 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn assessment of data-centric methods for label noise identification in remote sensing data sets
Mar 17, 2026Label noise in the sense of incorrect labels is present in many real-world data sets and is known to severely limit the generalizability of deep learning models. In the field of remote sensing, however, automated treatment of label noise in data sets has received little attention to date. In particular, there is a lack of systematic analysis of the performance of data-centric methods that not only cope with label noise but also explicitly identify and isolate noisy labels. In this paper, we examine three such methods and evaluate their behavior under different label noise assumptions. To do this, we inject different types of label noise with noise levels ranging from 10 to 70% into two benchmark data sets, followed by an analysis of how well the selected methods filter the label noise and how this affects task performances. With our analyses, we clearly prove the value of data-centric methods for both parts - label noise identification and task performance improvements. Our analyses provide insights into which method is the best choice depending on the setting and objective. Finally, we show in which areas there is still a need for research in the transfer of data-centric label noise methods to remote sensing data. As such, our work is a step forward in bridging the methodological establishment of data-centric label noise methods and their usage in practical settings in the remote sensing domain.
Self-Supervised Cross-Modal Text-Image Time Series Retrieval in Remote Sensing
Jan 31, 2025



The development of image time series retrieval (ITSR) methods is a growing research interest in remote sensing (RS). Given a user-defined image time series (i.e., the query time series), the ITSR methods search and retrieve from large archives the image time series that have similar content to the query time series. The existing ITSR methods in RS are designed for unimodal retrieval problems, limiting their usability and versatility. To overcome this issue, as a first time in RS we introduce the task of cross-modal text-ITSR. In particular, we present a self-supervised cross-modal text-image time series retrieval (text-ITSR) method that enables the retrieval of image time series using text sentences as queries, and vice versa. In detail, we focus our attention on text-ITSR in pairs of images (i.e., bitemporal images). The proposed text-ITSR method consists of two key components: 1) modality-specific encoders to model the semantic content of bitemporal images and text sentences with discriminative features; and 2) modality-specific projection heads to align textual and image representations in a shared embedding space. To effectively model the temporal information within the bitemporal images, we introduce two fusion strategies: i) global feature fusion (GFF) strategy that combines global image features through simple yet effective operators; and ii) transformer-based feature fusion (TFF) strategy that leverages transformers for fine-grained temporal integration. Extensive experiments conducted on two benchmark RS archives demonstrate the effectiveness of the proposed method in accurately retrieving semantically relevant bitemporal images (or text sentences) to a query text sentence (or bitemporal image). The code of this work is publicly available at https://git.tu-berlin.de/rsim/cross-modal-text-tsir.
Annotation Cost Efficient Active Learning for Content Based Image Retrieval
Jun 26, 2023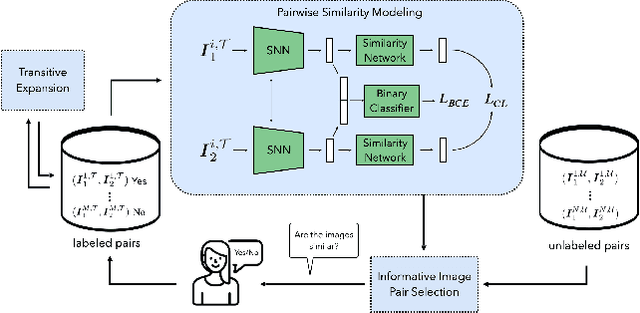
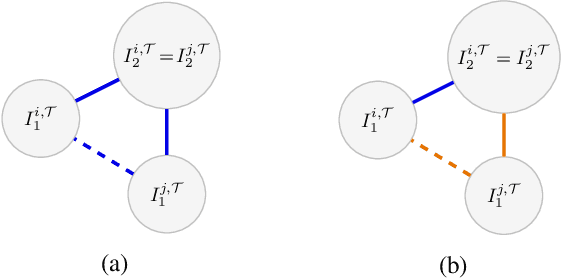
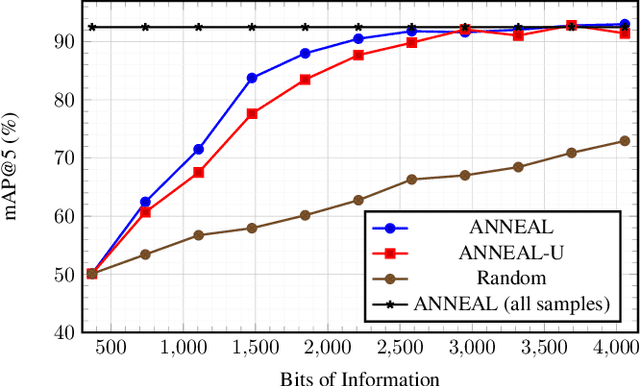
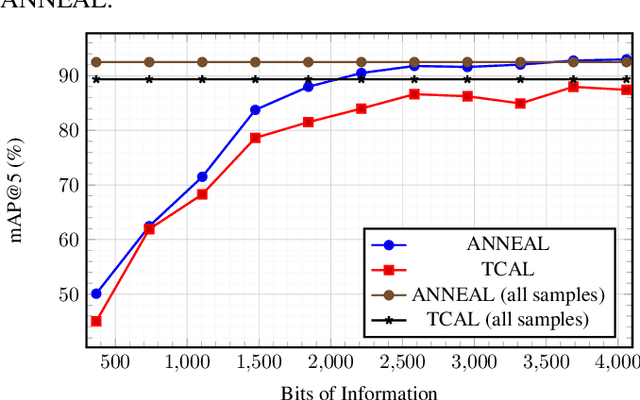
Deep metric learning (DML) based methods have been found very effective for content-based image retrieval (CBIR) in remote sensing (RS). For accurately learning the model parameters of deep neural networks, most of the DML methods require a high number of annotated training images, which can be costly to gather. To address this problem, in this paper we present an annotation cost efficient active learning (AL) method (denoted as ANNEAL). The proposed method aims to iteratively enrich the training set by annotating the most informative image pairs as similar or dissimilar, while accurately modelling a deep metric space. This is achieved by two consecutive steps. In the first step the pairwise image similarity is modelled based on the available training set. Then, in the second step the most uncertain and diverse (i.e., informative) image pairs are selected to be annotated. Unlike the existing AL methods for CBIR, at each AL iteration of ANNEAL a human expert is asked to annotate the most informative image pairs as similar/dissimilar. This significantly reduces the annotation cost compared to annotating images with land-use/land cover class labels. Experimental results show the effectiveness of our method. The code of ANNEAL is publicly available at https://git.tu-berlin.de/rsim/ANNEAL.