 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-based Attractors and Cross-attention in Spoof Diarization
Sep 16, 2025Spoof diarization identifies ``what spoofed when" in a given speech by temporally locating spoofed regions and determining their manipulation techniques. As a first step toward this task, prior work proposed a two-branch model for localization and spoof type clustering, which laid the foundation for spoof diarization. However, its simple structure limits the ability to capture complex spoofing patterns and lacks explicit reference points for distinguishing between bona fide and various spoofing types. To address these limitations, our approach introduces learnable tokens where each token represents acoustic features of bona fide and spoofed speech. These attractors interact with frame-level embeddings to extract discriminative representations, improving separation between genuine and generated speech. Vast experiments on PartialSpoof dataset consistently demonstrate that our approach outperforms existing methods in bona fide detection and spoofing method clustering.
WildSpoof Challenge Evaluation Plan
Aug 23, 2025The WildSpoof Challenge aims to advance the use of in-the-wild data in two intertwined speech processing tasks. It consists of two parallel tracks: (1) Text-to-Speech (TTS) synthesis for generating spoofed speech, and (2) Spoofing-robust Automatic Speaker Verification (SASV) for detecting spoofed speech. While the organizers coordinate both tracks and define the data protocols, participants treat them as separate and independent tasks. The primary objectives of the challenge are: (i) to promote the use of in-the-wild data for both TTS and SASV, moving beyond conventional clean and controlled datasets and considering real-world scenarios; and (ii) to encourage interdisciplinary collaboration between the spoofing generation (TTS) and spoofing detection (SASV) communities, thereby fostering the development of more integrated, robust, and realistic systems.
Context-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
SEED: Speaker Embedding Enhancement Diffusion Model
May 22, 2025A primary challenge when deploying speaker recognition systems in real-world applications is performance degradation caused by environmental mismatch. We propose a diffusion-based method that takes speaker embeddings extracted from a pre-trained speaker recognition model and generates refined embeddings. For training, our approach progressively adds Gaussian noise to both clean and noisy speaker embeddings extracted from clean and noisy speech, respectively, via forward process of a diffusion model, and then reconstructs them to clean embeddings in the reverse process. While inferencing, all embeddings are regenerated via diffusion process. Our method needs neither speaker label nor any modification to the existing speaker recognition pipeline. Experiments on evaluation sets simulating environment mismatch scenarios show that our method can improve recognition accuracy by up to 19.6% over baseline models while retaining performance on conventional scenarios. We publish our code here https://github.com/kaistmm/seed-pytorch
ASVspoof 5: Design, Collection and Validation of Resources for Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Feb 13, 2025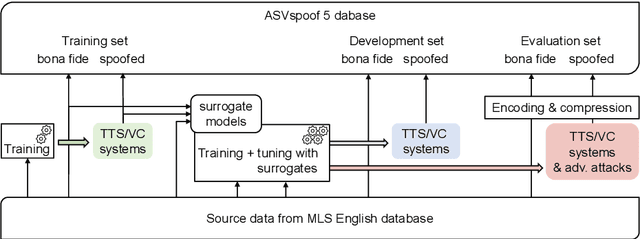

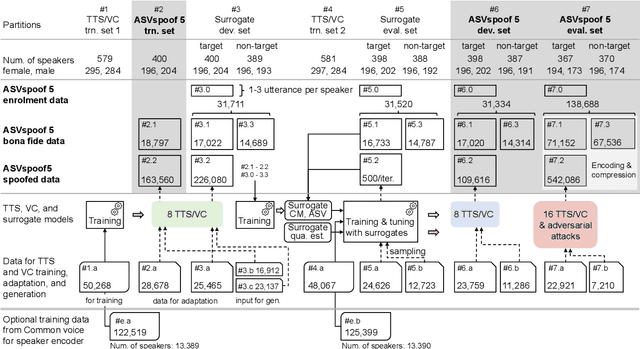
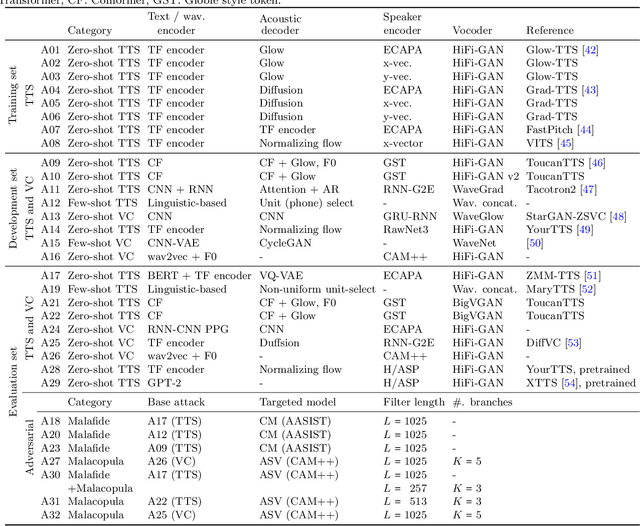
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake attacks as well as the design of detection solutions. We introduce the ASVspoof 5 database which is generated in crowdsourced fashion from data collected in diverse acoustic conditions (cf. studio-quality data for earlier ASVspoof databases) and from ~2,000 speakers (cf. ~100 earlier). The database contains attacks generated with 32 different algorithms, also crowdsourced, and optimised to varying degrees using new surrogate detection models. Among them are attacks generated with a mix of legacy and contemporary text-to-speech synthesis and voice conversion models, in addition to adversarial attacks which are incorporated for the first time. ASVspoof 5 protocols comprise seven speaker-disjoint partitions. They include two distinct partitions for the training of different sets of attack models, two more for the development and evaluation of surrogate detection models, and then three additional partitions which comprise the ASVspoof 5 training, development and evaluation sets. An auxiliary set of data collected from an additional 30k speakers can also be used to train speaker encoders for the implementation of attack algorithms. Also described herein is an experimental validation of the new ASVspoof 5 database using a set of automatic speaker verification and spoof/deepfake baseline detectors. With the exception of protocols and tools for the generation of spoofed/deepfake speech, the resources described in this paper, already used by participants of the ASVspoof 5 challenge in 2024, are now all freely available to the community.
ESPnet-Codec: Comprehensive Training and Evaluation of Neural Codecs for Audio, Music, and Speech
Sep 24, 2024Neural codecs have become crucial to recent speech and audio generation research. In addition to signal compression capabilities, discrete codecs have also been found to enhance downstream training efficiency and compatibility with autoregressive language models. However, as extensive downstream applications are investigated, challenges have arisen in ensuring fair comparisons across diverse applications. To address these issues, we present a new open-source platform ESPnet-Codec, which is built on ESPnet and focuses on neural codec training and evaluation. ESPnet-Codec offers various recipes in audio, music, and speech for training and evaluation using several widely adopted codec models. Together with ESPnet-Codec, we present VERSA, a standalone evaluation toolkit, which provides a comprehensive evaluation of codec performance over 20 audio evaluation metrics. Notably, we demonstrate that ESPnet-Codec can be integrated into six ESPnet tasks, supporting diverse applications.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Text-To-Speech Synthesis In The Wild
Sep 13, 2024Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.
The VoxCeleb Speaker Recognition Challenge: A Retrospective
Aug 27, 2024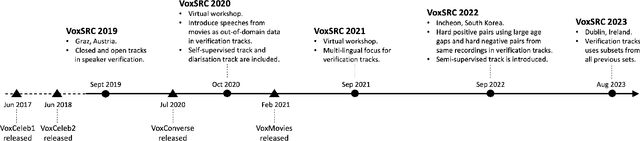
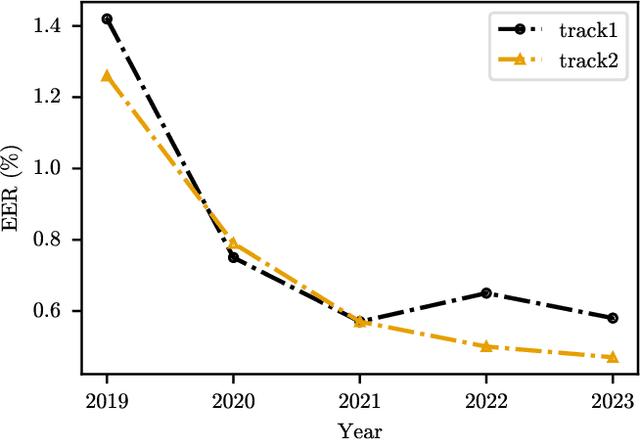
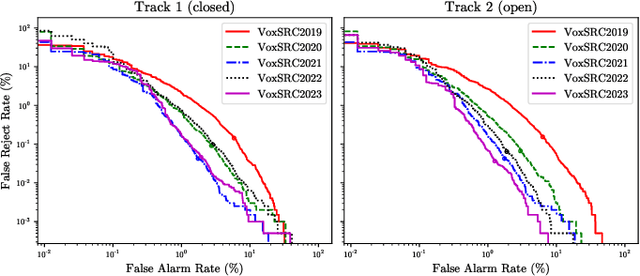
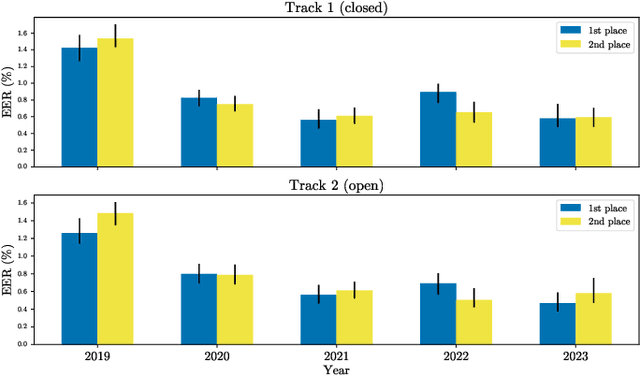
The VoxCeleb Speaker Recognition Challenges (VoxSRC) were a series of challenges and workshops that ran annually from 2019 to 2023. The challenges primarily evaluated the tasks of speaker recognition and diarisation under various settings including: closed and open training data; as well as supervised, self-supervised, and semi-supervised training for domain adaptation. The challenges also provided publicly available training and evaluation datasets for each task and setting, with new test sets released each year. In this paper, we provide a review of these challenges that covers: what they explored; the methods developed by the challenge participants and how these evolved; and also the current state of the field for speaker verification and diarisation. We chart the progress in performance over the five installments of the challenge on a common evaluation dataset and provide a detailed analysis of how each year's special focus affected participants' performance. This paper is aimed both at researchers who want an overview of the speaker recognition and diarisation field, and also at challenge organisers who want to benefit from the successes and avoid the mistakes of the VoxSRC challenges. We end with a discussion of the current strengths of the field and open challenges. Project page : https://mm.kaist.ac.kr/datasets/voxceleb/voxsrc/workshop.html
ASVspoof 5: Crowdsourced Speech Data, Deepfakes, and Adversarial Attacks at Scale
Aug 16, 2024



ASVspoof 5 is the fifth edition in a series of challenges that promote the study of speech spoofing and deepfake attacks, and the design of detection solutions. Compared to previous challenges, the ASVspoof 5 database is built from crowdsourced data collected from a vastly greater number of speakers in diverse acoustic conditions. Attacks, also crowdsourced, are generated and tested using surrogate detection models, while adversarial attacks are incorporated for the first time. New metrics support the evaluation of spoofing-robust automatic speaker verification (SASV) as well as stand-alone detection solutions, i.e., countermeasures without ASV. We describe the two challenge tracks, the new database, the evaluation metrics, baselines, and the evaluation platform, and present a summary of the results. Attacks significantly compromise the baseline systems, while submissions bring substantial improvements.