the scrubbed model on a subset of source data or new downstream data. We demonstrate that GC loss is an effective approach to the DTL problem by showing that the model trained with GC loss retains the performance on the target task with a significantly reduced PL accuracy.
Localization using Multi-Focal Spatial Attention for Masked Face Recognition
May 03, 2023
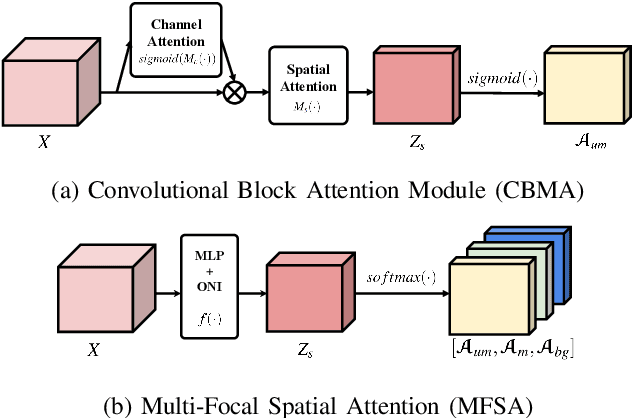
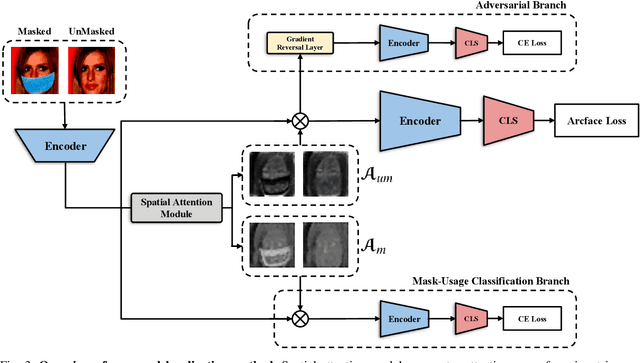
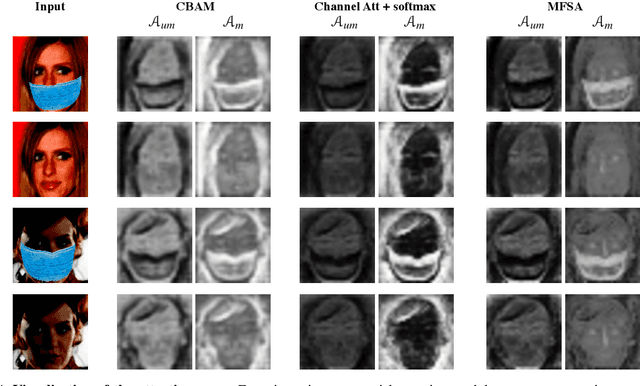
Since the beginning of world-wide COVID-19 pandemic, facial masks have been recommended to limit the spread of the disease. However, these masks hide certain facial attributes. Hence, it has become difficult for existing face recognition systems to perform identity verification on masked faces. In this context, it is necessary to develop masked Face Recognition (MFR) for contactless biometric recognition systems. Thus, in this paper, we propose Complementary Attention Learning and Multi-Focal Spatial Attention that precisely removes masked region by training complementary spatial attention to focus on two distinct regions: masked regions and backgrounds. In our method, standard spatial attention and networks focus on unmasked regions, and extract mask-invariant features while minimizing the loss of the conventional Face Recognition (FR) performance. For conventional FR, we evaluate the performance on the IJB-C, Age-DB, CALFW, and CPLFW datasets. We evaluate the MFR performance on the ICCV2021-MFR/Insightface track, and demonstrate the improved performance on the both MFR and FR datasets. Additionally, we empirically verify that spatial attention of proposed method is more precisely activated in unmasked regions.
Training Time Adversarial Attack Aiming the Vulnerability of Continual Learning
Nov 29, 2022



Generally, regularization-based continual learning models limit access to the previous task data to imitate the real-world setting which has memory and privacy issues. However, this introduces a problem in these models by not being able to track the performance on each task. In other words, current continual learning methods are vulnerable to attacks done on the previous task. We demonstrate the vulnerability of regularization-based continual learning methods by presenting simple task-specific training time adversarial attack that can be used in the learning process of a new task. Training data generated by the proposed attack causes performance degradation on a specific task targeted by the attacker. Experiment results justify the vulnerability proposed in this paper and demonstrate the importance of developing continual learning models that are robust to adversarial attack.
Rethinking Efficacy of Softmax for Lightweight Non-Local Neural Networks
Jul 27, 2022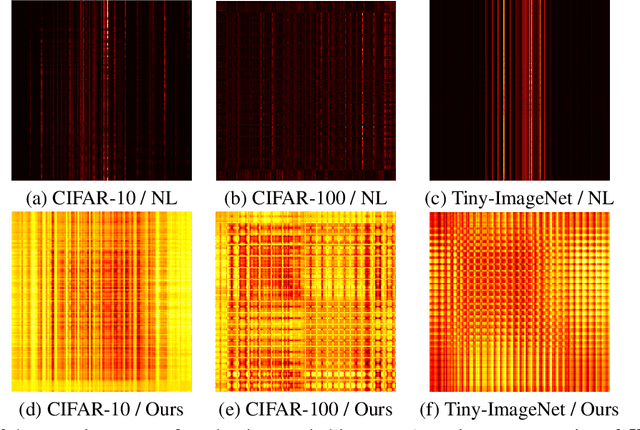
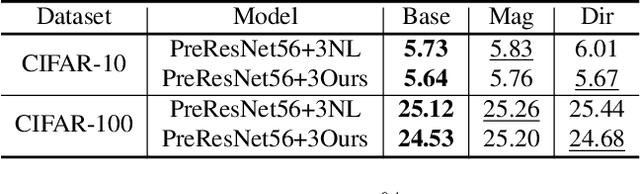
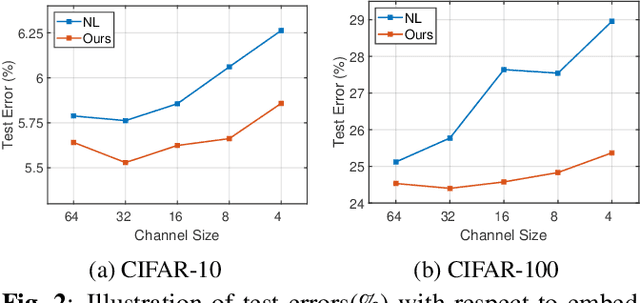
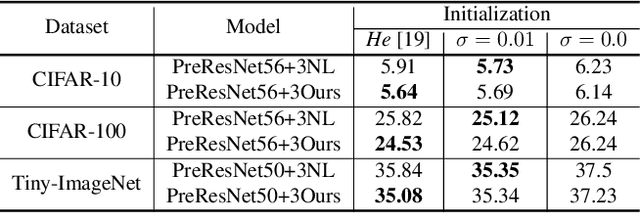
Non-local (NL) block is a popular module that demonstrates the capability to model global contexts. However, NL block generally has heavy computation and memory costs, so it is impractical to apply the block to high-resolution feature maps. In this paper, to investigate the efficacy of NL block, we empirically analyze if the magnitude and direction of input feature vectors properly affect the attention between vectors. The results show the inefficacy of softmax operation which is generally used to normalize the attention map of the NL block. Attention maps normalized with softmax operation highly rely upon magnitude of key vectors, and performance is degenerated if the magnitude information is removed. By replacing softmax operation with the scaling factor, we demonstrate improved performance on CIFAR-10, CIFAR-100, and Tiny-ImageNet. In Addition, our method shows robustness to embedding channel reduction and embedding weight initialization. Notably, our method makes multi-head attention employable without additional computational cost.
Continual Learning with Extended Kronecker-factored Approximate Curvature
Apr 16, 2020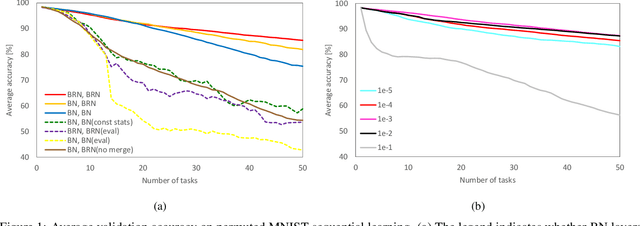
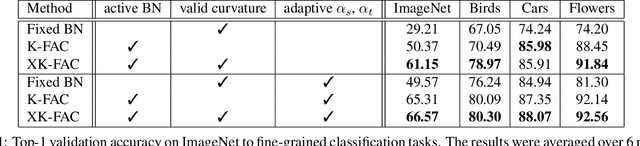
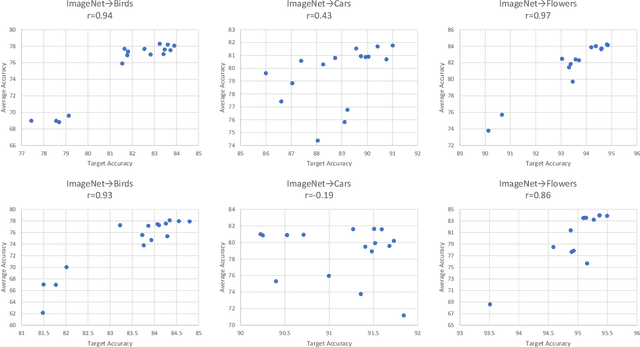
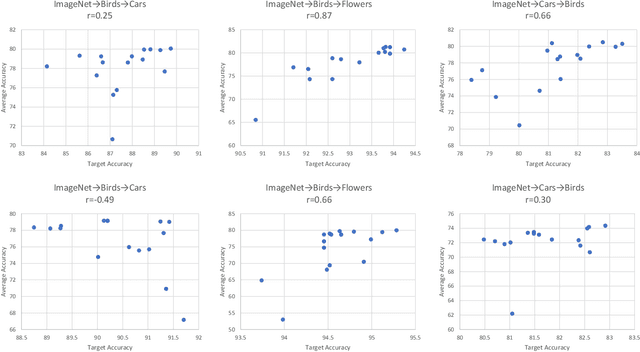
We propose a quadratic penalty method for continual learning of neural networks that contain batch normalization (BN) layers. The Hessian of a loss function represents the curvature of the quadratic penalty function, and a Kronecker-factored approximate curvature (K-FAC) is used widely to practically compute the Hessian of a neural network. However, the approximation is not valid if there is dependence between examples, typically caused by BN layers in deep network architectures. We extend the K-FAC method so that the inter-example relations are taken into account and the Hessian of deep neural networks can be properly approximated under practical assumptions. We also propose a method of weight merging and reparameterization to properly handle statistical parameters of BN, which plays a critical role for continual learning with BN, and a method that selects hyperparameters without source task data. Our method shows better performance than baselines in the permuted MNIST task with BN layers and in sequential learning from the ImageNet classification task to fine-grained classification tasks with ResNet-50, without any explicit or implicit use of source task data for hyperparameter selection.
Residual Continual Learning
Feb 17, 2020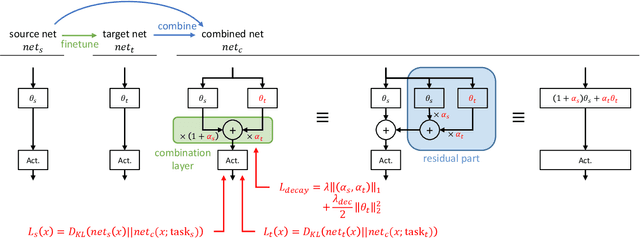

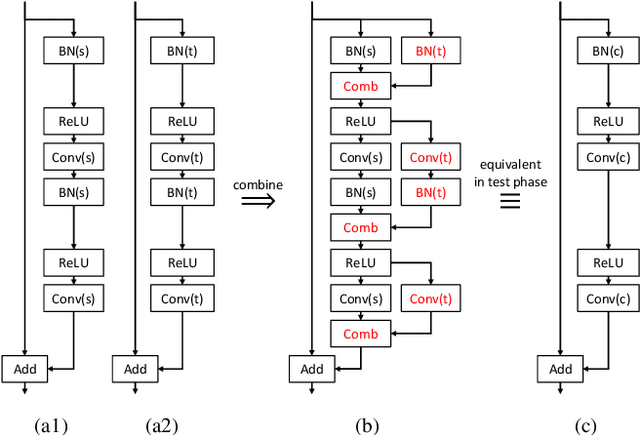

We propose a novel continual learning method called Residual Continual Learning (ResCL). Our method can prevent the catastrophic forgetting phenomenon in sequential learning of multiple tasks, without any source task information except the original network. ResCL reparameterizes network parameters by linearly combining each layer of the original network and a fine-tuned network; therefore, the size of the network does not increase at all. To apply the proposed method to general convolutional neural networks, the effects of batch normalization layers are also considered. By utilizing residual-learning-like reparameterization and a special weight decay loss, the trade-off between source and target performance is effectively controlled. The proposed method exhibits state-of-the-art performance in various continual learning scenarios.
EDAS: Efficient and Differentiable Architecture Search
Dec 04, 2019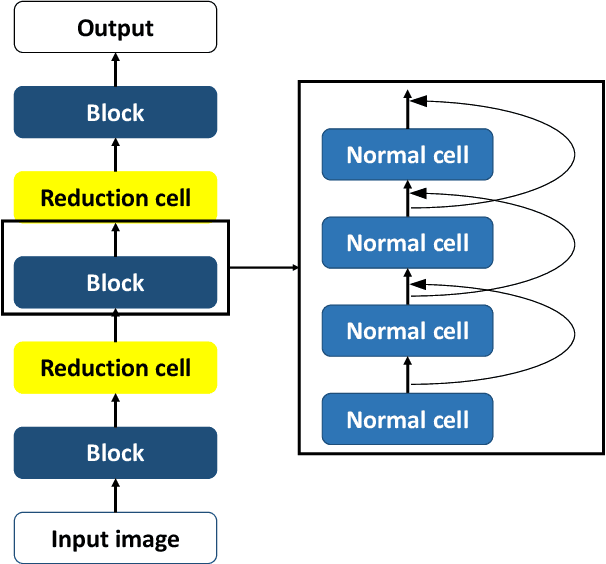

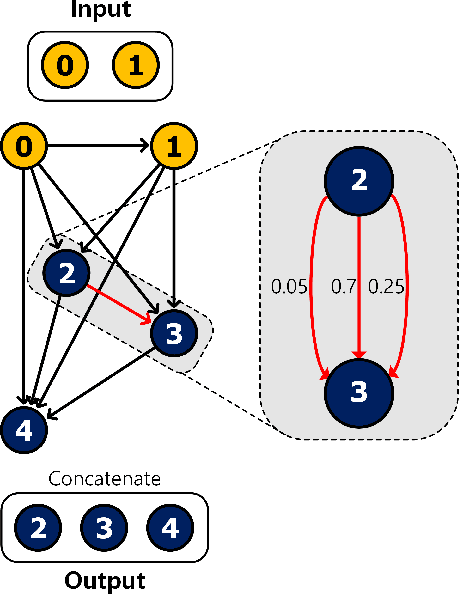
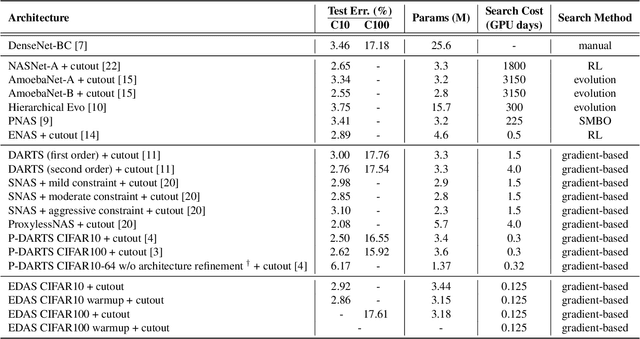
Transferrable neural architecture search can be viewed as a binary optimization problem where a single optimal path should be selected among candidate paths in each edge within the repeated cell block of the directed a cyclic graph form. Recently, the field of differentiable architecture search attempts to relax the search problem continuously using a one-shot network that combines all the candidate paths in search space. However, when the one-shot network is pruned to the model in the discrete architecture space by the derivation algorithm, performance is significantly degraded to an almost random estimator. To reduce the quantization error from the heavy use of relaxation, we only sample a single edge to relax the corresponding variable and clamp variables in the other edges to zero or one. By this method, there is no performance drop after pruning the one-shot network by derivation algorithm, due to the preservation of the discrete nature of optimization variables during the search. Furthermore, the minimization of relaxation degree allows searching in a deeper network to discover better performance with remarkable search cost reduction (0.125 GPU days) compared to previous methods. By adding several regularization methods that help explore within the search space, we could obtain the network with notable performances on CIFAR-10, CIFAR-100, and ImageNet.