 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Spoke When in Multi-Conversation: Target Speaker Tagging Task and Benchmark
Jun 12, 2026We present target speaker tagging (TST), a task that integrates speaker diarization, verification, and identification into a unified workflow for multi-speaker conversations. Given long recordings and pre-enrolled speakers, TST detects and labels speech segments of known speakers while rejecting unknown ones. Despite its practical importance, research has been limited by the absence of suitable evaluation resources. To address this, we introduce TST-Bench, a large-scale synthetic benchmark with over 150 enrolled speakers, 300 sessions of 20-60 minutes, and reference annotations with global speaker labels. We define an evaluation protocol encompassing diarization and full-pipeline scenarios. Experiments on both real and synthetic data show that TST poses challenges not captured by conventional benchmarks, and that dedicated system design yields significant gains over naive integration of existing solutions. The benchmark dataset and evaluation protocols are publicly released.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Rethinking Session Variability: Leveraging Session Embeddings for Session Robustness in Speaker Verification
Sep 26, 2023

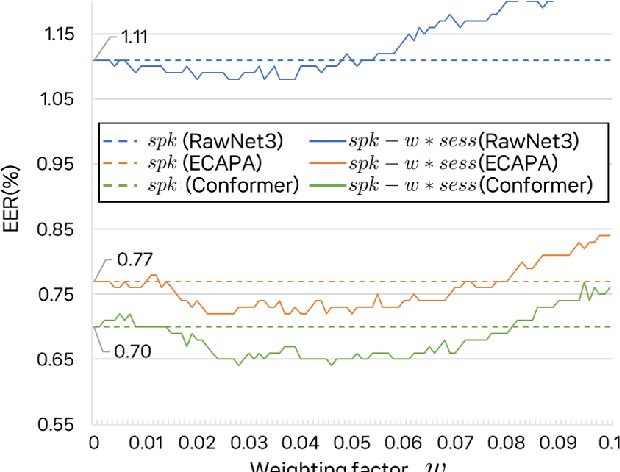
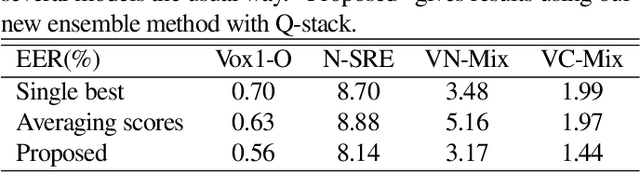
In the field of speaker verification, session or channel variability poses a significant challenge. While many contemporary methods aim to disentangle session information from speaker embeddings, we introduce a novel approach using an additional embedding to represent the session information. This is achieved by training an auxiliary network appended to the speaker embedding extractor which remains fixed in this training process. This results in two similarity scores: one for the speakers information and one for the session information. The latter score acts as a compensator for the former that might be skewed due to session variations. Our extensive experiments demonstrate that session information can be effectively compensated without retraining of the embedding extractor.
TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
Sep 21, 2023



The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.
Encoder-decoder multimodal speaker change detection
Jun 01, 2023The task of speaker change detection (SCD), which detects points where speakers change in an input, is essential for several applications. Several studies solved the SCD task using audio inputs only and have shown limited performance. Recently, multimodal SCD (MMSCD) models, which utilise text modality in addition to audio, have shown improved performance. In this study, the proposed model are built upon two main proposals, a novel mechanism for modality fusion and the adoption of a encoder-decoder architecture. Different to previous MMSCD works that extract speaker embeddings from extremely short audio segments, aligned to a single word, we use a speaker embedding extracted from 1.5s. A transformer decoder layer further improves the performance of an encoder-only MMSCD model. The proposed model achieves state-of-the-art results among studies that report SCD performance and is also on par with recent work that combines SCD with automatic speech recognition via human transcription.
Absolute decision corrupts absolutely: conservative online speaker diarisation
Nov 09, 2022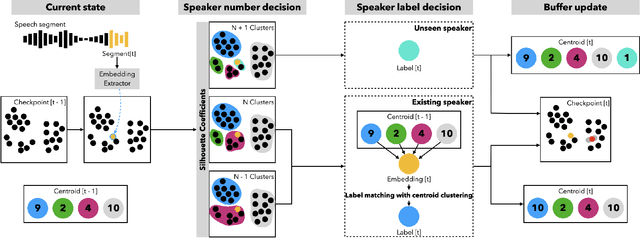
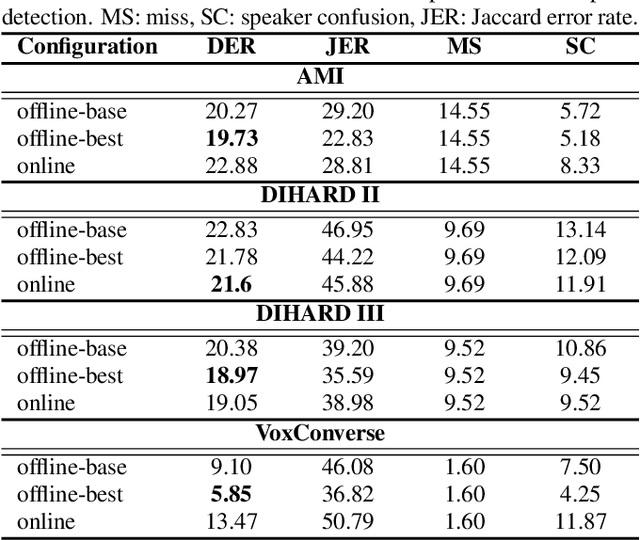
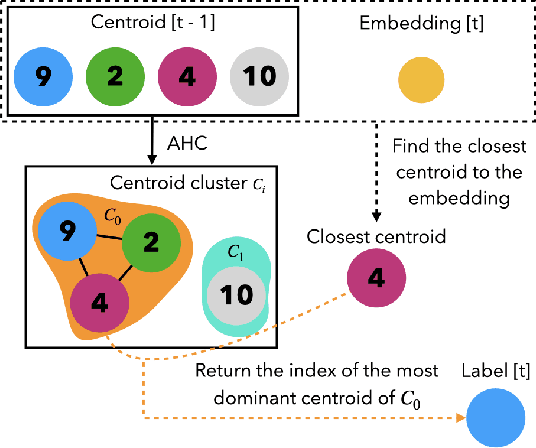
Our focus lies in developing an online speaker diarisation framework which demonstrates robust performance across diverse domains. In online speaker diarisation, outputs generated in real-time are irreversible, and a few misjudgements in the early phase of an input session can lead to catastrophic results. We hypothesise that cautiously increasing the number of estimated speakers is of paramount importance among many other factors. Thus, our proposed framework includes decreasing the number of speakers by one when the system judges that an increase in the past was faulty. We also adopt dual buffers, checkpoints and centroids, where checkpoints are combined with silhouette coefficients to estimate the number of speakers and centroids represent speakers. Again, we believe that more than one centroid can be generated from one speaker. Thus we design a clustering-based label matching technique to assign labels in real-time. The resulting system is lightweight yet surprisingly effective. The system demonstrates state-of-the-art performance on DIHARD 2 and 3 datasets, where it is also competitive in AMI and VoxConverse test sets.
High-resolution embedding extractor for speaker diarisation
Nov 08, 2022
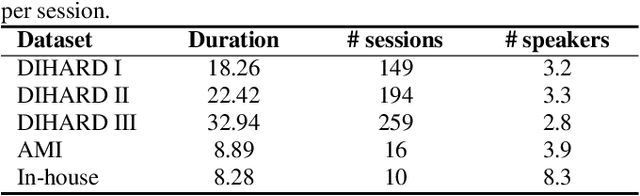

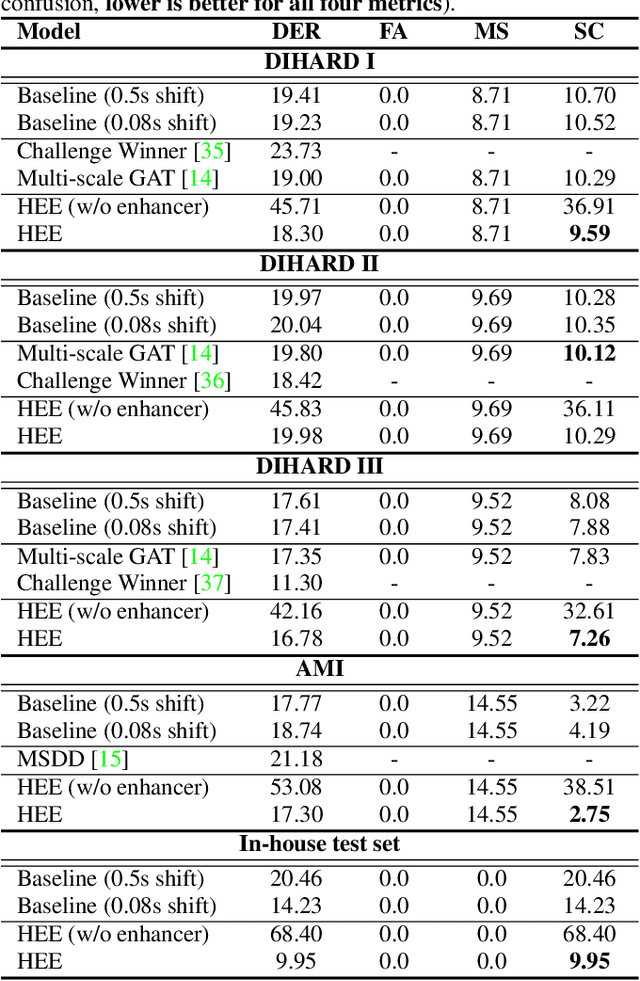
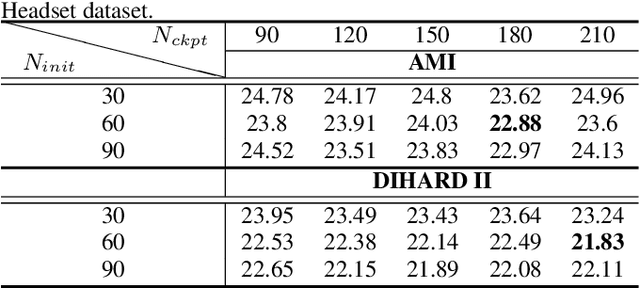
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.
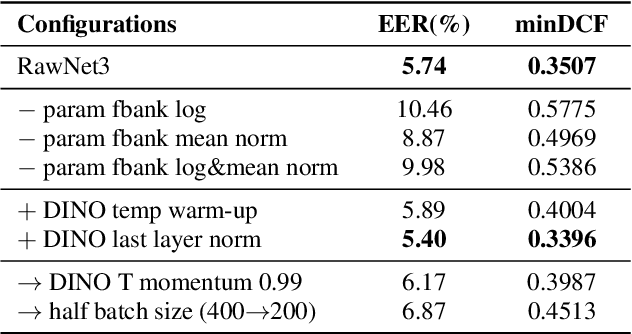
Self-supervised curriculum learning for speaker verification
Apr 05, 2022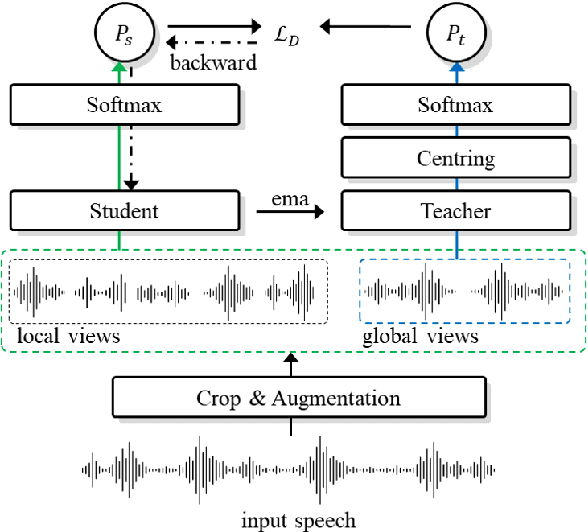
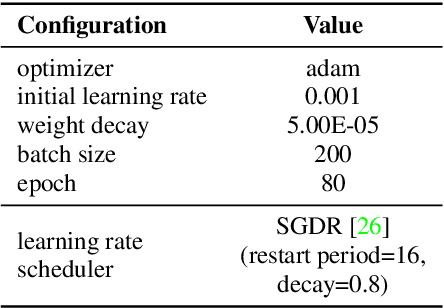
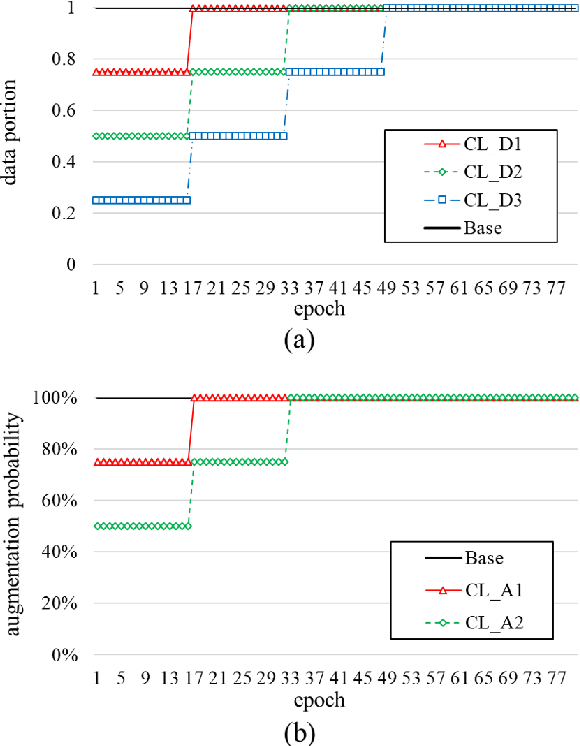
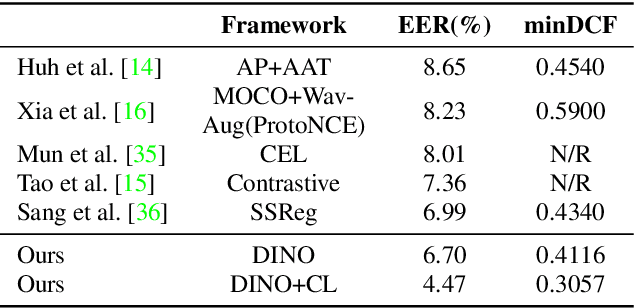
Self-supervised learning is one of the emerging approaches to machine learning today, and has been successfully applied to vision, speech and natural processing tasks. There is a range of frameworks within self-supervised learning literature, but the speaker recognition literature has particularly adopted self-supervision via contrastive loss functions. Our work adapts the DINO framework for speaker recognition, in which the model is trained without exploiting negative utterance pairs. We introduce a curriculum learning strategy to the self-supervised framework, which guides effective training of speaker recognition models. In particular, we propose two curriculum strategies where one gradually increases the number of speakers in training dataset, and the other gradually applies augmentations to more utterances within a mini-batch as the training proceeds. A range of experiments conducted on the VoxCeleb1 evaluation protocol demonstrate the effectiveness of both the DINO framework on speaker verification and our proposed curriculum learning strategies. We report the state-of-the-art equal error rate of 4.47% with a single-phase training.
Pushing the limits of raw waveform speaker recognition
Mar 29, 2022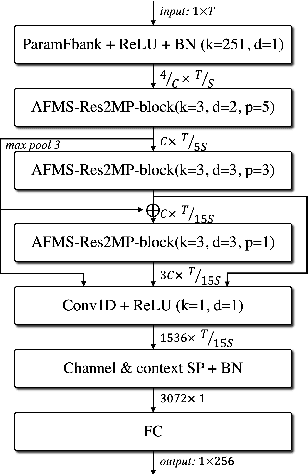
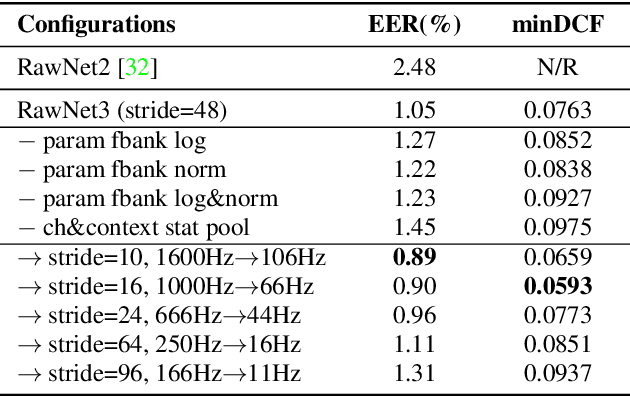
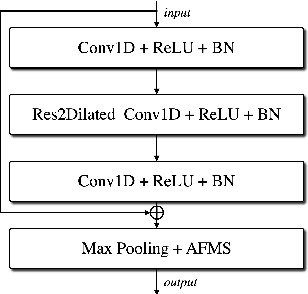
In recent years, speaker recognition systems based on raw waveform inputs have received increasing attention. However, the performance of such systems are typically inferior to the state-of-the-art handcrafted feature-based counterparts, which demonstrate equal error rates under 1% on the popular VoxCeleb1 test set. This paper proposes a novel speaker recognition model based on raw waveform inputs. The model incorporates recent advances in machine learning and speaker verification, including the Res2Net backbone module and multi-layer feature aggregation. Our best model achieves an equal error rate of 0.89%, which is competitive with the state-of-the-art models based on handcrafted features, and outperforms the best model based on raw waveform inputs by a large margin. We also explore the application of the proposed model in the context of self-supervised learning framework. Our self-supervised model outperforms single phase-based existing works in this line of research. Finally, we show that self-supervised pre-training is effective for the semi-supervised scenario where we only have a small set of labelled training data, along with a larger set of unlabelled examples.
Disentangled dimensionality reduction for noise-robust speaker diarisation
Oct 07, 2021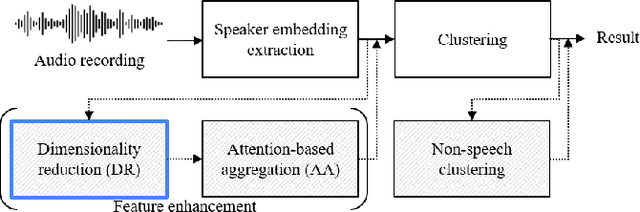
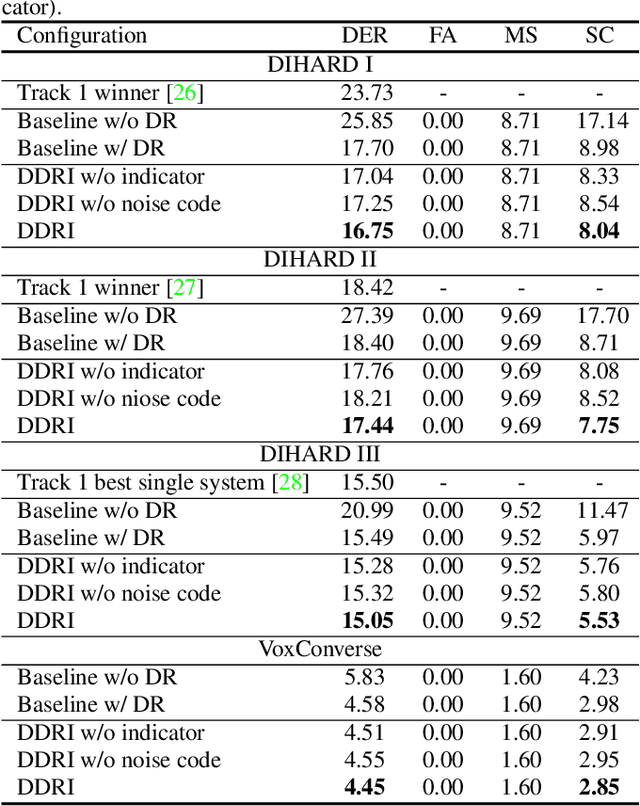
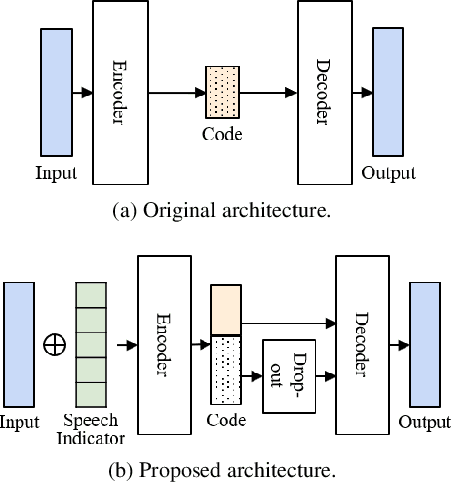

The objective of this work is to train noise-robust speaker embeddings for speaker diarisation. Speaker embeddings play a crucial role in the performance of diarisation systems, but they often capture spurious information such as noise and reverberation, adversely affecting performance. Our previous work have proposed an auto-encoder-based dimensionality reduction module to help remove the spurious information. However, they do not explicitly separate such information and have also been found to be sensitive to hyperparameter values. To this end, we propose two contributions to overcome these issues: (i) a novel dimensionality reduction framework that can disentangle spurious information from the speaker embeddings; (ii) the use of a speech/non-speech indicator to prevent the speaker code from learning from the background noise. Through a range of experiments conducted on four different datasets, our approach consistently demonstrates the state-of-the-art performance among models that do not adopt ensembles.