 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE Path 2.5: Pathology Foundation Model with Multi-Omics Alignment
Dec 16, 2025Cancer progression arises from interactions across multiple biological layers, especially beyond morphological and across molecular layers that remain invisible to image-only models. To capture this broader biological landscape, we present EXAONE Path 2.5, a pathology foundation model that jointly models histologic, genomic, epigenetic and transcriptomic modalities, producing an integrated patient representation that reflects tumor biology more comprehensively. Our approach incorporates three key components: (1) multimodal SigLIP loss enabling all-pairwise contrastive learning across heterogeneous modalities, (2) a fragment-aware rotary positional encoding (F-RoPE) module that preserves spatial structure and tissue-fragment topology in WSI, and (3) domain-specialized internal foundation models for both WSI and RNA-seq to provide biologically grounded embeddings for robust multimodal alignment. We evaluate EXAONE Path 2.5 against six leading pathology foundation models across two complementary benchmarks: an internal real-world clinical dataset and the Patho-Bench benchmark covering 80 tasks. Our framework demonstrates high data and parameter efficiency, achieving on-par performance with state-of-the-art foundation models on Patho-Bench while exhibiting the highest adaptability in the internal clinical setting. These results highlight the value of biologically informed multimodal design and underscore the potential of integrated genotype-to-phenotype modeling for next-generation precision oncology.
Controllable Feature Whitening for Hyperparameter-Free Bias Mitigation
Jul 27, 2025


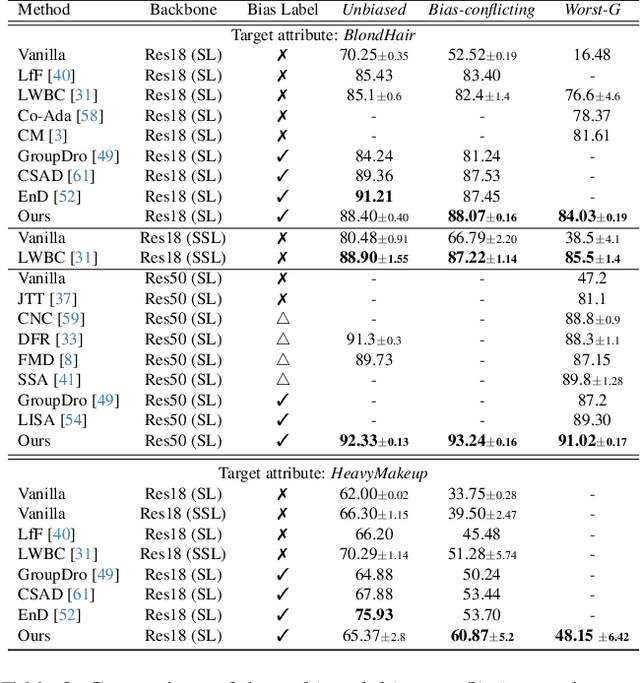
As the use of artificial intelligence rapidly increases, the development of trustworthy artificial intelligence has become important. However, recent studies have shown that deep neural networks are susceptible to learn spurious correlations present in datasets. To improve the reliability, we propose a simple yet effective framework called controllable feature whitening. We quantify the linear correlation between the target and bias features by the covariance matrix, and eliminate it through the whitening module. Our results systemically demonstrate that removing the linear correlations between features fed into the last linear classifier significantly mitigates the bias, while avoiding the need to model intractable higher-order dependencies. A particular advantage of the proposed method is that it does not require regularization terms or adversarial learning, which often leads to unstable optimization in practice. Furthermore, we show that two fairness criteria, demographic parity and equalized odds, can be effectively handled by whitening with the re-weighted covariance matrix. Consequently, our method controls the trade-off between the utility and fairness of algorithms by adjusting the weighting coefficient. Finally, we validate that our method outperforms existing approaches on four benchmark datasets: Corrupted CIFAR-10, Biased FFHQ, WaterBirds, and Celeb-A.
EXAONE Path 2.0: Pathology Foundation Model with End-to-End Supervision
Jul 09, 2025In digital pathology, whole-slide images (WSIs) are often difficult to handle due to their gigapixel scale, so most approaches train patch encoders via self-supervised learning (SSL) and then aggregate the patch-level embeddings via multiple instance learning (MIL) or slide encoders for downstream tasks. However, patch-level SSL may overlook complex domain-specific features that are essential for biomarker prediction, such as mutation status and molecular characteristics, as SSL methods rely only on basic augmentations selected for natural image domains on small patch-level area. Moreover, SSL methods remain less data efficient than fully supervised approaches, requiring extensive computational resources and datasets to achieve competitive performance. To address these limitations, we present EXAONE Path 2.0, a pathology foundation model that learns patch-level representations under direct slide-level supervision. Using only 37k WSIs for training, EXAONE Path 2.0 achieves state-of-the-art average performance across 10 biomarker prediction tasks, demonstrating remarkable data efficiency.
Disposable Transfer Learning for Selective Source Task Unlearning
Aug 19, 2023Transfer learning is widely used for training deep neural networks (DNN) for building a powerful representation. Even after the pre-trained model is adapted for the target task, the representation performance of the feature extractor is retained to some extent. As the performance of the pre-trained model can be considered the private property of the owner, it is natural to seek the exclusive right of the generalized performance of the pre-trained weight. To address this issue, we suggest a new paradigm of transfer learning called disposable transfer learning (DTL), which disposes of only the source task without degrading the performance of the target task. To achieve knowledge disposal, we propose a novel loss named Gradient Collision loss (GC loss). GC loss selectively unlearns the source knowledge by leading the gradient vectors of mini-batches in different directions. Whether the model successfully unlearns the source task is measured by piggyback learning accuracy (PL accuracy). PL accuracy estimates the vulnerability of knowledge leakage by retraining the scrubbed model on a subset of source data or new downstream data. We demonstrate that GC loss is an effective approach to the DTL problem by showing that the model trained with GC loss retains the performance on the target task with a significantly reduced PL accuracy.
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022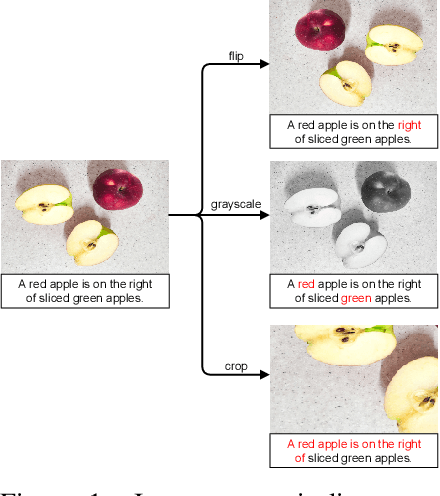
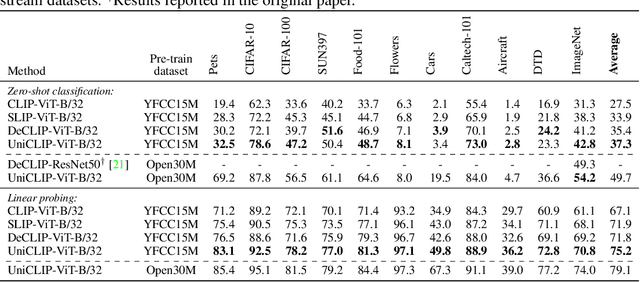
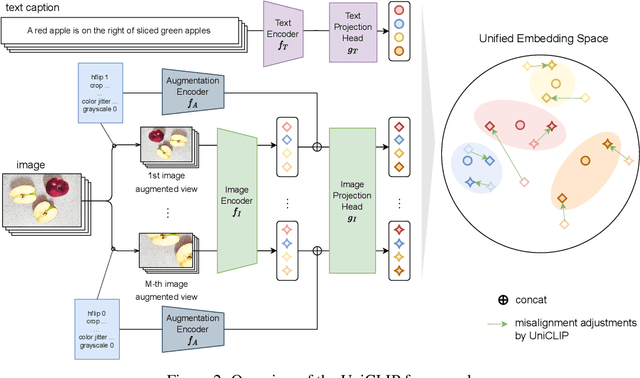
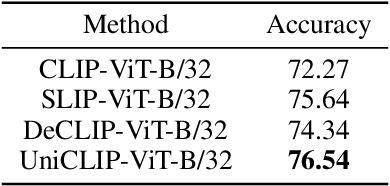
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
DLCFT: Deep Linear Continual Fine-Tuning for General Incremental Learning
Aug 17, 2022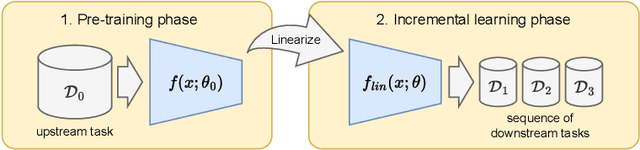
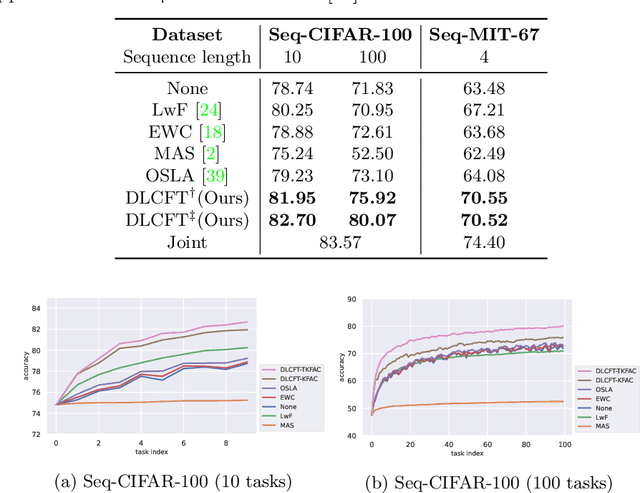
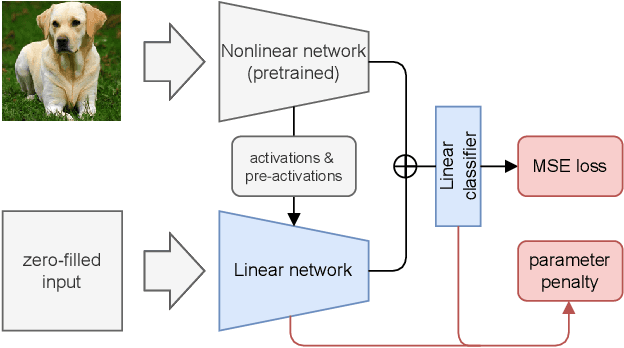
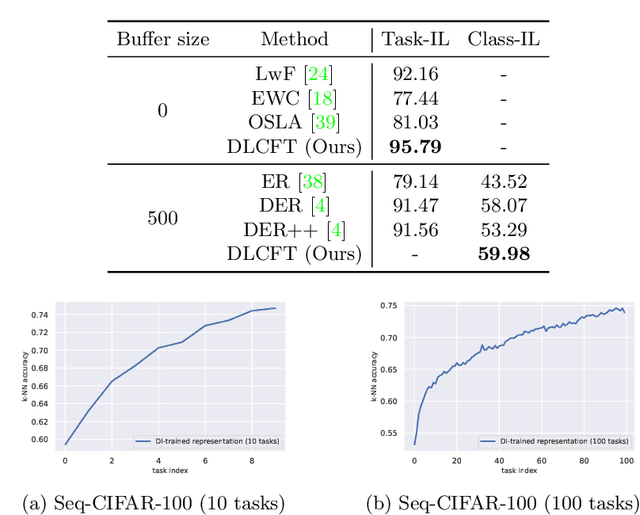
Pre-trained representation is one of the key elements in the success of modern deep learning. However, existing works on continual learning methods have mostly focused on learning models incrementally from scratch. In this paper, we explore an alternative framework to incremental learning where we continually fine-tune the model from a pre-trained representation. Our method takes advantage of linearization technique of a pre-trained neural network for simple and effective continual learning. We show that this allows us to design a linear model where quadratic parameter regularization method is placed as the optimal continual learning policy, and at the same time enjoying the high performance of neural networks. We also show that the proposed algorithm enables parameter regularization methods to be applied to class-incremental problems. Additionally, we provide a theoretical reason why the existing parameter-space regularization algorithms such as EWC underperform on neural networks trained with cross-entropy loss. We show that the proposed method can prevent forgetting while achieving high continual fine-tuning performance on image classification tasks. To show that our method can be applied to general continual learning settings, we evaluate our method in data-incremental, task-incremental, and class-incremental learning problems.
TricubeNet: 2D Kernel-Based Object Representation for Weakly-Occluded Oriented Object Detection
Apr 23, 2021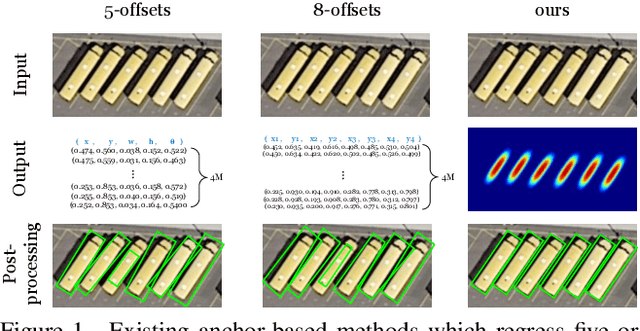
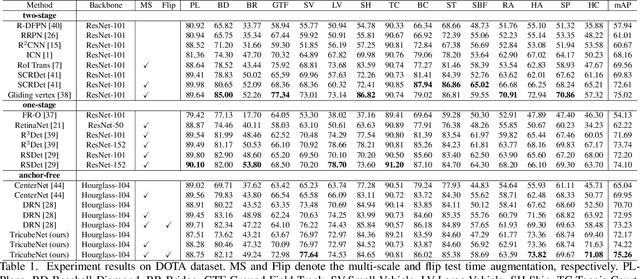
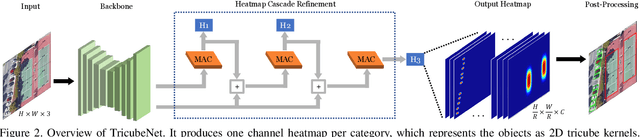
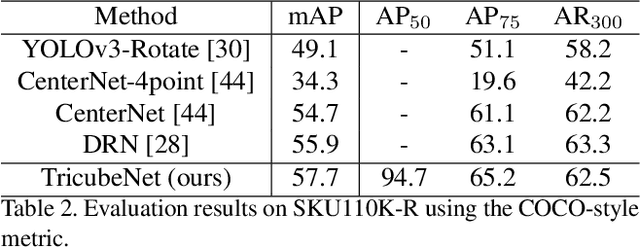
We present a new approach for oriented object detection, an anchor-free one-stage detector. This approach, named TricubeNet, represents each object as a 2D Tricube kernel and extracts bounding boxes using appearance-based post-processing. Unlike existing anchor-based oriented object detectors, we can save the computational complexity and the number of hyperparameters by eliminating the anchor box in the network design. In addition, by adopting a heatmap-based detection process instead of the box offset regression, we simply and effectively solve the angle discontinuity problem, which is one of the important problems for oriented object detection. To further boost the performance, we propose some effective techniques for the loss balancing, extracting the rotation-invariant feature, and heatmap refinement. To demonstrate the effectiveness of our TricueNet, we experiment on various tasks for the weakly-occluded oriented object detection. The extensive experimental results show that our TricueNet is highly effective and competitive for oriented object detection. The code is available at https://github.com/qjadud1994/TricubeNet.
Continual Learning with Extended Kronecker-factored Approximate Curvature
Apr 16, 2020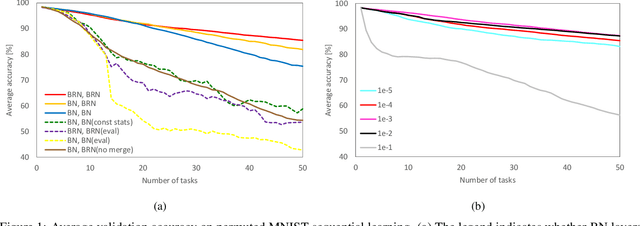
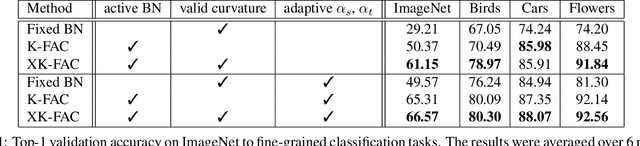
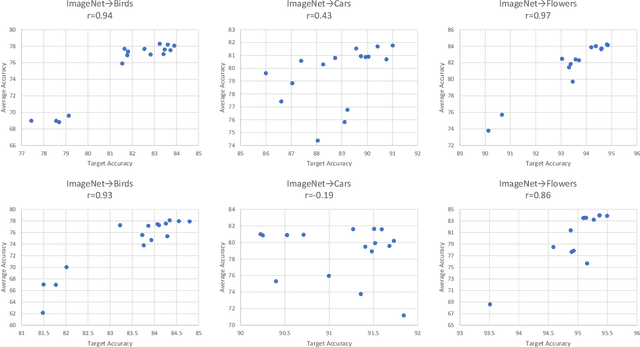
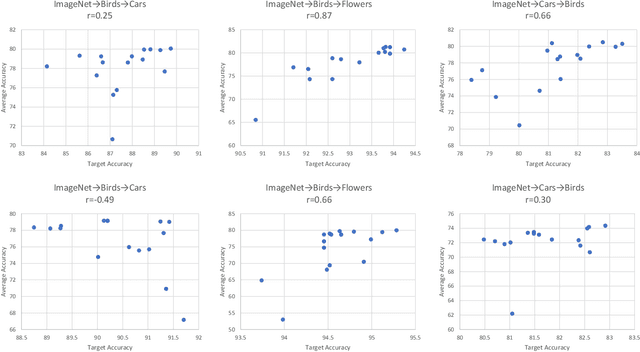
We propose a quadratic penalty method for continual learning of neural networks that contain batch normalization (BN) layers. The Hessian of a loss function represents the curvature of the quadratic penalty function, and a Kronecker-factored approximate curvature (K-FAC) is used widely to practically compute the Hessian of a neural network. However, the approximation is not valid if there is dependence between examples, typically caused by BN layers in deep network architectures. We extend the K-FAC method so that the inter-example relations are taken into account and the Hessian of deep neural networks can be properly approximated under practical assumptions. We also propose a method of weight merging and reparameterization to properly handle statistical parameters of BN, which plays a critical role for continual learning with BN, and a method that selects hyperparameters without source task data. Our method shows better performance than baselines in the permuted MNIST task with BN layers and in sequential learning from the ImageNet classification task to fine-grained classification tasks with ResNet-50, without any explicit or implicit use of source task data for hyperparameter selection.
Residual Continual Learning
Feb 17, 2020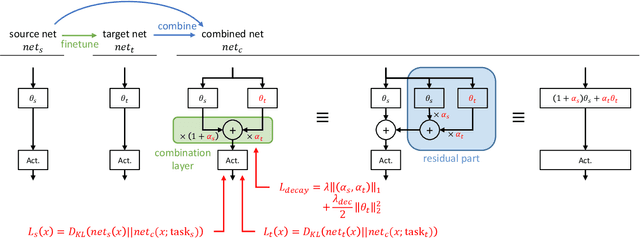

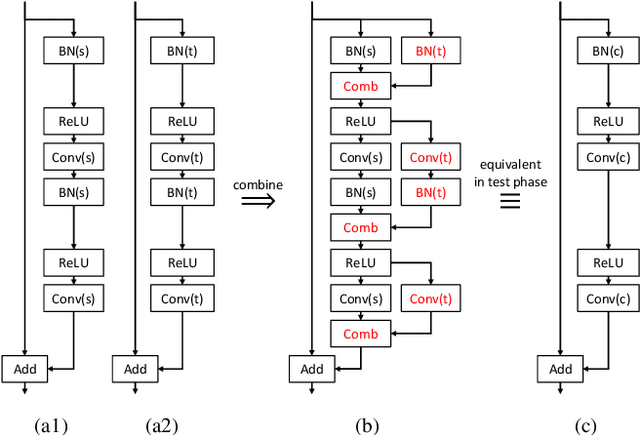

We propose a novel continual learning method called Residual Continual Learning (ResCL). Our method can prevent the catastrophic forgetting phenomenon in sequential learning of multiple tasks, without any source task information except the original network. ResCL reparameterizes network parameters by linearly combining each layer of the original network and a fine-tuned network; therefore, the size of the network does not increase at all. To apply the proposed method to general convolutional neural networks, the effects of batch normalization layers are also considered. By utilizing residual-learning-like reparameterization and a special weight decay loss, the trade-off between source and target performance is effectively controlled. The proposed method exhibits state-of-the-art performance in various continual learning scenarios.