 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Session Variability: Leveraging Session Embeddings for Session Robustness in Speaker Verification
Sep 26, 2023

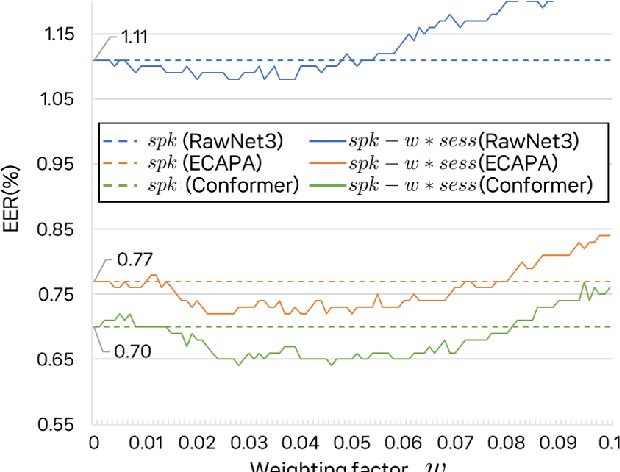
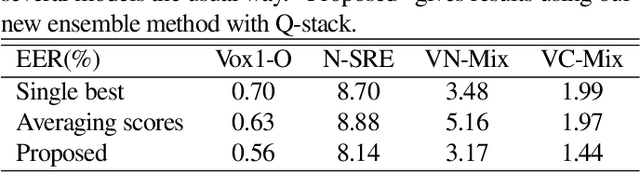
In the field of speaker verification, session or channel variability poses a significant challenge. While many contemporary methods aim to disentangle session information from speaker embeddings, we introduce a novel approach using an additional embedding to represent the session information. This is achieved by training an auxiliary network appended to the speaker embedding extractor which remains fixed in this training process. This results in two similarity scores: one for the speakers information and one for the session information. The latter score acts as a compensator for the former that might be skewed due to session variations. Our extensive experiments demonstrate that session information can be effectively compensated without retraining of the embedding extractor.
Absolute decision corrupts absolutely: conservative online speaker diarisation
Nov 09, 2022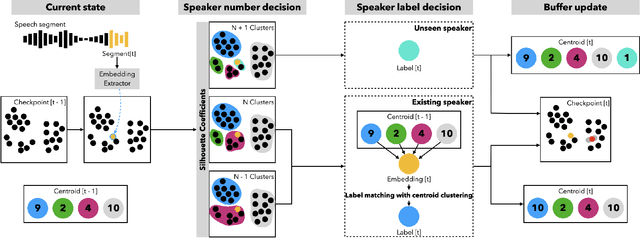
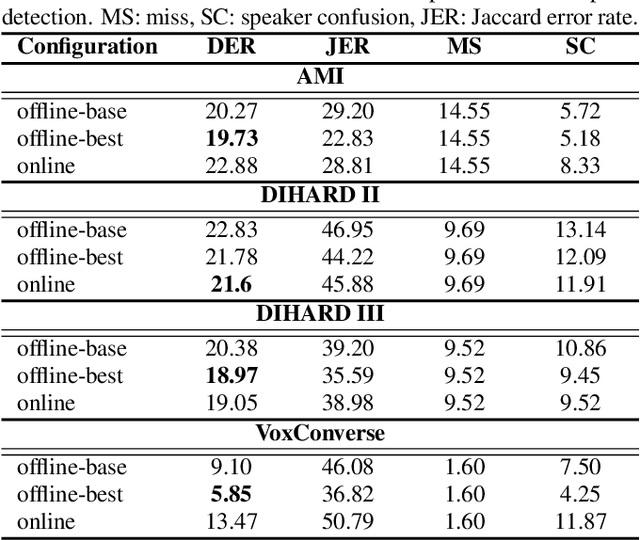
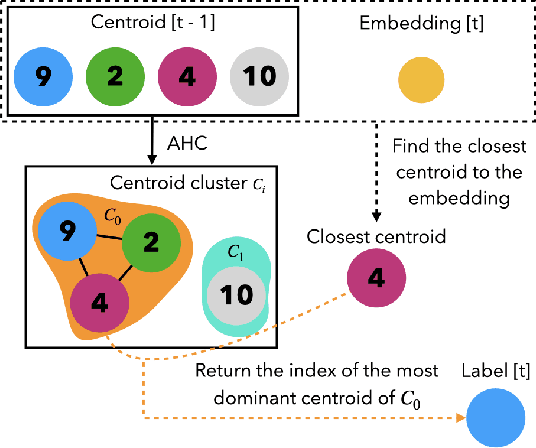
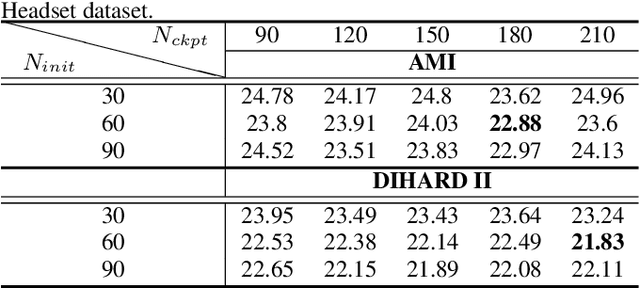
Our focus lies in developing an online speaker diarisation framework which demonstrates robust performance across diverse domains. In online speaker diarisation, outputs generated in real-time are irreversible, and a few misjudgements in the early phase of an input session can lead to catastrophic results. We hypothesise that cautiously increasing the number of estimated speakers is of paramount importance among many other factors. Thus, our proposed framework includes decreasing the number of speakers by one when the system judges that an increase in the past was faulty. We also adopt dual buffers, checkpoints and centroids, where checkpoints are combined with silhouette coefficients to estimate the number of speakers and centroids represent speakers. Again, we believe that more than one centroid can be generated from one speaker. Thus we design a clustering-based label matching technique to assign labels in real-time. The resulting system is lightweight yet surprisingly effective. The system demonstrates state-of-the-art performance on DIHARD 2 and 3 datasets, where it is also competitive in AMI and VoxConverse test sets.
High-resolution embedding extractor for speaker diarisation
Nov 08, 2022

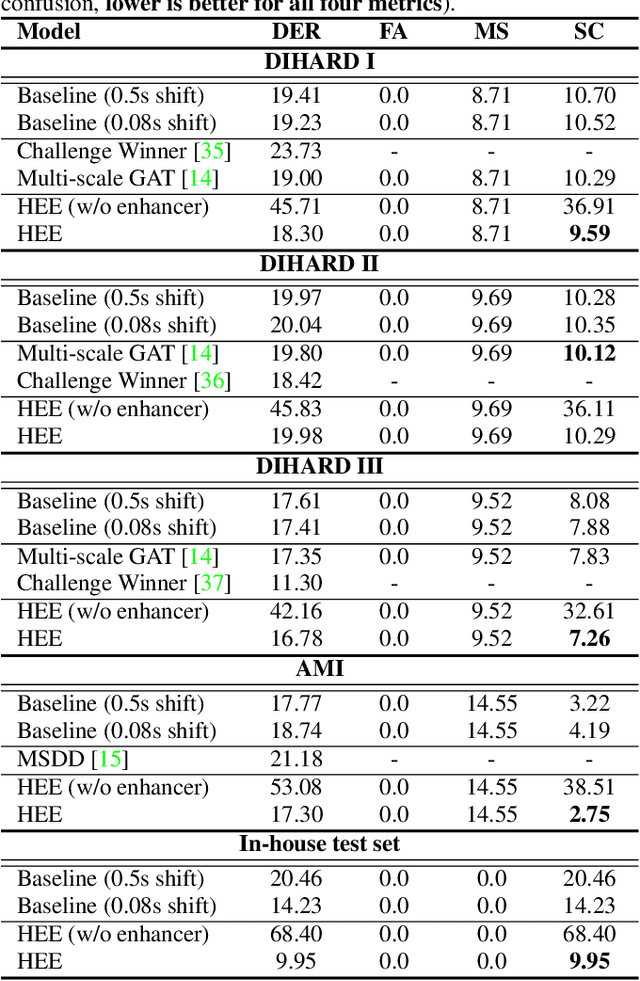
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.
In search of strong embedding extractors for speaker diarisation
Oct 26, 2022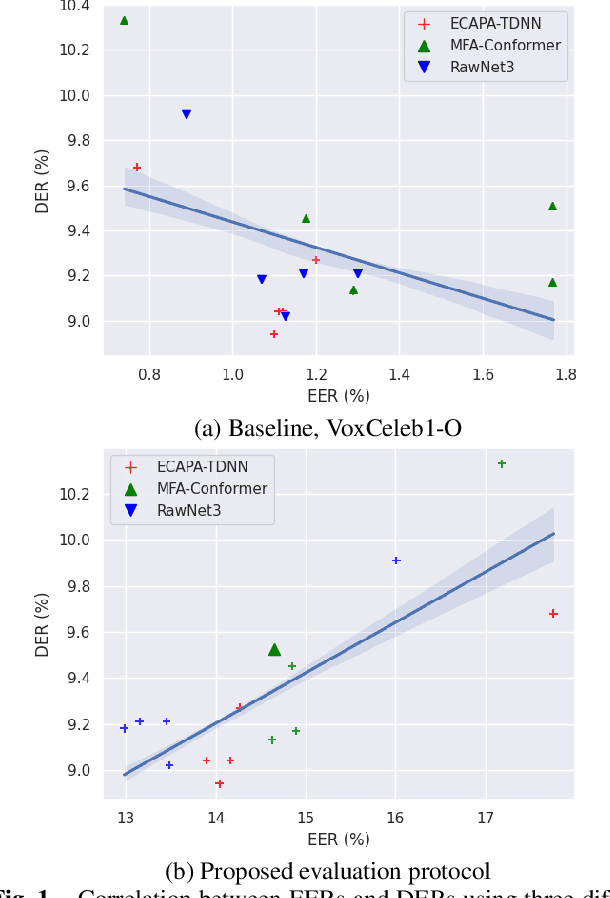
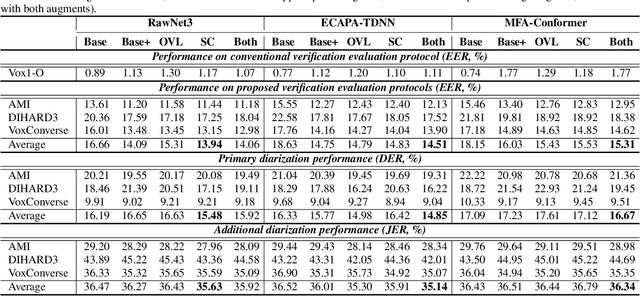
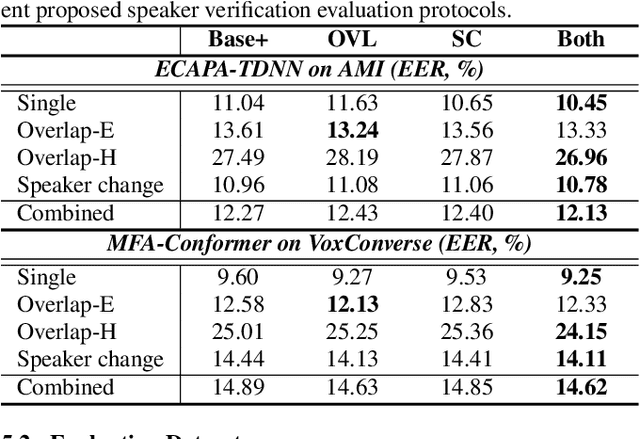
Speaker embedding extractors (EEs), which map input audio to a speaker discriminant latent space, are of paramount importance in speaker diarisation. However, there are several challenges when adopting EEs for diarisation, from which we tackle two key problems. First, the evaluation is not straightforward because the features required for better performance differ between speaker verification and diarisation. We show that better performance on widely adopted speaker verification evaluation protocols does not lead to better diarisation performance. Second, embedding extractors have not seen utterances in which multiple speakers exist. These inputs are inevitably present in speaker diarisation because of overlapped speech and speaker changes; they degrade the performance. To mitigate the first problem, we generate speaker verification evaluation protocols that mimic the diarisation scenario better. We propose two data augmentation techniques to alleviate the second problem, making embedding extractors aware of overlapped speech or speaker change input. One technique generates overlapped speech segments, and the other generates segments where two speakers utter sequentially. Extensive experimental results using three state-of-the-art speaker embedding extractors demonstrate that both proposed approaches are effective.
Self-supervised curriculum learning for speaker verification
Apr 05, 2022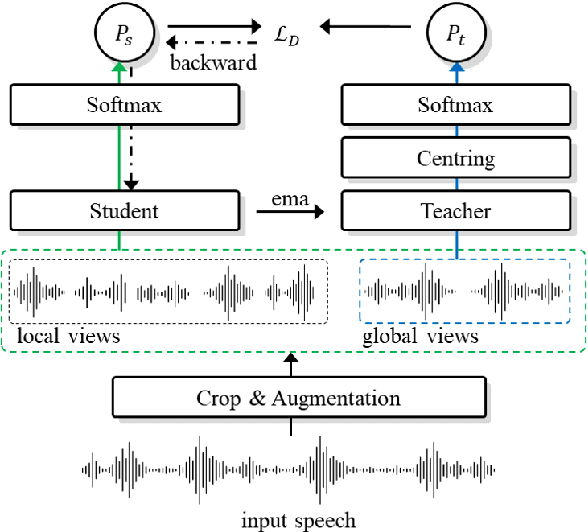
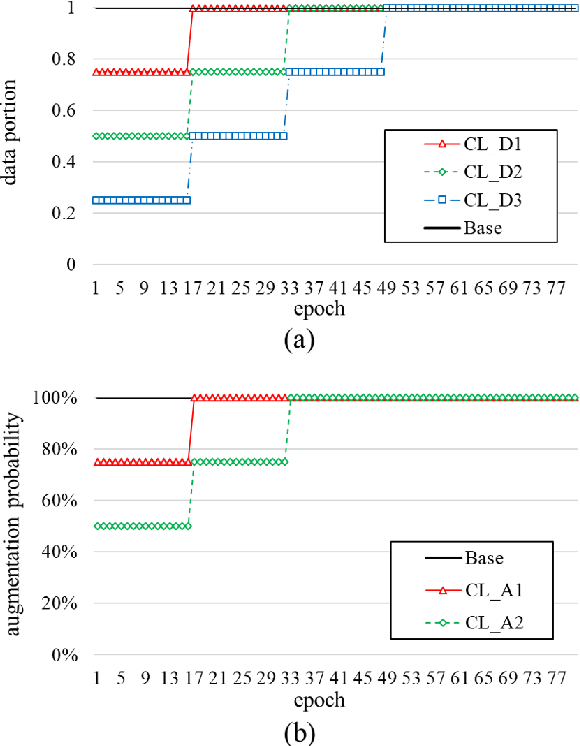
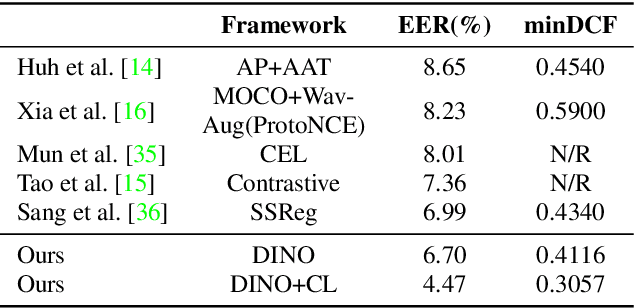
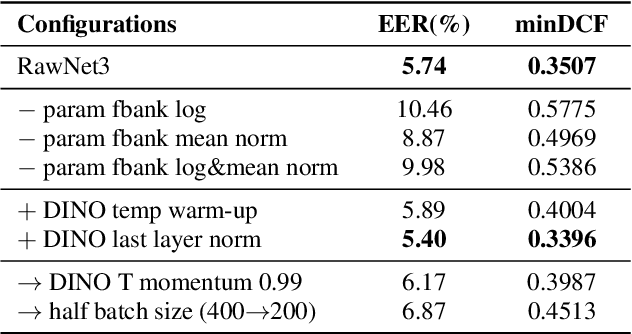
Self-supervised learning is one of the emerging approaches to machine learning today, and has been successfully applied to vision, speech and natural processing tasks. There is a range of frameworks within self-supervised learning literature, but the speaker recognition literature has particularly adopted self-supervision via contrastive loss functions. Our work adapts the DINO framework for speaker recognition, in which the model is trained without exploiting negative utterance pairs. We introduce a curriculum learning strategy to the self-supervised framework, which guides effective training of speaker recognition models. In particular, we propose two curriculum strategies where one gradually increases the number of speakers in training dataset, and the other gradually applies augmentations to more utterances within a mini-batch as the training proceeds. A range of experiments conducted on the VoxCeleb1 evaluation protocol demonstrate the effectiveness of both the DINO framework on speaker verification and our proposed curriculum learning strategies. We report the state-of-the-art equal error rate of 4.47% with a single-phase training.
Pushing the limits of raw waveform speaker recognition
Mar 29, 2022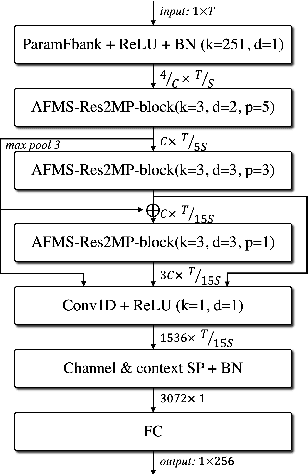
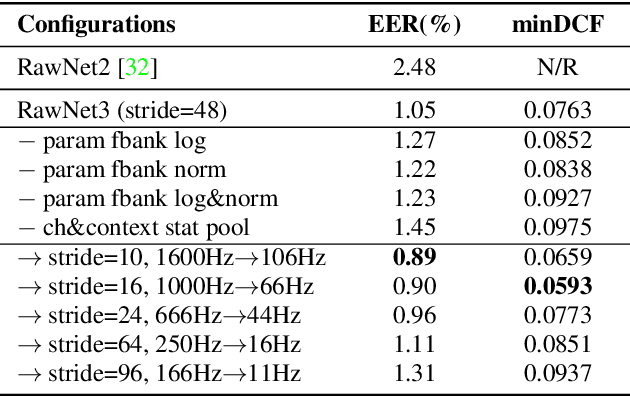
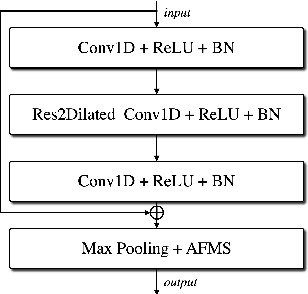
In recent years, speaker recognition systems based on raw waveform inputs have received increasing attention. However, the performance of such systems are typically inferior to the state-of-the-art handcrafted feature-based counterparts, which demonstrate equal error rates under 1% on the popular VoxCeleb1 test set. This paper proposes a novel speaker recognition model based on raw waveform inputs. The model incorporates recent advances in machine learning and speaker verification, including the Res2Net backbone module and multi-layer feature aggregation. Our best model achieves an equal error rate of 0.89%, which is competitive with the state-of-the-art models based on handcrafted features, and outperforms the best model based on raw waveform inputs by a large margin. We also explore the application of the proposed model in the context of self-supervised learning framework. Our self-supervised model outperforms single phase-based existing works in this line of research. Finally, we show that self-supervised pre-training is effective for the semi-supervised scenario where we only have a small set of labelled training data, along with a larger set of unlabelled examples.
Disentangled dimensionality reduction for noise-robust speaker diarisation
Oct 07, 2021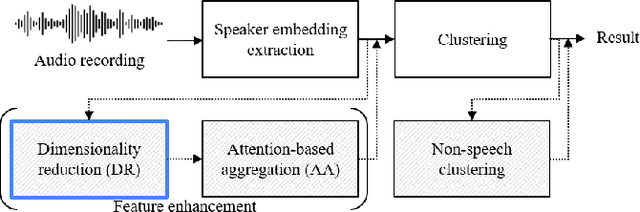
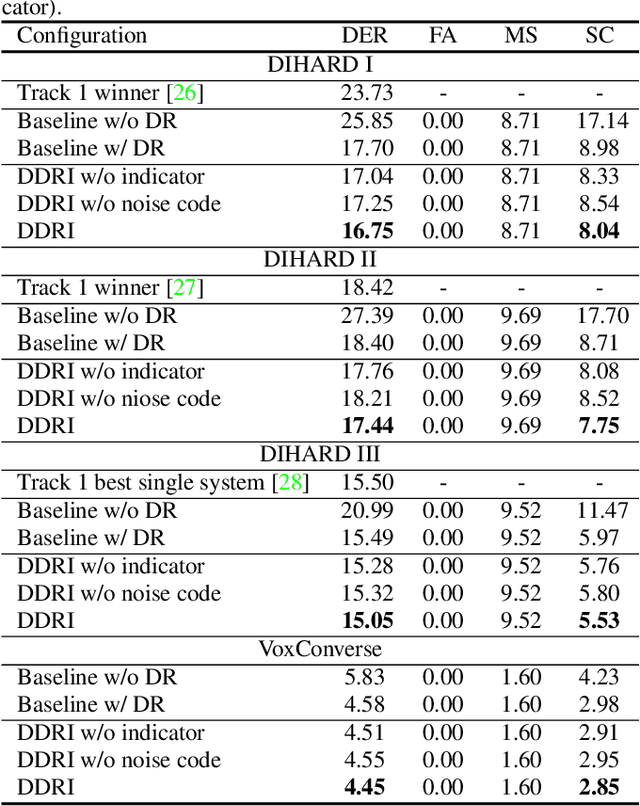
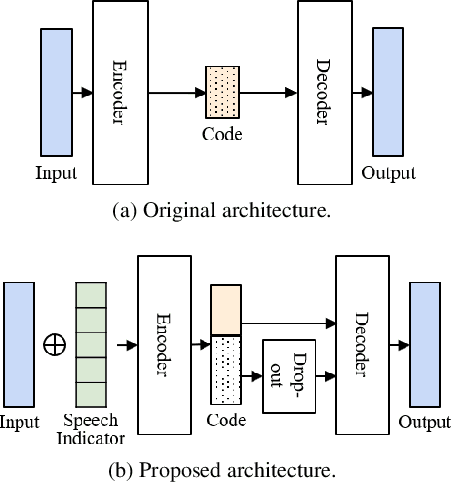

The objective of this work is to train noise-robust speaker embeddings for speaker diarisation. Speaker embeddings play a crucial role in the performance of diarisation systems, but they often capture spurious information such as noise and reverberation, adversely affecting performance. Our previous work have proposed an auto-encoder-based dimensionality reduction module to help remove the spurious information. However, they do not explicitly separate such information and have also been found to be sensitive to hyperparameter values. To this end, we propose two contributions to overcome these issues: (i) a novel dimensionality reduction framework that can disentangle spurious information from the speaker embeddings; (ii) the use of a speech/non-speech indicator to prevent the speaker code from learning from the background noise. Through a range of experiments conducted on four different datasets, our approach consistently demonstrates the state-of-the-art performance among models that do not adopt ensembles.
Multi-scale speaker embedding-based graph attention networks for speaker diarisation
Oct 07, 2021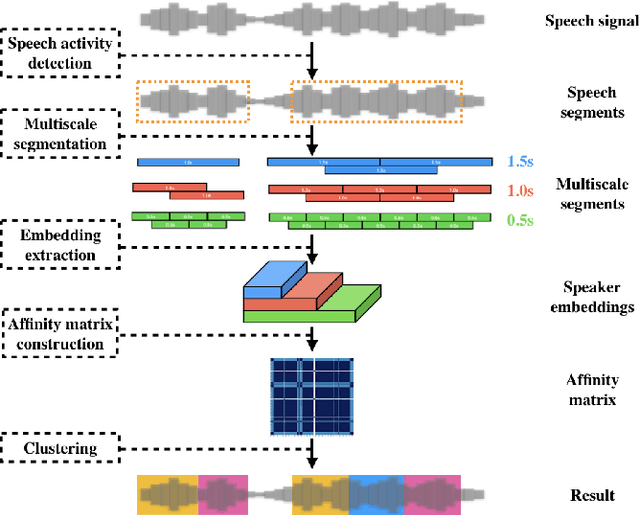
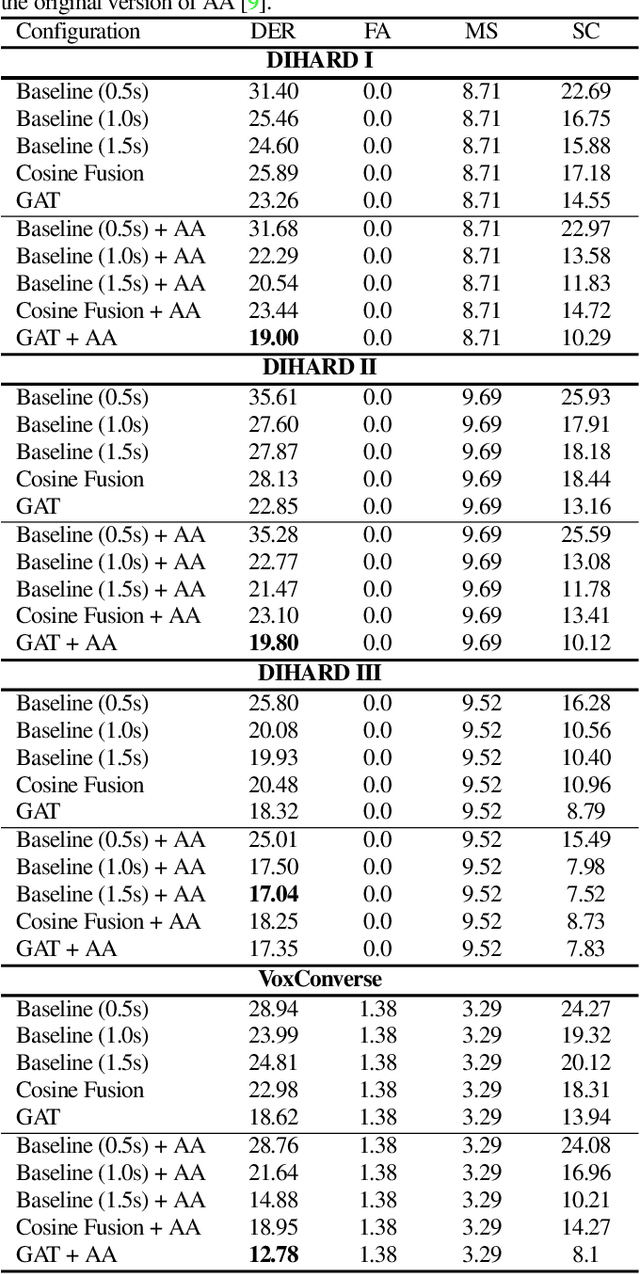
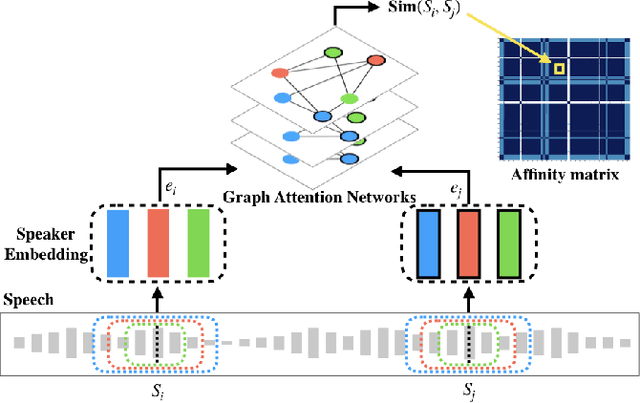
The objective of this work is effective speaker diarisation using multi-scale speaker embeddings. Typically, there is a trade-off between the ability to recognise short speaker segments and the discriminative power of the embedding, according to the segment length used for embedding extraction. To this end, recent works have proposed the use of multi-scale embeddings where segments with varying lengths are used. However, the scores are combined using a weighted summation scheme where the weights are fixed after the training phase, whereas the importance of segment lengths can differ with in a single session. To address this issue, we present three key contributions in this paper: (1) we propose graph attention networks for multi-scale speaker diarisation; (2) we design scale indicators to utilise scale information of each embedding; (3) we adapt the attention-based aggregation to utilise a pre-computed affinity matrix from multi-scale embeddings. We demonstrate the effectiveness of our method in various datasets where the speaker confusion which constitutes the primary metric drops over 10% in average relative compared to the baseline.
Look Who's Talking: Active Speaker Detection in the Wild
Aug 17, 2021


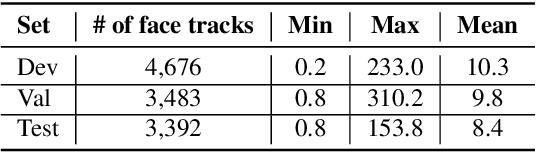
In this work, we present a novel audio-visual dataset for active speaker detection in the wild. A speaker is considered active when his or her face is visible and the voice is audible simultaneously. Although active speaker detection is a crucial pre-processing step for many audio-visual tasks, there is no existing dataset of natural human speech to evaluate the performance of active speaker detection. We therefore curate the Active Speakers in the Wild (ASW) dataset which contains videos and co-occurring speech segments with dense speech activity labels. Videos and timestamps of audible segments are parsed and adopted from VoxConverse, an existing speaker diarisation dataset that consists of videos in the wild. Face tracks are extracted from the videos and active segments are annotated based on the timestamps of VoxConverse in a semi-automatic way. Two reference systems, a self-supervised system and a fully supervised one, are evaluated on the dataset to provide the baseline performances of ASW. Cross-domain evaluation is conducted in order to show the negative effect of dubbed videos in the training data.
Adapting Speaker Embeddings for Speaker Diarisation
Apr 07, 2021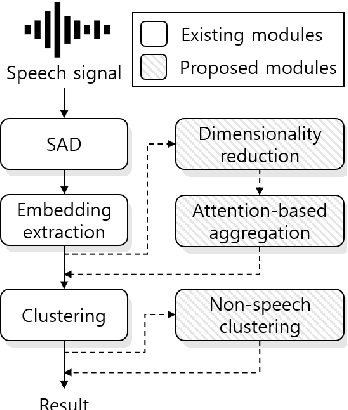
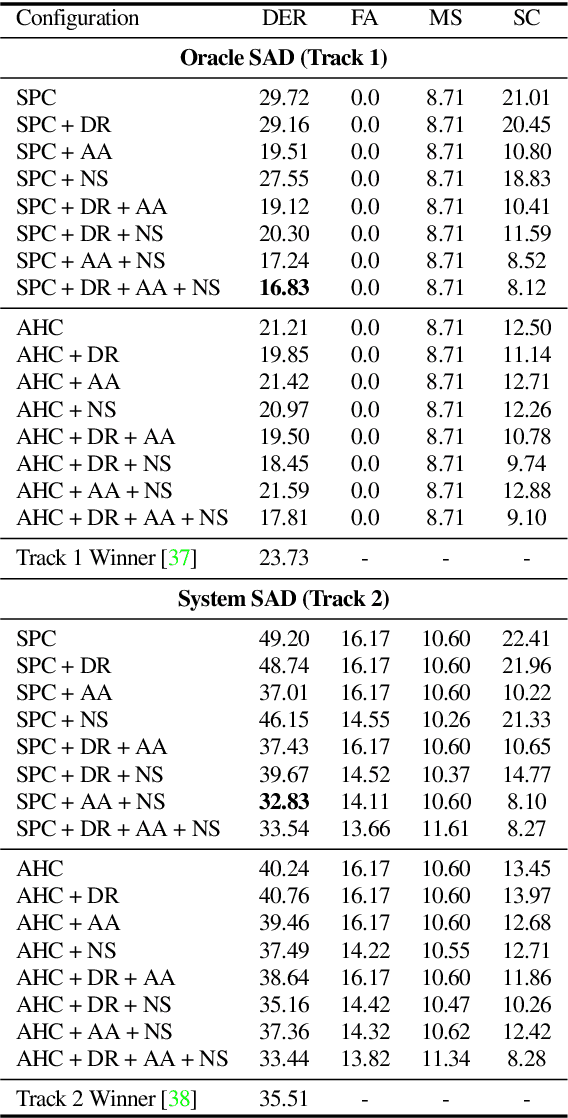
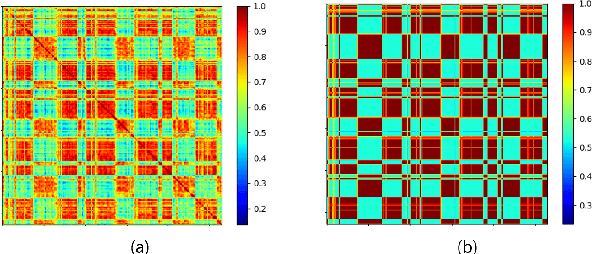
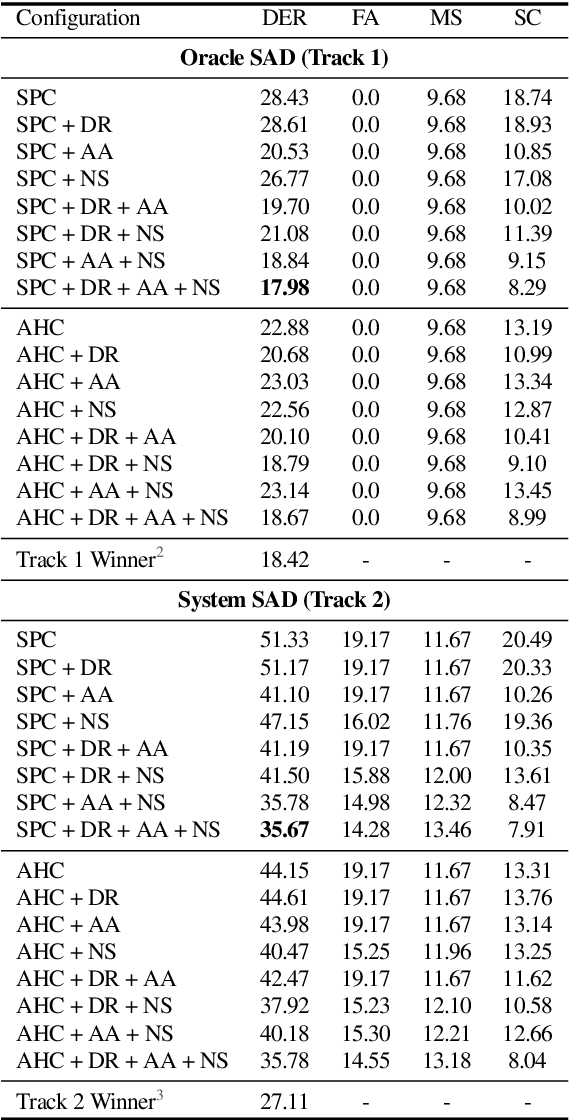
The goal of this paper is to adapt speaker embeddings for solving the problem of speaker diarisation. The quality of speaker embeddings is paramount to the performance of speaker diarisation systems. Despite this, prior works in the field have directly used embeddings designed only to be effective on the speaker verification task. In this paper, we propose three techniques that can be used to better adapt the speaker embeddings for diarisation: dimensionality reduction, attention-based embedding aggregation, and non-speech clustering. A wide range of experiments is performed on various challenging datasets. The results demonstrate that all three techniques contribute positively to the performance of the diarisation system achieving an average relative improvement of 25.07% in terms of diarisation error rate over the baseline.