 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
A Novel Self-Supervised Cross-Modal Image Retrieval Method In Remote Sensing
Feb 23, 2022
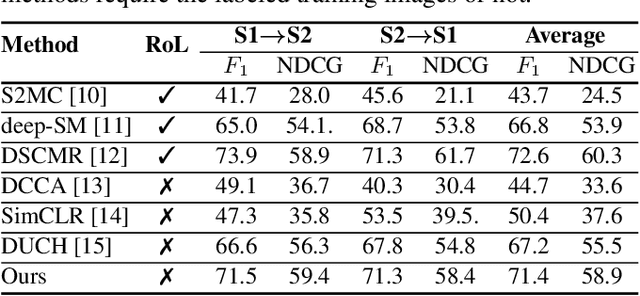

Due to the availability of multi-modal remote sensing (RS) image archives, one of the most important research topics is the development of cross-modal RS image retrieval (CM-RSIR) methods that search semantically similar images across different modalities. Existing CM-RSIR methods require annotated training images (which is time-consuming, costly and not feasible to gather in large-scale applications) and do not concurrently address intra- and inter-modal similarity preservation and inter-modal discrepancy elimination. In this paper, we introduce a novel self-supervised cross-modal image retrieval method that aims to: i) model mutual-information between different modalities in a self-supervised manner; ii) retain the distributions of modal-specific feature spaces similar; and iii) define most similar images within each modality without requiring any annotated training images. To this end, we propose a novel objective including three loss functions that simultaneously: i) maximize mutual information of different modalities for inter-modal similarity preservation; ii) minimize the angular distance of multi-modal image tuples for the elimination of inter-modal discrepancies; and iii) increase cosine similarity of most similar images within each modality for the characterization of intra-modal similarities. Experimental results show the effectiveness of the proposed method compared to state-of-the-art methods. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/SS-CM-RSIR.
Tie Your Embeddings Down: Cross-Modal Latent Spaces for End-to-end Spoken Language Understanding
Nov 18, 2020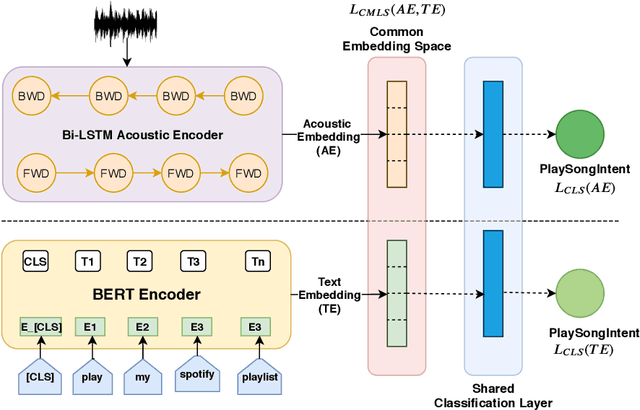

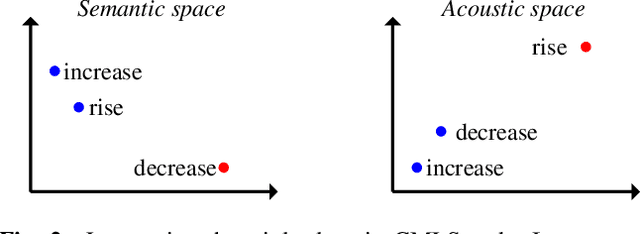

End-to-end (E2E) spoken language understanding (SLU) systems can infer the semantics of a spoken utterance directly from an audio signal. However, training an E2E system remains a challenge, largely due to the scarcity of paired audio-semantics data. In this paper, we treat an E2E system as a multi-modal model, with audio and text functioning as its two modalities, and use a cross-modal latent space (CMLS) architecture, where a shared latent space is learned between the `acoustic' and `text' embeddings. We propose using different multi-modal losses to explicitly guide the acoustic embeddings to be closer to the text embeddings, obtained from a semantically powerful pre-trained BERT model. We train the CMLS model on two publicly available E2E datasets, across different cross-modal losses and show that our proposed triplet loss function achieves the best performance. It achieves a relative improvement of 1.4% and 4% respectively over an E2E model without a cross-modal space and a relative improvement of 0.7% and 1% over a previously published CMLS model using $L_2$ loss. The gains are higher for a smaller, more complicated E2E dataset, demonstrating the efficacy of using an efficient cross-modal loss function, especially when there is limited E2E training data available.
Streaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020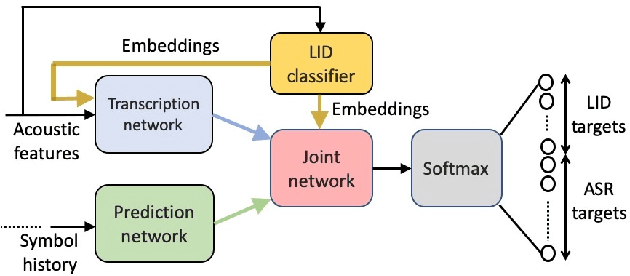
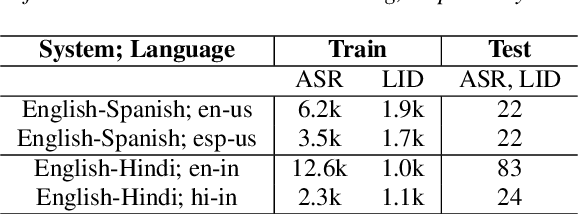
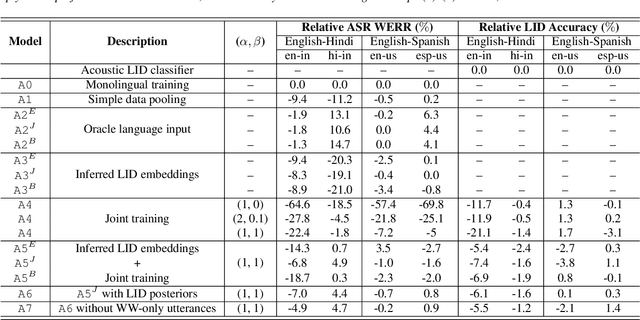
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Very Deep Self-Attention Networks for End-to-End Speech Recognition
May 03, 2019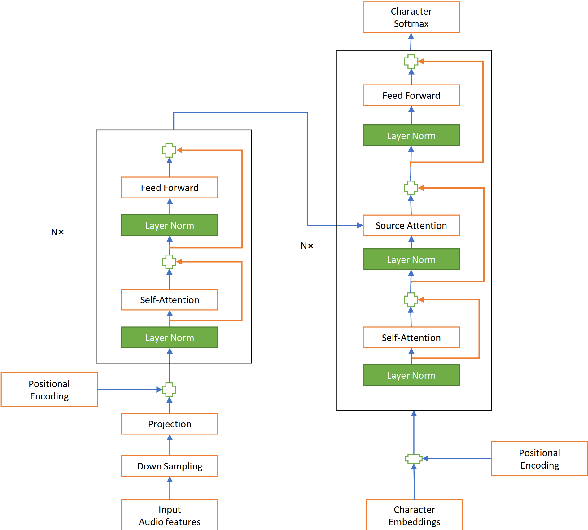
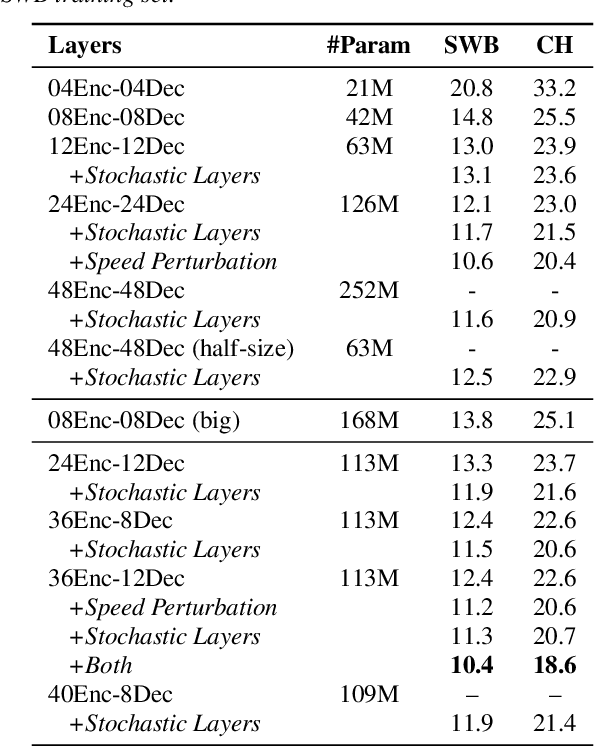
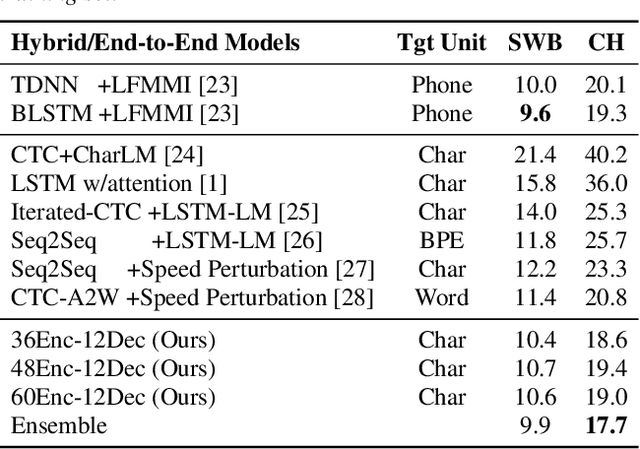

Recently, end-to-end sequence-to-sequence models for speech recognition have gained significant interest in the research community. While previous architecture choices revolve around time-delay neural networks (TDNN) and long short-term memory (LSTM) recurrent neural networks, we propose to use self-attention via the Transformer architecture as an alternative. Our analysis shows that deep Transformer networks with high learning capacity are able to exceed performance from previous end-to-end approaches and even match the conventional hybrid systems. Moreover, we trained very deep models with up to 48 Transformer layers for both encoder and decoders combined with stochastic residual connections, which greatly improve generalizability and training efficiency. The resulting models outperform all previous end-to-end ASR approaches on the Switchboard benchmark. An ensemble of these models achieve 9.9% and 17.7% WER on Switchboard and CallHome test sets respectively. This finding brings our end-to-end models to competitive levels with previous hybrid systems. Further, with model ensembling the Transformers can outperform certain hybrid systems, which are more complicated in terms of both structure and training procedure.
Neural Language Codes for Multilingual Acoustic Models
Jul 05, 2018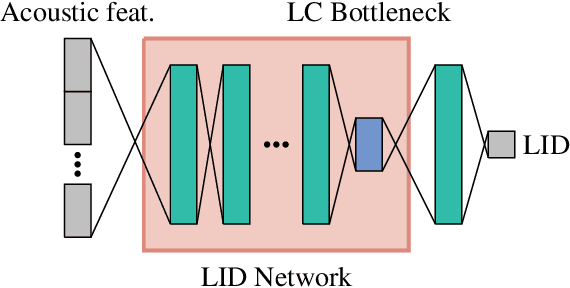
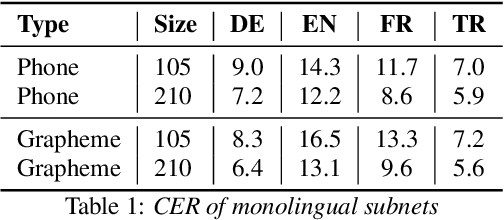
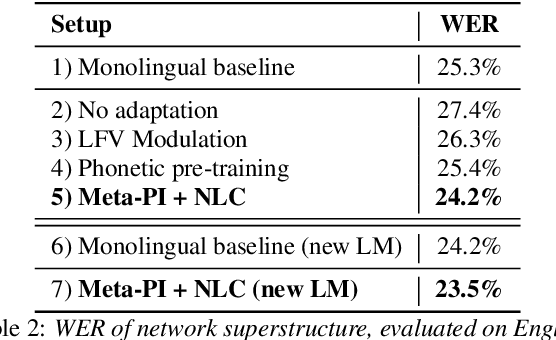
Multilingual Speech Recognition is one of the most costly AI problems, because each language (7,000+) and even different accents require their own acoustic models to obtain best recognition performance. Even though they all use the same phoneme symbols, each language and accent imposes its own coloring or "twang". Many adaptive approaches have been proposed, but they require further training, additional data and generally are inferior to monolingually trained models. In this paper, we propose a different approach that uses a large multilingual model that is \emph{modulated} by the codes generated by an ancillary network that learns to code useful differences between the "twangs" or human language. We use Meta-Pi networks to have one network (the language code net) gate the activity of neurons in another (the acoustic model nets). Our results show that during recognition multilingual Meta-Pi networks quickly adapt to the proper language coloring without retraining or new data, and perform better than monolingually trained networks. The model was evaluated by training acoustic modeling nets and modulating language code nets jointly and optimize them for best recognition performance.
Multilingual Adaptation of RNN Based ASR Systems
Feb 27, 2018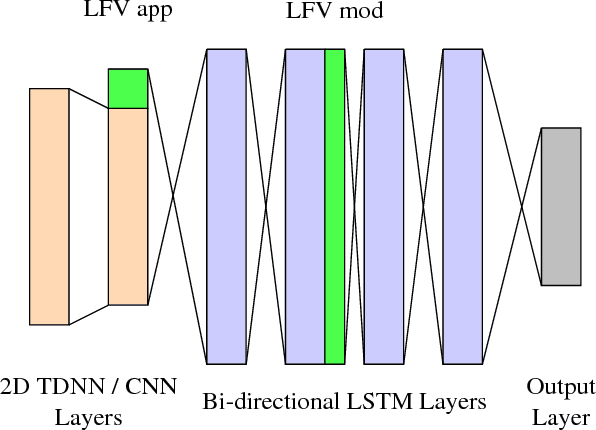
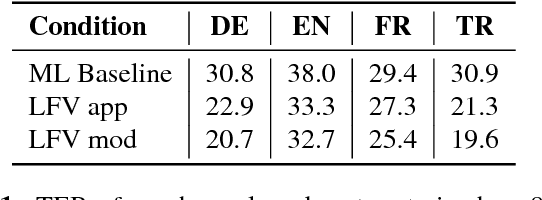
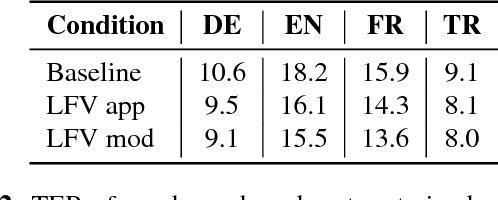
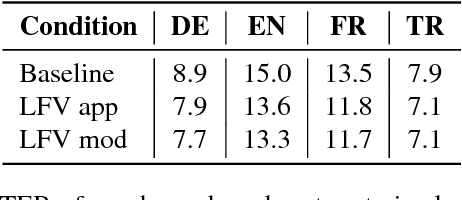
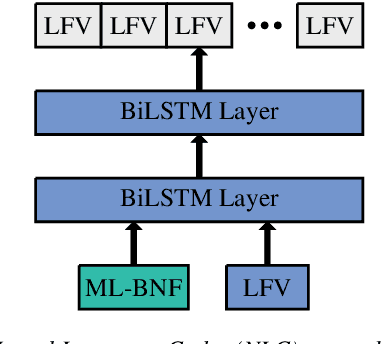
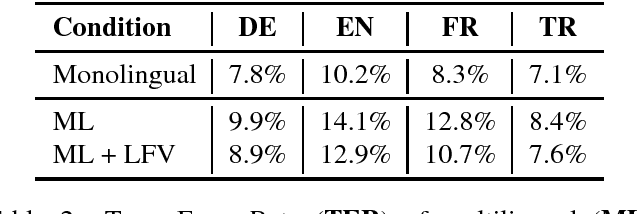
In this work, we focus on multilingual systems based on recurrent neural networks (RNNs), trained using the Connectionist Temporal Classification (CTC) loss function. Using a multilingual set of acoustic units poses difficulties. To address this issue, we proposed Language Feature Vectors (LFVs) to train language adaptive multilingual systems. Language adaptation, in contrast to speaker adaptation, needs to be applied not only on the feature level, but also to deeper layers of the network. In this work, we therefore extended our previous approach by introducing a novel technique which we call "modulation". Based on this method, we modulated the hidden layers of RNNs using LFVs. We evaluated this approach in both full and low resource conditions, as well as for grapheme and phone based systems. Lower error rates throughout the different conditions could be achieved by the use of the modulation.
Phonemic and Graphemic Multilingual CTC Based Speech Recognition
Nov 13, 2017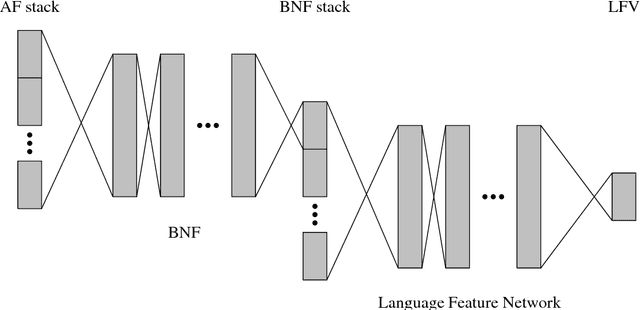
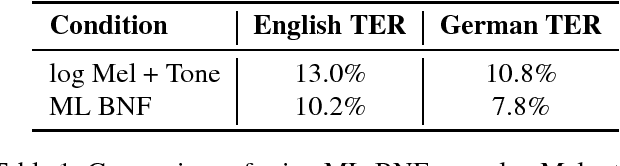
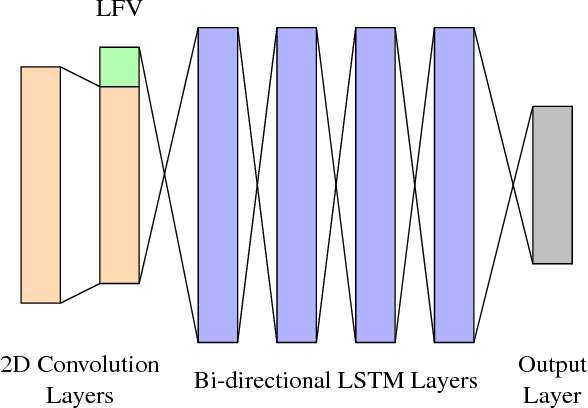
Training automatic speech recognition (ASR) systems requires large amounts of data in the target language in order to achieve good performance. Whereas large training corpora are readily available for languages like English, there exists a long tail of languages which do suffer from a lack of resources. One method to handle data sparsity is to use data from additional source languages and build a multilingual system. Recently, ASR systems based on recurrent neural networks (RNNs) trained with connectionist temporal classification (CTC) have gained substantial research interest. In this work, we extended our previous approach towards training CTC-based systems multilingually. Our systems feature a global phone set, based on the joint phone sets of each source language. We evaluated the use of different language combinations as well as the addition of Language Feature Vectors (LFVs). As contrastive experiment, we built systems based on graphemes as well. Systems having a multilingual phone set are known to suffer in performance compared to their monolingual counterparts. With our proposed approach, we could reduce the gap between these mono- and multilingual setups, using either graphemes or phonemes.
Yeah, Right, Uh-Huh: A Deep Learning Backchannel Predictor
Jun 02, 2017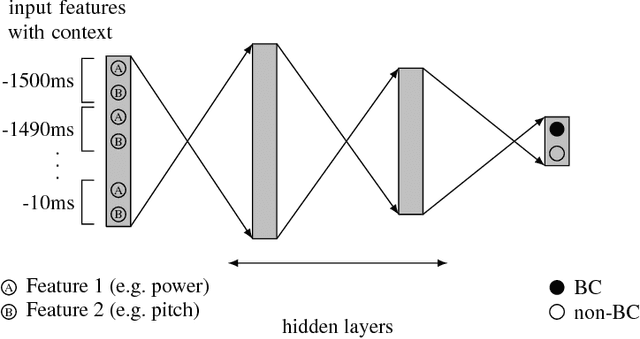
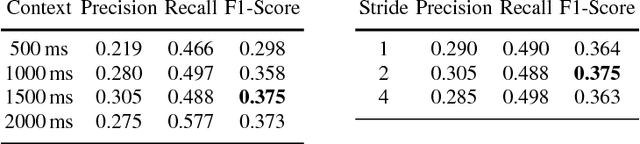
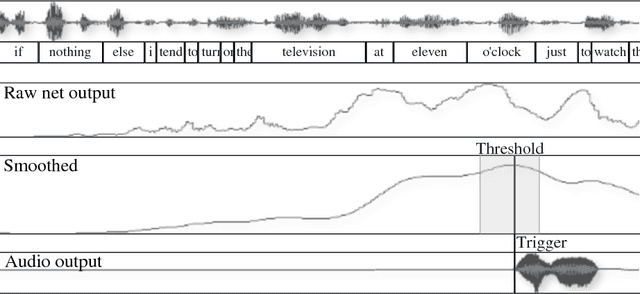

Using supporting backchannel (BC) cues can make human-computer interaction more social. BCs provide a feedback from the listener to the speaker indicating to the speaker that he is still listened to. BCs can be expressed in different ways, depending on the modality of the interaction, for example as gestures or acoustic cues. In this work, we only considered acoustic cues. We are proposing an approach towards detecting BC opportunities based on acoustic input features like power and pitch. While other works in the field rely on the use of a hand-written rule set or specialized features, we made use of artificial neural networks. They are capable of deriving higher order features from input features themselves. In our setup, we first used a fully connected feed-forward network to establish an updated baseline in comparison to our previously proposed setup. We also extended this setup by the use of Long Short-Term Memory (LSTM) networks which have shown to outperform feed-forward based setups on various tasks. Our best system achieved an F1-Score of 0.37 using power and pitch features. Adding linguistic information using word2vec, the score increased to 0.39.