 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFLD: Reducing the content bias for AI-generated Image Detection
Feb 24, 2025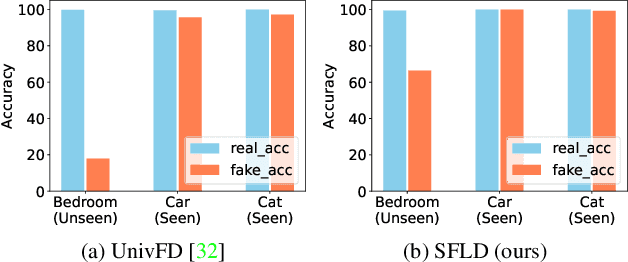
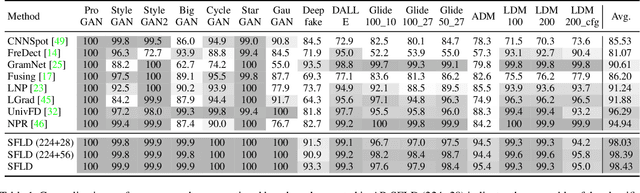

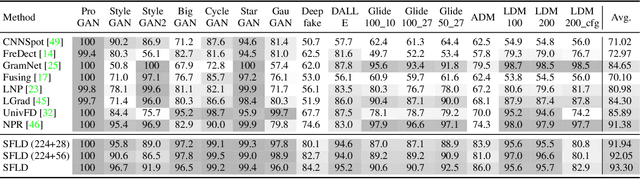
Identifying AI-generated content is critical for the safe and ethical use of generative AI. Recent research has focused on developing detectors that generalize to unknown generators, with popular methods relying either on high-level features or low-level fingerprints. However, these methods have clear limitations: biased towards unseen content, or vulnerable to common image degradations, such as JPEG compression. To address these issues, we propose a novel approach, SFLD, which incorporates PatchShuffle to integrate high-level semantic and low-level textural information. SFLD applies PatchShuffle at multiple levels, improving robustness and generalization across various generative models. Additionally, current benchmarks face challenges such as low image quality, insufficient content preservation, and limited class diversity. In response, we introduce TwinSynths, a new benchmark generation methodology that constructs visually near-identical pairs of real and synthetic images to ensure high quality and content preservation. Our extensive experiments and analysis show that SFLD outperforms existing methods on detecting a wide variety of fake images sourced from GANs, diffusion models, and TwinSynths, demonstrating the state-of-the-art performance and generalization capabilities to novel generative models.
FRED: Towards a Full Rotation-Equivariance in Aerial Image Object Detection
Dec 22, 2023Rotation-equivariance is an essential yet challenging property in oriented object detection. While general object detectors naturally leverage robustness to spatial shifts due to the translation-equivariance of the conventional CNNs, achieving rotation-equivariance remains an elusive goal. Current detectors deploy various alignment techniques to derive rotation-invariant features, but still rely on high capacity models and heavy data augmentation with all possible rotations. In this paper, we introduce a Fully Rotation-Equivariant Oriented Object Detector (FRED), whose entire process from the image to the bounding box prediction is strictly equivariant. Specifically, we decouple the invariant task (object classification) and the equivariant task (object localization) to achieve end-to-end equivariance. We represent the bounding box as a set of rotation-equivariant vectors to implement rotation-equivariant localization. Moreover, we utilized these rotation-equivariant vectors as offsets in the deformable convolution, thereby enhancing the existing advantages of spatial adaptation. Leveraging full rotation-equivariance, our FRED demonstrates higher robustness to image-level rotation compared to existing methods. Furthermore, we show that FRED is one step closer to non-axis aligned learning through our experiments. Compared to state-of-the-art methods, our proposed method delivers comparable performance on DOTA-v1.0 and outperforms by 1.5 mAP on DOTA-v1.5, all while significantly reducing the model parameters to 16%.
Disposable Transfer Learning for Selective Source Task Unlearning
Aug 19, 2023Transfer learning is widely used for training deep neural networks (DNN) for building a powerful representation. Even after the pre-trained model is adapted for the target task, the representation performance of the feature extractor is retained to some extent. As the performance of the pre-trained model can be considered the private property of the owner, it is natural to seek the exclusive right of the generalized performance of the pre-trained weight. To address this issue, we suggest a new paradigm of transfer learning called disposable transfer learning (DTL), which disposes of only the source task without degrading the performance of the target task. To achieve knowledge disposal, we propose a novel loss named Gradient Collision loss (GC loss). GC loss selectively unlearns the source knowledge by leading the gradient vectors of mini-batches in different directions. Whether the model successfully unlearns the source task is measured by piggyback learning accuracy (PL accuracy). PL accuracy estimates the vulnerability of knowledge leakage by retraining the scrubbed model on a subset of source data or new downstream data. We demonstrate that GC loss is an effective approach to the DTL problem by showing that the model trained with GC loss retains the performance on the target task with a significantly reduced PL accuracy.
Lightweight Monocular Depth Estimation via Token-Sharing Transformer
Jun 09, 2023Depth estimation is an important task in various robotics systems and applications. In mobile robotics systems, monocular depth estimation is desirable since a single RGB camera can be deployable at a low cost and compact size. Due to its significant and growing needs, many lightweight monocular depth estimation networks have been proposed for mobile robotics systems. While most lightweight monocular depth estimation methods have been developed using convolution neural networks, the Transformer has been gradually utilized in monocular depth estimation recently. However, massive parameters and large computational costs in the Transformer disturb the deployment to embedded devices. In this paper, we present a Token-Sharing Transformer (TST), an architecture using the Transformer for monocular depth estimation, optimized especially in embedded devices. The proposed TST utilizes global token sharing, which enables the model to obtain an accurate depth prediction with high throughput in embedded devices. Experimental results show that TST outperforms the existing lightweight monocular depth estimation methods. On the NYU Depth v2 dataset, TST can deliver depth maps up to 63.4 FPS in NVIDIA Jetson nano and 142.6 FPS in NVIDIA Jetson TX2, with lower errors than the existing methods. Furthermore, TST achieves real-time depth estimation of high-resolution images on Jetson TX2 with competitive results.
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022
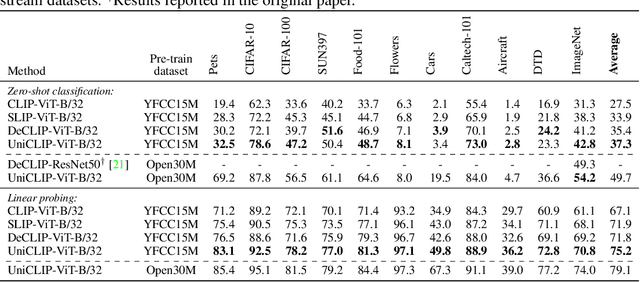
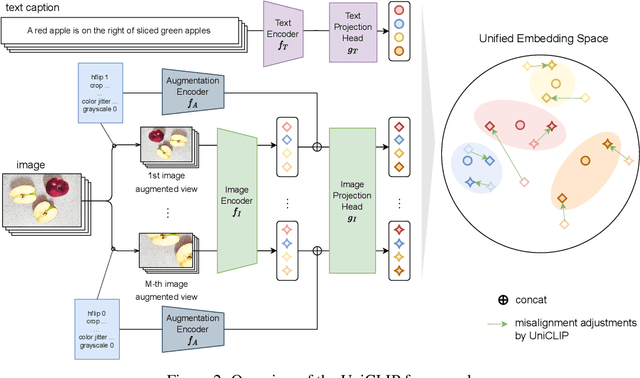
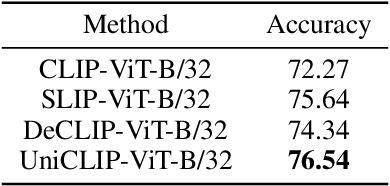
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
DLCFT: Deep Linear Continual Fine-Tuning for General Incremental Learning
Aug 17, 2022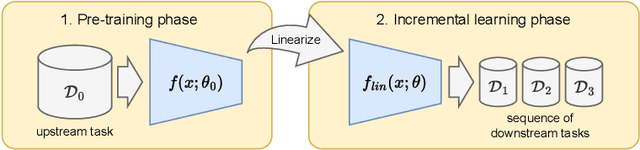
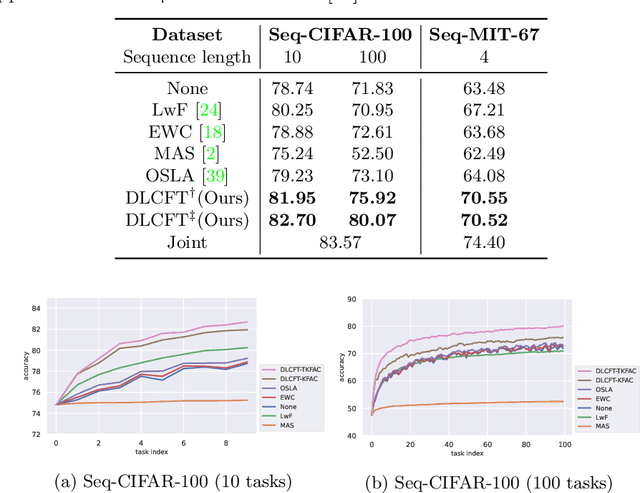
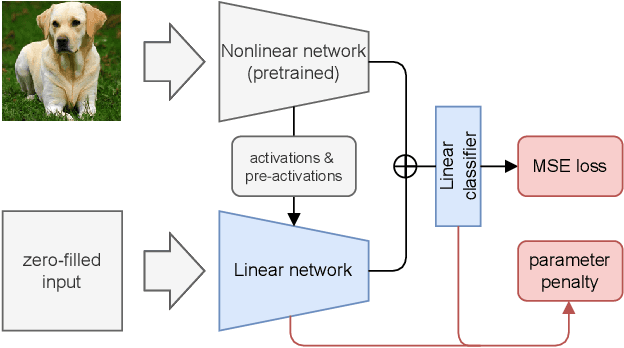
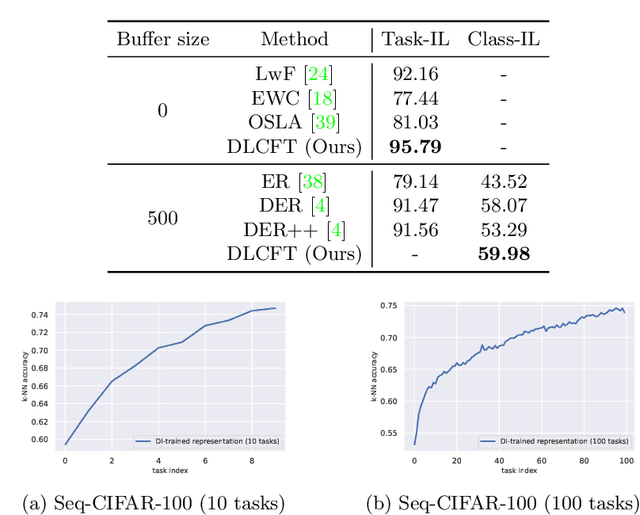
Pre-trained representation is one of the key elements in the success of modern deep learning. However, existing works on continual learning methods have mostly focused on learning models incrementally from scratch. In this paper, we explore an alternative framework to incremental learning where we continually fine-tune the model from a pre-trained representation. Our method takes advantage of linearization technique of a pre-trained neural network for simple and effective continual learning. We show that this allows us to design a linear model where quadratic parameter regularization method is placed as the optimal continual learning policy, and at the same time enjoying the high performance of neural networks. We also show that the proposed algorithm enables parameter regularization methods to be applied to class-incremental problems. Additionally, we provide a theoretical reason why the existing parameter-space regularization algorithms such as EWC underperform on neural networks trained with cross-entropy loss. We show that the proposed method can prevent forgetting while achieving high continual fine-tuning performance on image classification tasks. To show that our method can be applied to general continual learning settings, we evaluate our method in data-incremental, task-incremental, and class-incremental learning problems.
Joint Negative and Positive Learning for Noisy Labels
Apr 14, 2021
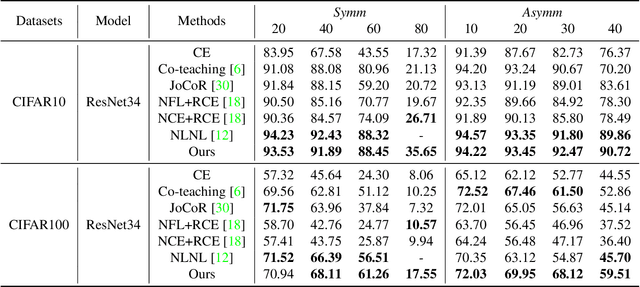
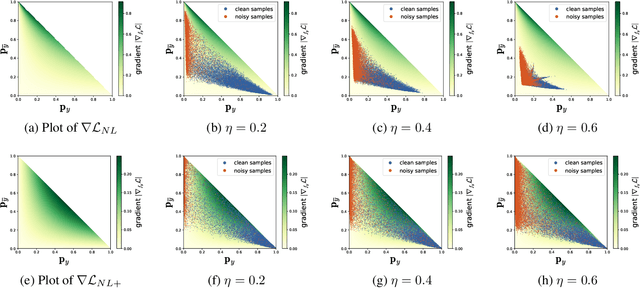
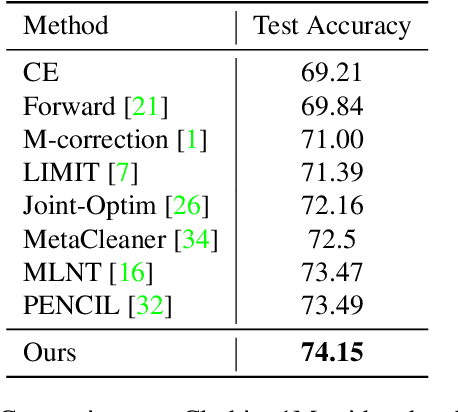
Training of Convolutional Neural Networks (CNNs) with data with noisy labels is known to be a challenge. Based on the fact that directly providing the label to the data (Positive Learning; PL) has a risk of allowing CNNs to memorize the contaminated labels for the case of noisy data, the indirect learning approach that uses complementary labels (Negative Learning for Noisy Labels; NLNL) has proven to be highly effective in preventing overfitting to noisy data as it reduces the risk of providing faulty target. NLNL further employs a three-stage pipeline to improve convergence. As a result, filtering noisy data through the NLNL pipeline is cumbersome, increasing the training cost. In this study, we propose a novel improvement of NLNL, named Joint Negative and Positive Learning (JNPL), that unifies the filtering pipeline into a single stage. JNPL trains CNN via two losses, NL+ and PL+, which are improved upon NL and PL loss functions, respectively. We analyze the fundamental issue of NL loss function and develop new NL+ loss function producing gradient that enhances the convergence of noisy data. Furthermore, PL+ loss function is designed to enable faster convergence to expected-to-be-clean data. We show that the NL+ and PL+ train CNN simultaneously, significantly simplifying the pipeline, allowing greater ease of practical use compared to NLNL. With a simple semi-supervised training technique, our method achieves state-of-the-art accuracy for noisy data classification based on the superior filtering ability.