 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised curriculum learning for speaker verification
Paper and Code
Apr 05, 2022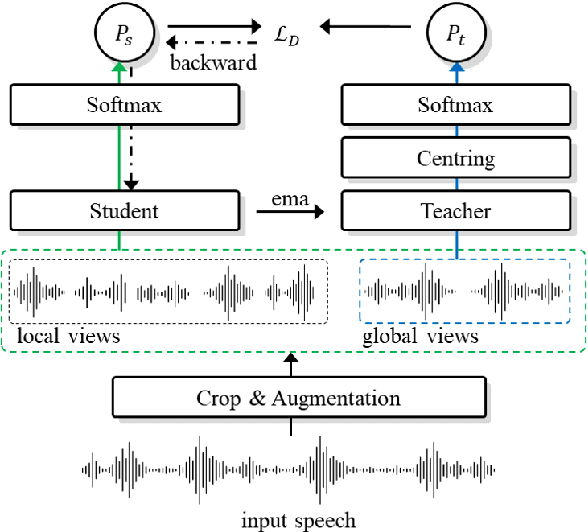
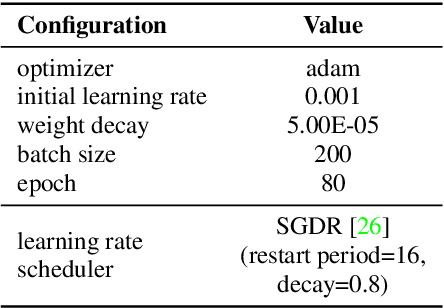
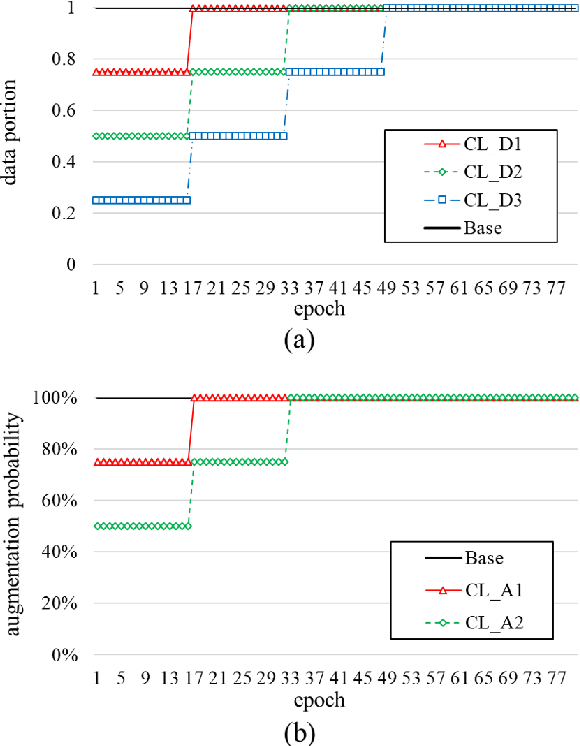
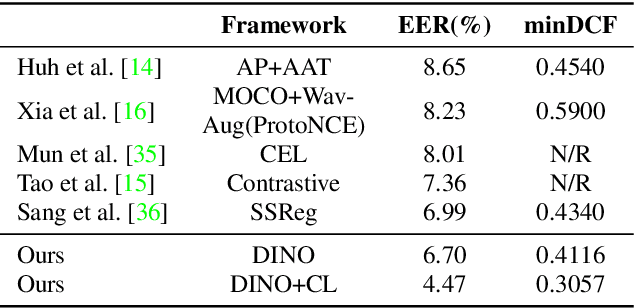
Self-supervised learning is one of the emerging approaches to machine learning today, and has been successfully applied to vision, speech and natural processing tasks. There is a range of frameworks within self-supervised learning literature, but the speaker recognition literature has particularly adopted self-supervision via contrastive loss functions. Our work adapts the DINO framework for speaker recognition, in which the model is trained without exploiting negative utterance pairs. We introduce a curriculum learning strategy to the self-supervised framework, which guides effective training of speaker recognition models. In particular, we propose two curriculum strategies where one gradually increases the number of speakers in training dataset, and the other gradually applies augmentations to more utterances within a mini-batch as the training proceeds. A range of experiments conducted on the VoxCeleb1 evaluation protocol demonstrate the effectiveness of both the DINO framework on speaker verification and our proposed curriculum learning strategies. We report the state-of-the-art equal error rate of 4.47% with a single-phase training.