 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigEarthNet.txt: A Large-Scale Multi-Sensor Image-Text Dataset and Benchmark for Earth Observation
Apr 01, 2026Vision-langugage models (VLMs) have shown strong performance in computer vision (CV), yet their performance on remote sensing (RS) data remains limited due to the lack of large-scale, multi-sensor RS image-text datasets with diverse textual annotations. Existing datasets predominantly include aerial Red-Green-Blue imagery, with short or weakly grounded captions, and provide limited diversity in annotation types. To address this limitation, we introduce BigEarthNet$.$txt, a large-scale, multi-sensor image-text dataset designed to advance instruction-driven image-text learning in Earth observation across multiple tasks. BigEarthNet$.$txt contains 464044 co-registered Sentinel-1 synthetic aperture radar and Sentinel-2 multispectral images with 9.6M text annotations, including: i) geographically anchored captions describing land-use/land-cover (LULC) classes, their spatial relations, and environmental context; ii) visual question answering pairs relevant for different tasks; and iii) referring expression detection instructions for bounding box prediction. Through a comparative statistical analysis, we demonstrate that BigEarthNet$.$txt surpasses existing RS image-text datasets in textual richness and annotation type variety. We further establish a manually-verified benchmark split to evaluate VLMs in RS and CV. The results show the limitations of these models on tasks that involve complex LULC classes, whereas fine-tuning using BigEarthNet$.$txt results in consistent performance gains across all considered tasks.
HyVIC: A Metric-Driven Spatio-Spectral Hyperspectral Image Compression Architecture Based on Variational Autoencoders
Mar 27, 2026The rapid growth of hyperspectral data archives in remote sensing (RS) necessitates effective compression methods for storage and transmission. Recent advances in learning-based hyperspectral image (HSI) compression have significantly enhanced both reconstruction fidelity and compression efficiency. However, existing methods typically adapt variational image compression models designed for natural images, without adequately accounting for the distinct spatio-spectral redundancies inherent in HSIs. In particular, they lack explicit architectural designs to balance spatial and spectral feature learning, limiting their ability to effectively leverage the unique characteristics of hyperspectral data. To address this issue, we introduce spatio-spectral variational hyperspectral image compression architecture (HyVIC). The proposed model comprises four main components: 1) adjustable spatio-spectral encoder; 2) spatio-spectral hyperencoder; 3) spatio-spectral hyperdecoder; and 4) adjustable spatio-spectral decoder. We demonstrate that the trade-off between spatial and spectral feature learning is crucial for the reconstruction fidelity, and therefore present a metric-driven strategy to systematically select the hyperparameters of the proposed model. Extensive experiments on two benchmark datasets demonstrate the effectiveness of the proposed model, achieving high spatial and spectral reconstruction fidelity across a wide range of compression ratios (CRs) and improving the state of the art by up to 4.66dB in terms of BD-PSNR. Based on our results, we offer insights and derive practical guidelines to guide future research directions in learning-based variational HSI compression. Our code and pre-trained model weights are publicly available at https://git.tu-berlin.de/rsim/hyvic .
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Mar 19, 2026Vision-language models (VLMs) have shown promise in earth observation (EO), yet they struggle with tasks that require grounding complex spatial reasoning in precise pixel-level visual representations. To address this problem, we introduce TerraScope, a unified VLM that delivers pixel-grounded geospatial reasoning with two key capabilities: (1) modality-flexible reasoning: it handles single-modality inputs (optical or SAR) and adaptively fuses different modalities into the reasoning process when both are available; (2) multi-temporal reasoning: it integrates temporal sequences for change analysis across multiple time points. In addition, we curate Terra-CoT, a large-scale dataset containing 1 million samples with pixel-level masks embedded in reasoning chains across multiple sources. We also propose TerraScope-Bench, the first benchmark for pixel-grounded geospatial reasoning with six sub-tasks that evaluates both answer accuracy and mask quality to ensure authentic pixel-grounded reasoning. Experiments show that TerraScope significantly outperforms existing VLMs on pixel-grounded geospatial reasoning while providing interpretable visual evidence.
Radio Map Prediction from Noisy Environment Information and Sparse Observations
Feb 12, 2026Many works have investigated radio map and path loss prediction in wireless networks using deep learning, in particular using convolutional neural networks. However, most assume perfect environment information, which is unrealistic in practice due to sensor limitations, mapping errors, and temporal changes. We demonstrate that convolutional neural networks trained with task-specific perturbations of geometry, materials, and Tx positions can implicitly compensate for prediction errors caused by inaccurate environment inputs. When tested with noisy inputs on synthetic indoor scenarios, models trained with perturbed environment data reduce error by up to 25\% compared to models trained on clean data. We verify our approach on real-world measurements, achieving 2.1 dB RMSE with noisy input data and 1.3 dB with complete information, compared to 2.3-3.1 dB for classical methods such as ray-tracing and radial basis function interpolation. Additionally, we compare different ways of encoding environment information at varying levels of detail and we find that, in the considered single-room indoor scenarios, binary occupancy encoding performs at least as well as detailed material property information, simplifying practical deployment.
How Much of a Model Do We Need? Redundancy and Slimmability in Remote Sensing Foundation Models
Jan 30, 2026Large-scale foundation models (FMs) in remote sensing (RS) are developed based on the paradigms established in computer vision (CV) and have shown promise for various Earth observation applications. However, the direct transfer of scaling assumptions from CV to RS has not been adequately examined. We hypothesize that RS FMs enter an overparameterized regime at substantially smaller scales than their CV counterparts, where increasing parameter count primarily induces redundant representations rather than qualitatively new abstractions. To test this hypothesis, we use post-hoc slimming, where we uniformly reduce the width of pretrained encoder, as a tool to measure representational redundancy across six state-of-the-art RS FMs on four downstream classification tasks. Our findings reveal a significant contrast with those in the CV domain: while a post-hoc slimmed masked autoencoder (MAE) trained on ImageNet retains less than 10% accuracy at 1% FLOPs, RS FMs maintain over 71% relative accuracy at the same budget. This sevenfold difference provides strong empirical support for our hypothesis. We further demonstrate that learned slimmable training can improve both Momentum Contrast (MoCo)- and MAE- based models. In addition, through the explained variance ratio and the feature correlation analysis, we provide mechanistic explanations showing that RS FMs distribute task-relevant information with high redundancy. Our findings establish post-hoc slimmability as both a practical deployment strategy for resource-constrained environments and a diagnostic tool that challenges the prevailing scaling paradigm in RS. Upon acceptance, we will publish all code.
Noise-Adaptive Regularization for Robust Multi-Label Remote Sensing Image Classification
Jan 13, 2026The development of reliable methods for multi-label classification (MLC) has become a prominent research direction in remote sensing (RS). As the scale of RS data continues to expand, annotation procedures increasingly rely on thematic products or crowdsourced procedures to reduce the cost of manual annotation. While cost-effective, these strategies often introduce multi-label noise in the form of partially incorrect annotations. In MLC, label noise arises as additive noise, subtractive noise, or a combination of both in the form of mixed noise. Previous work has largely overlooked this distinction and commonly treats noisy annotations as supervised signals, lacking mechanisms that explicitly adapt learning behavior to different noise types. To address this limitation, we propose NAR, a noise-adaptive regularization method that explicitly distinguishes between additive and subtractive noise within a semi-supervised learning framework. NAR employs a confidence-based label handling mechanism that dynamically retains label entries with high confidence, temporarily deactivates entries with moderate confidence, and corrects low confidence entries via flipping. This selective attenuation of supervision is integrated with early-learning regularization (ELR) to stabilize training and mitigate overfitting to corrupted labels. Experiments across additive, subtractive, and mixed noise scenarios demonstrate that NAR consistently improves robustness compared with existing methods. Performance improvements are most pronounced under subtractive and mixed noise, indicating that adaptive suppression and selective correction of noisy supervision provide an effective strategy for noise robust learning in RS MLC.
Rank-based Geographical Regularization: Revisiting Contrastive Self-Supervised Learning for Multispectral Remote Sensing Imagery
Jan 05, 2026Self-supervised learning (SSL) has become a powerful paradigm for learning from large, unlabeled datasets, particularly in computer vision (CV). However, applying SSL to multispectral remote sensing (RS) images presents unique challenges and opportunities due to the geographical and temporal variability of the data. In this paper, we introduce GeoRank, a novel regularization method for contrastive SSL that improves upon prior techniques by directly optimizing spherical distances to embed geographical relationships into the learned feature space. GeoRank outperforms or matches prior methods that integrate geographical metadata and consistently improves diverse contrastive SSL algorithms (e.g., BYOL, DINO). Beyond this, we present a systematic investigation of key adaptations of contrastive SSL for multispectral RS images, including the effectiveness of data augmentations, the impact of dataset cardinality and image size on performance, and the task dependency of temporal views. Code is available at https://github.com/tomburgert/georank.
Seabed-Net: A multi-task network for joint bathymetry estimation and seabed classification from remote sensing imagery in shallow waters
Oct 22, 2025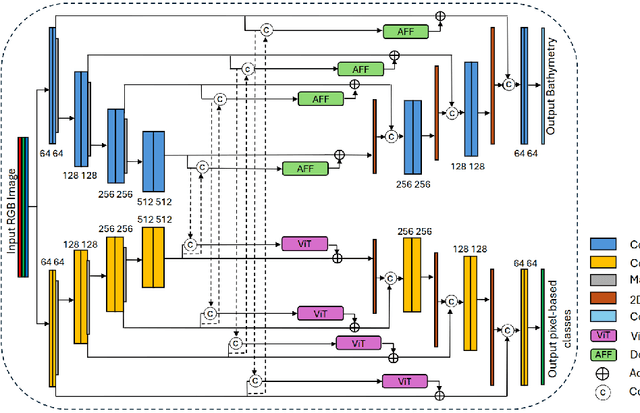
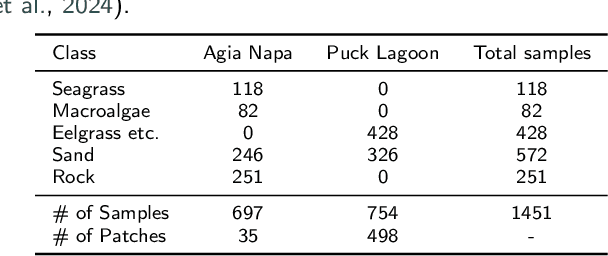
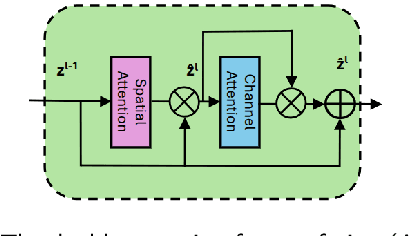
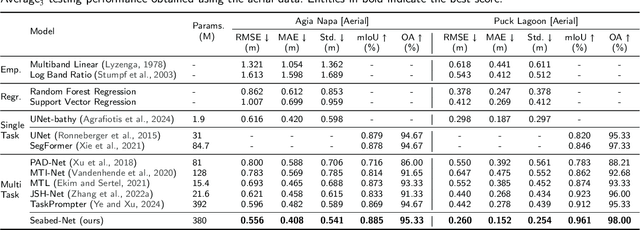
Accurate, detailed, and regularly updated bathymetry, coupled with complex semantic content, is essential for under-mapped shallow-water environments facing increasing climatological and anthropogenic pressures. However, existing approaches that derive either depth or seabed classes from remote sensing imagery treat these tasks in isolation, forfeiting the mutual benefits of their interaction and hindering the broader adoption of deep learning methods. To address these limitations, we introduce Seabed-Net, a unified multi-task framework that simultaneously predicts bathymetry and pixel-based seabed classification from remote sensing imagery of various resolutions. Seabed-Net employs dual-branch encoders for bathymetry estimation and pixel-based seabed classification, integrates cross-task features via an Attention Feature Fusion module and a windowed Swin-Transformer fusion block, and balances objectives through dynamic task uncertainty weighting. In extensive evaluations at two heterogeneous coastal sites, it consistently outperforms traditional empirical models and traditional machine learning regression methods, achieving up to 75\% lower RMSE. It also reduces bathymetric RMSE by 10-30\% compared to state-of-the-art single-task and multi-task baselines and improves seabed classification accuracy up to 8\%. Qualitative analyses further demonstrate enhanced spatial consistency, sharper habitat boundaries, and corrected depth biases in low-contrast regions. These results confirm that jointly modeling depth with both substrate and seabed habitats yields synergistic gains, offering a robust, open solution for integrated shallow-water mapping. Code and pretrained weights are available at https://github.com/pagraf/Seabed-Net.
CSMoE: An Efficient Remote Sensing Foundation Model with Soft Mixture-of-Experts
Sep 17, 2025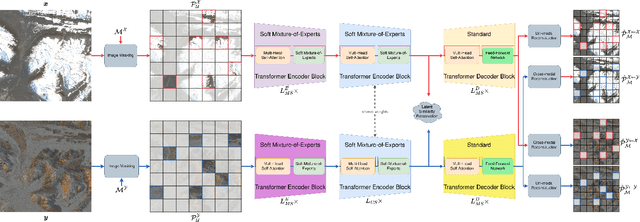
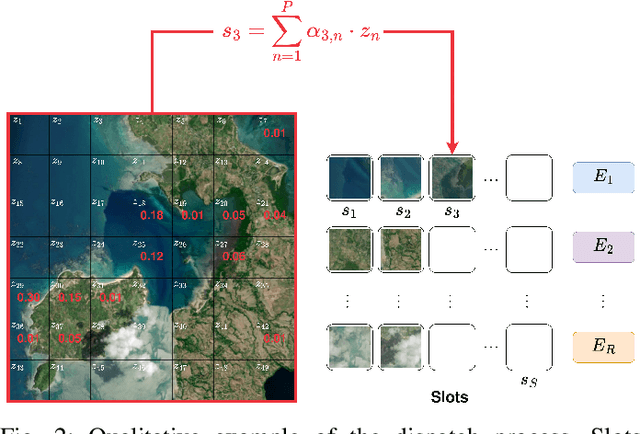
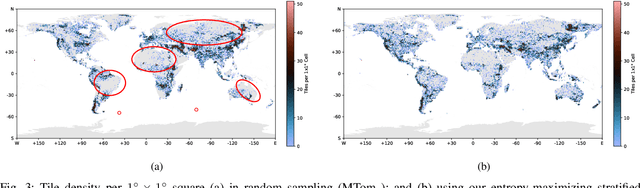

Self-supervised learning through masked autoencoders has attracted great attention for remote sensing (RS) foundation model (FM) development, enabling improved representation learning across diverse sensors and downstream tasks. However, existing RS FMs often either suffer from substantial computational complexity during both training and inference or exhibit limited representational capacity. These issues restrict their practical applicability in RS. To address this limitation, we propose an adaptation for enhancing the efficiency of RS FMs by integrating the Soft mixture-of-experts (MoE) mechanism into the FM. The integration of Soft MoEs into the FM allows modality-specific expert specialization alongside shared cross-sensor representation learning. To demonstrate the effectiveness of our adaptation, we apply it on the Cross-Sensor Masked Autoencoder (CSMAE) model, resulting in the Cross-Sensor Mixture-of-Experts (CSMoE) model. In addition, we introduce a thematic-climatic descriptor-driven sampling strategy for the construction of a representative and diverse training set to train our CSMoE model. Extensive experiments on scene classification, semantic segmentation, and content-based image retrieval demonstrate that our adaptation yields a reduction in computational requirements while maintaining or improving representational performance. Compared to state-of-the-art RS FMs, CSMoE achieves a superior trade-off between representational capacity, accuracy, and computational efficiency. On average, CSMoE achieves more than twice the computational efficiency of existing RS FMs, while maintaining competitive performance across all experiments. These results show the effectiveness of the proposed adaptation for creating computationally efficient RS FMs. The code for the model, the training set creation, and the model weights will be available at https://git.tu-berlin.de/rsim/csmoe.
Sea-Undistort: A Dataset for Through-Water Image Restoration in High Resolution Airborne Bathymetric Mapping
Aug 11, 2025


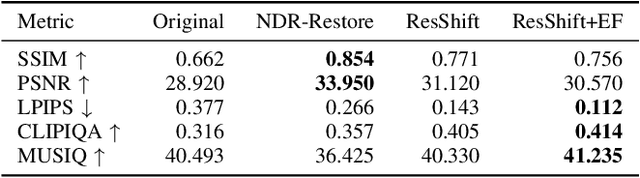
Accurate image-based bathymetric mapping in shallow waters remains challenging due to the complex optical distortions such as wave induced patterns, scattering and sunglint, introduced by the dynamic water surface, the water column properties, and solar illumination. In this work, we introduce Sea-Undistort, a comprehensive synthetic dataset of 1200 paired 512x512 through-water scenes rendered in Blender. Each pair comprises a distortion-free and a distorted view, featuring realistic water effects such as sun glint, waves, and scattering over diverse seabeds. Accompanied by per-image metadata such as camera parameters, sun position, and average depth, Sea-Undistort enables supervised training that is otherwise infeasible in real environments. We use Sea-Undistort to benchmark two state-of-the-art image restoration methods alongside an enhanced lightweight diffusion-based framework with an early-fusion sun-glint mask. When applied to real aerial data, the enhanced diffusion model delivers more complete Digital Surface Models (DSMs) of the seabed, especially in deeper areas, reduces bathymetric errors, suppresses glint and scattering, and crisply restores fine seabed details. Dataset, weights, and code are publicly available at https://www.magicbathy.eu/Sea-Undistort.html.