 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-resolution embedding extractor for speaker diarisation
Paper and Code
Nov 08, 2022
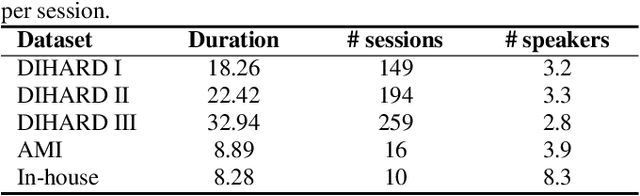

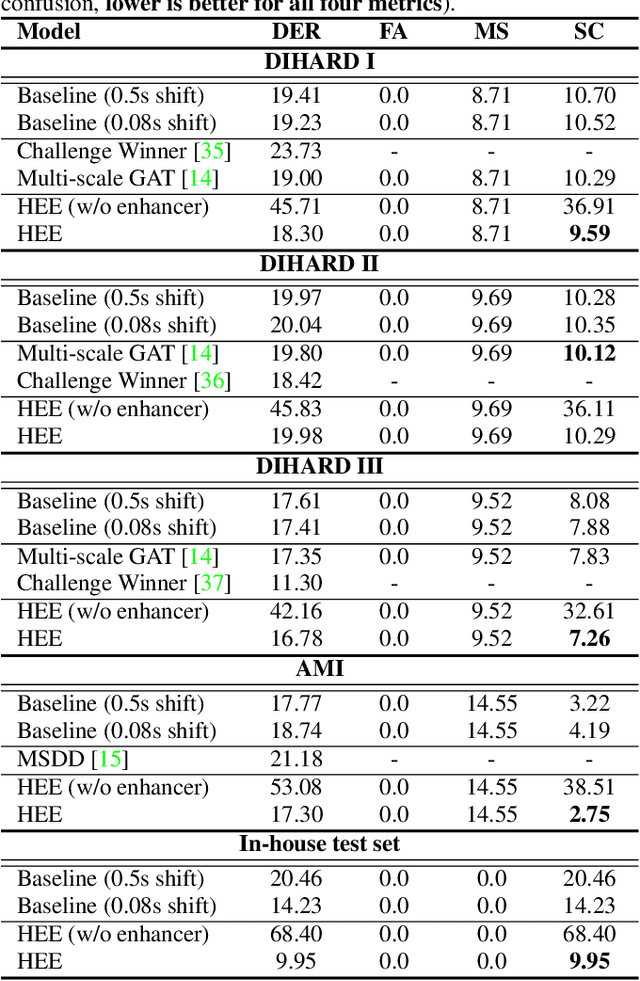
Speaker embedding extractors significantly influence the performance of clustering-based speaker diarisation systems. Conventionally, only one embedding is extracted from each speech segment. However, because of the sliding window approach, a segment easily includes two or more speakers owing to speaker change points. This study proposes a novel embedding extractor architecture, referred to as a high-resolution embedding extractor (HEE), which extracts multiple high-resolution embeddings from each speech segment. Hee consists of a feature-map extractor and an enhancer, where the enhancer with the self-attention mechanism is the key to success. The enhancer of HEE replaces the aggregation process; instead of a global pooling layer, the enhancer combines relative information to each frame via attention leveraging the global context. Extracted dense frame-level embeddings can each represent a speaker. Thus, multiple speakers can be represented by different frame-level features in each segment. We also propose an artificially generating mixture data training framework to train the proposed HEE. Through experiments on five evaluation sets, including four public datasets, the proposed HEE demonstrates at least 10% improvement on each evaluation set, except for one dataset, which we analyse that rapid speaker changes less exist.