 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Where It Matters: Geometric Anchoring for Robust Preference Alignment
Feb 04, 2026Direct Preference Optimization (DPO) and related methods align large language models from pairwise preferences by regularizing updates against a fixed reference policy. As the policy drifts, a static reference, however, can become increasingly miscalibrated, leading to distributional mismatch and amplifying spurious preference signals under noisy supervision. Conversely, reference-free variants avoid mismatch but often suffer from unconstrained reward drift. We propose Geometric Anchor Preference Optimization (GAPO), which replaces the fixed reference with a dynamic, geometry-aware anchor: an adversarial local perturbation of the current policy within a small radius that serves as a pessimistic baseline. This anchor enables an adaptive reweighting mechanism, modulating the importance of each preference pair based on its local sensitivity. We further introduce the Anchor Gap, the reward discrepancy between the policy and its anchor, and show under smoothness conditions that it approximates worst-case local margin degradation. Optimizing a logistic objective weighted by this gap downweights geometrically brittle instances while emphasizing robust preference signals. Across diverse noise settings, GAPO consistently improves robustness while matching or improving performance on standard LLM alignment and reasoning benchmarks.
FxSearcher: gradient-free text-driven audio transformation
Nov 18, 2025Achieving diverse and high-quality audio transformations from text prompts remains challenging, as existing methods are fundamentally constrained by their reliance on a limited set of differentiable audio effects. This paper proposes \textbf{FxSearcher}, a novel gradient-free framework that discovers the optimal configuration of audio effects (FX) to transform a source signal according to a text prompt. Our method employs Bayesian Optimization and CLAP-based score function to perform this search efficiently. Furthermore, a guiding prompt is introduced to prevent undesirable artifacts and enhance human preference. To objectively evaluate our method, we propose an AI-based evaluation framework. The results demonstrate that the highest scores achieved by our method on these metrics align closely with human preferences. Demos are available at https://hojoonki.github.io/FxSearcher/
FairASR: Fair Audio Contrastive Learning for Automatic Speech Recognition
Jun 12, 2025Large-scale ASR models have achieved remarkable gains in accuracy and robustness. However, fairness issues remain largely unaddressed despite their critical importance in real-world applications. In this work, we introduce FairASR, a system that mitigates demographic bias by learning representations that are uninformative about group membership, enabling fair generalization across demographic groups. Leveraging a multi-demographic dataset, our approach employs a gradient reversal layer to suppress demographic-discriminative features while maintaining the ability to capture generalizable speech patterns through an unsupervised contrastive loss. Experimental results show that FairASR delivers competitive overall ASR performance while significantly reducing performance disparities across different demographic groups.
StablePrompt: Automatic Prompt Tuning using Reinforcement Learning for Large Language Models
Oct 10, 2024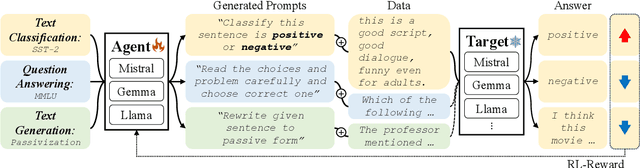
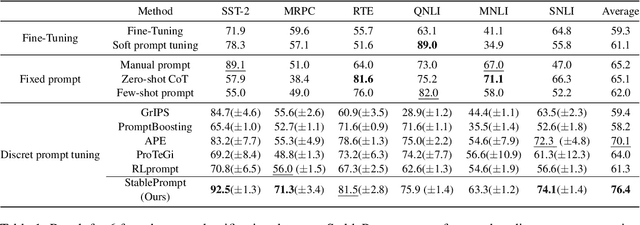
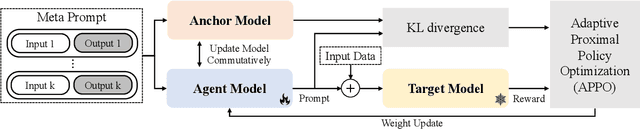
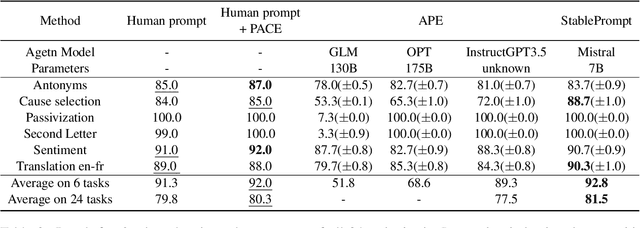
Finding appropriate prompts for the specific task has become an important issue as the usage of Large Language Models (LLM) has expanded. Reinforcement Learning (RL) is widely used for prompt tuning, but its inherent instability and environmental dependency make it difficult to use in practice. In this paper, we propose StablePrompt, which strikes a balance between training stability and search space, mitigating the instability of RL and producing high-performance prompts. We formulate prompt tuning as an online RL problem between the agent and target LLM and introduce Adaptive Proximal Policy Optimization (APPO). APPO introduces an LLM anchor model to adaptively adjust the rate of policy updates. This allows for flexible prompt search while preserving the linguistic ability of the pre-trained LLM. StablePrompt outperforms previous methods on various tasks including text classification, question answering, and text generation. Our code can be found in github.
AVCap: Leveraging Audio-Visual Features as Text Tokens for Captioning
Jul 11, 2024
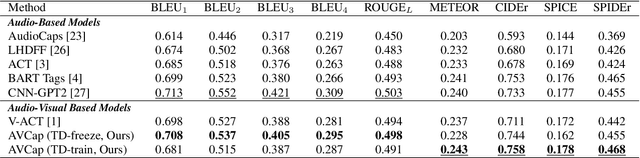
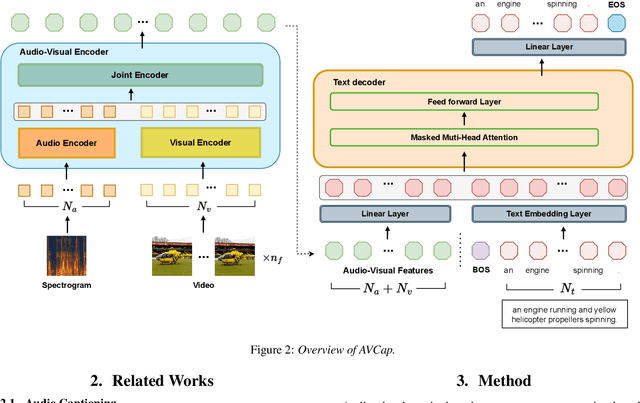
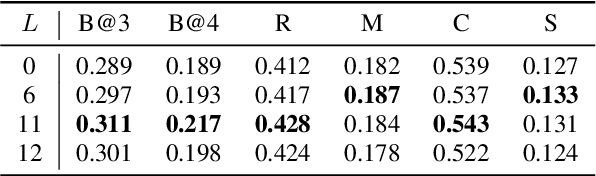
In recent years, advancements in representation learning and language models have propelled Automated Captioning (AC) to new heights, enabling the generation of human-level descriptions. Leveraging these advancements, we propose AVCap, an Audio-Visual Captioning framework, a simple yet powerful baseline approach applicable to audio-visual captioning. AVCap utilizes audio-visual features as text tokens, which has many advantages not only in performance but also in the extensibility and scalability of the model. AVCap is designed around three pivotal dimensions: the exploration of optimal audio-visual encoder architectures, the adaptation of pre-trained models according to the characteristics of generated text, and the investigation into the efficacy of modality fusion in captioning. Our method outperforms existing audio-visual captioning methods across all metrics and the code is available on https://github.com/JongSuk1/AVCap
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Mar 14, 2024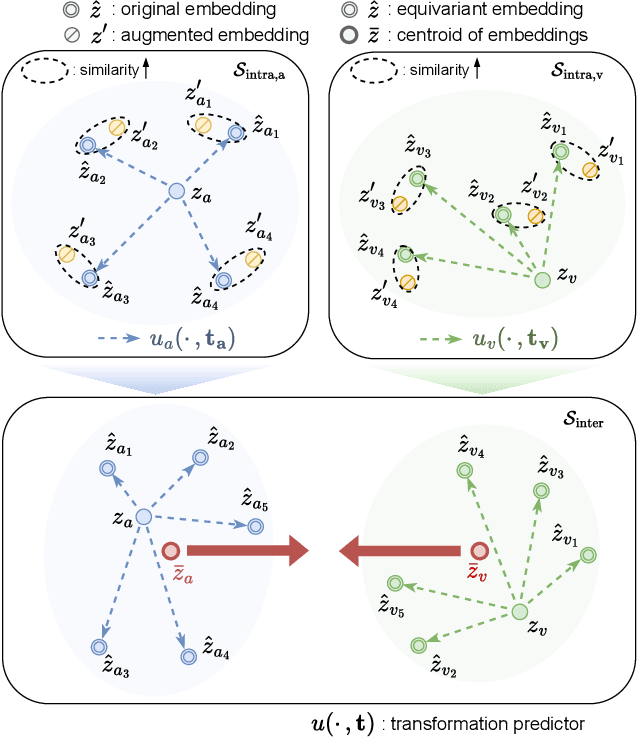

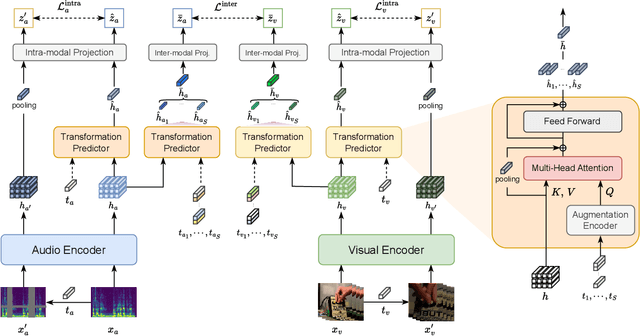

Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks.
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022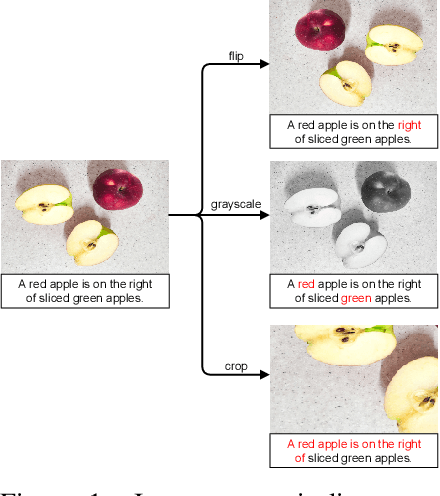
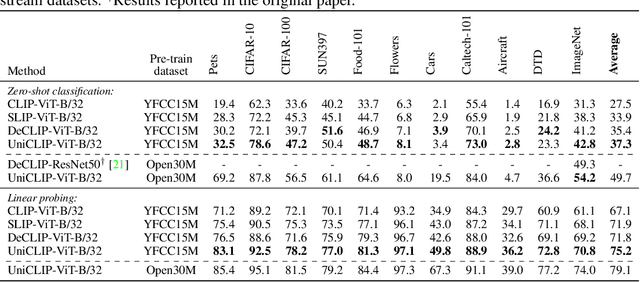
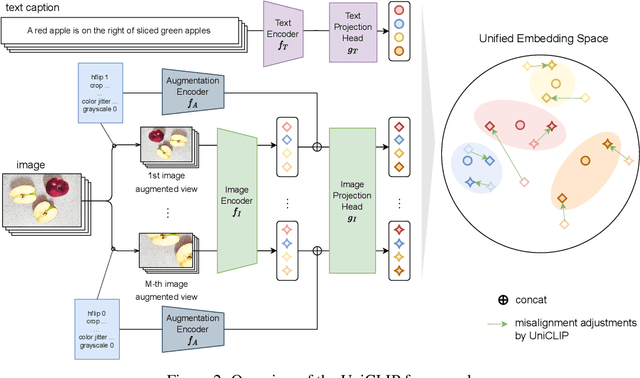
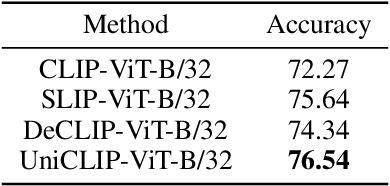
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.