 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Joint Audio-Video Generation
Jun 02, 2026Joint audio-video generation aims to synthesize realistic audio-video pairs that are both semantically aligned with text prompts and precisely synchronized. While existing joint audio-video generation models often require substantial training resources to improve fidelity, Inference-Time Scaling (ITS) has recently emerged as a promising training-free alternative in single-modality domains. However, extending ITS from a single modality to multimodal domains is non-trivial, as it requires balancing multiple heterogeneous objectives. In this paper, we present the first comprehensive study of ITS for joint audio-video generation. We first demonstrate that a multi-verifier framework is essential to address the limitations of single-objective guidance, including asymmetric performance trade-offs and verifier hacking. Through systematic analysis, we then identify an optimal multi-verifier combination that yields balanced improvements across all quality dimensions. Finally, to effectively aggregate diverse reward signals, we propose Adaptive Reward Weighting (ARW), a novel test-time optimization algorithm. ARW treats reward aggregation as an online optimization problem, utilizing learnable parameters to calibrate reward variances without requiring prior knowledge of reward distributions, thereby ensuring robust multi-objective selection. Experimental results on VGGSound and JavisBench-mini benchmarks demonstrate that our framework significantly enhances semantic alignment, perceptual quality, and audio-visual synchronization of generated outputs. Synthesized samples and code are available on the project page: https://jung-jaemin.github.io/ITS-AVGen-Proj.
Keep What Audio Cannot Say: Context-Preserving Token Pruning for Omni-LLMs
May 12, 2026Omnimodal Large Language Models (Omni-LLMs) incur substantial computational overhead due to the large number of multimodal input tokens they process, making token reduction essential for real-world deployment. Existing Omni-LLM pruning methods typically reduce this cost by selecting tokens that are important for the current query or strongly aligned with cross-modal cues. However, such strategies can discard evidence that falls outside these criteria, even when needed for different questions or for understanding context beyond aligned audio-visual cues. To address this limitation, we reframe Omni-LLM token reduction as preserving broad audio-visual context while removing cross-modal redundancy. We propose ContextGuard, an inference-time token pruning framework built on this principle. ContextGuard predicts coarse visual semantics from audio and prunes video tokens whose coarse semantics are likely recoverable from audio, while retaining additional video tokens to preserve localized visual details that audio alone cannot specify. For further compression, our method merges temporally similar video tokens. The framework requires no downstream LLM fine-tuning and uses only an independently trained lightweight predictor. On Qwen2.5-Omni and Video-SALMONN2+ at 3B and 7B scales across six audio-visual benchmarks, ContextGuard outperforms prior inference-time pruning methods while pruning more tokens. Notably, on Qwen2.5-Omni 7B, ContextGuard achieves full-token-level performance on five of six benchmarks while pruning 55% of input tokens.
LAVCap: LLM-based Audio-Visual Captioning using Optimal Transport
Jan 16, 2025



Automated audio captioning is a task that generates textual descriptions for audio content, and recent studies have explored using visual information to enhance captioning quality. However, current methods often fail to effectively fuse audio and visual data, missing important semantic cues from each modality. To address this, we introduce LAVCap, a large language model (LLM)-based audio-visual captioning framework that effectively integrates visual information with audio to improve audio captioning performance. LAVCap employs an optimal transport-based alignment loss to bridge the modality gap between audio and visual features, enabling more effective semantic extraction. Additionally, we propose an optimal transport attention module that enhances audio-visual fusion using an optimal transport assignment map. Combined with the optimal training strategy, experimental results demonstrate that each component of our framework is effective. LAVCap outperforms existing state-of-the-art methods on the AudioCaps dataset, without relying on large datasets or post-processing. Code is available at https://github.com/NAVER-INTEL-Co-Lab/gaudi-lavcap.
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Mar 14, 2024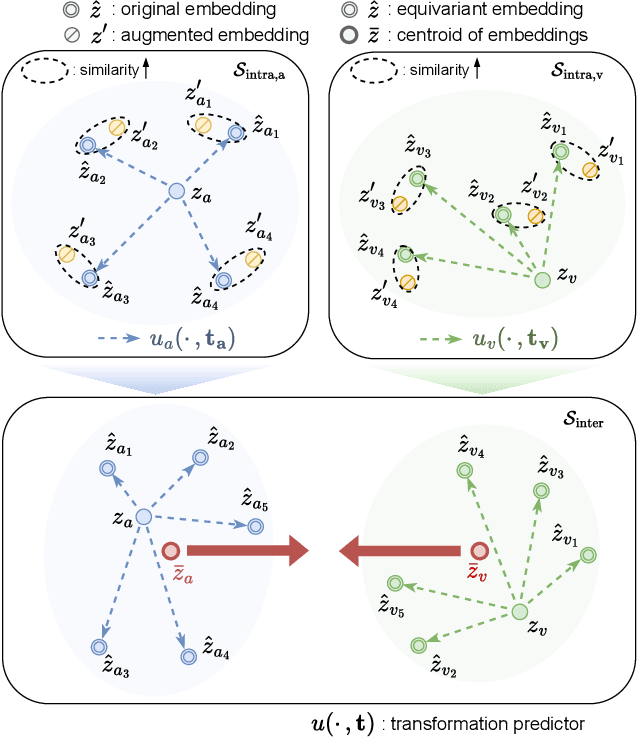

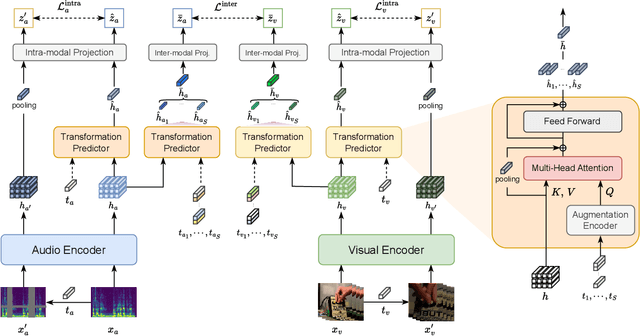

Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks.
TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
Sep 21, 2023



The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.
That's What I Said: Fully-Controllable Talking Face Generation
Apr 06, 2023The goal of this paper is to synthesise talking faces with controllable facial motions. To achieve this goal, we propose two key ideas. The first is to establish a canonical space where every face has the same motion patterns but different identities. The second is to navigate a multimodal motion space that only represents motion-related features while eliminating identity information. To disentangle identity and motion, we introduce an orthogonality constraint between the two different latent spaces. From this, our method can generate natural-looking talking faces with fully controllable facial attributes and accurate lip synchronisation. Extensive experiments demonstrate that our method achieves state-of-the-art results in terms of both visual quality and lip-sync score. To the best of our knowledge, we are the first to develop a talking face generation framework that can accurately manifest full target facial motions including lip, head pose, and eye movements in the generated video without any additional supervision beyond RGB video with audio.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020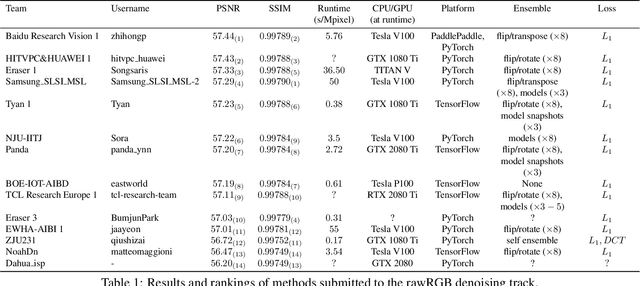
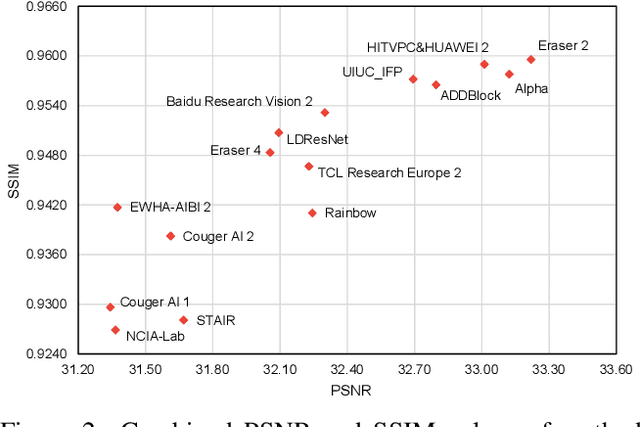
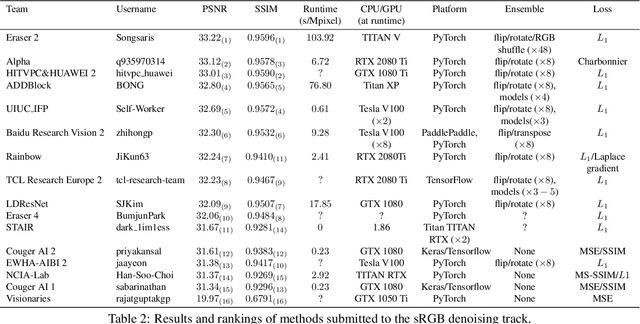
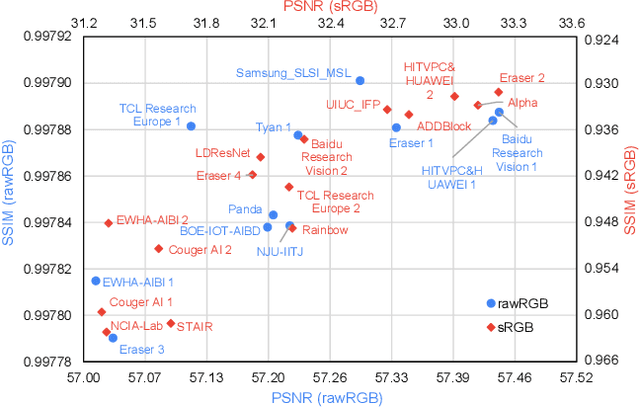
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.