 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Context Improves the Integration of Text with Remote Sensing for Mapping Environmental Variables
Jan 13, 2026Recent developments in natural language processing highlight text as an emerging data source for ecology. Textual resources carry unique information that can be used in complementarity with geospatial data sources, thus providing insights at the local scale into environmental conditions and properties hidden from more traditional data sources. Leveraging textual information in a spatial context presents several challenges. First, the contribution of textual data remains poorly defined in an ecological context, and it is unclear for which tasks it should be incorporated. Unlike ubiquitous satellite imagery or environmental covariates, the availability of textual data is sparse and irregular; its integration with geospatial data is not straightforward. In response to these challenges, this work proposes an attention-based approach that combines aerial imagery and geolocated text within a spatial neighbourhood, i.e. integrating contributions from several nearby observations. Our approach combines vision and text representations with a geolocation encoding, with an attention-based module that dynamically selects spatial neighbours that are useful for predictive tasks.The proposed approach is applied to the EcoWikiRS dataset, which combines high-resolution aerial imagery with sentences extracted from Wikipedia describing local environmental conditions across Switzerland. Our model is evaluated on the task of predicting 103 environmental variables from the SWECO25 data cube. Our approach consistently outperforms single-location or unimodal, i.e. image-only or text-only, baselines. When analysing variables by thematic groups, results show a significant improvement in performance for climatic, edaphic, population and land use/land cover variables, underscoring the benefit of including the spatial context when combining text and image data.
SMARTIES: Spectrum-Aware Multi-Sensor Auto-Encoder for Remote Sensing Images
Jun 24, 2025From optical sensors to microwave radars, leveraging the complementary strengths of remote sensing (RS) sensors is crucial for achieving dense spatio-temporal monitoring of our planet. In contrast, recent deep learning models, whether task-specific or foundational, are often specific to single sensors or to fixed combinations: adapting such models to different sensory inputs requires both architectural changes and re-training, limiting scalability and generalization across multiple RS sensors. On the contrary, a single model able to modulate its feature representations to accept diverse sensors as input would pave the way to agile and flexible multi-sensor RS data processing. To address this, we introduce SMARTIES, a generic and versatile foundation model lifting sensor-specific/dependent efforts and enabling scalability and generalization to diverse RS sensors: SMARTIES projects data from heterogeneous sensors into a shared spectrum-aware space, enabling the use of arbitrary combinations of bands both for training and inference. To obtain sensor-agnostic representations, we train a single, unified transformer model reconstructing masked multi-sensor data with cross-sensor token mixup. On both single- and multi-modal tasks across diverse sensors, SMARTIES outperforms previous models that rely on sensor-specific pretraining. Our code and pretrained models are available at https://gsumbul.github.io/SMARTIES.
Redundancy-Aware Pretraining of Vision-Language Foundation Models in Remote Sensing
May 16, 2025The development of foundation models through pretraining of vision-language models (VLMs) has recently attracted great attention in remote sensing (RS). VLM pretraining aims to learn image and language alignments from a large number of image-text pairs. Each pretraining image is often associated with multiple captions containing redundant information due to repeated or semantically similar phrases, resulting in increased pretraining and inference time. To overcome this, we introduce a weighted feature aggregation (WFA) strategy for VLM pretraining in RS. Our strategy aims to extract and exploit complementary information from multiple captions per image while reducing redundancies through feature aggregation with importance weighting. To calculate adaptive importance weights for different captions of each image, we propose two techniques: (i) non-parametric uniqueness and (ii) learning-based attention. In the first technique, importance weights are calculated based on the bilingual evaluation understudy (BLEU) scores of the captions to emphasize unique sentences and reduce the influence of repetitive ones. In the second technique, importance weights are learned through an attention mechanism instead of relying on hand-crafted features. The effectiveness of the proposed WFA strategy with the two techniques is analyzed in terms of downstream performance on text-to-image retrieval in RS. Experimental results show that the proposed strategy enables efficient and effective pretraining of VLMs in RS. Based on the experimental analysis, we derive guidelines for selecting appropriate techniques depending on downstream task requirements and resource constraints. The code of this work is publicly available at https://git.tu-berlin.de/rsim/redundacy-aware-rs-vlm.
MaskSDM with Shapley values to improve flexibility, robustness, and explainability in species distribution modeling
Mar 17, 2025Species Distribution Models (SDMs) play a vital role in biodiversity research, conservation planning, and ecological niche modeling by predicting species distributions based on environmental conditions. The selection of predictors is crucial, strongly impacting both model accuracy and how well the predictions reflect ecological patterns. To ensure meaningful insights, input variables must be carefully chosen to match the study objectives and the ecological requirements of the target species. However, existing SDMs, including both traditional and deep learning-based approaches, often lack key capabilities for variable selection: (i) flexibility to choose relevant predictors at inference without retraining; (ii) robustness to handle missing predictor values without compromising accuracy; and (iii) explainability to interpret and accurately quantify each predictor's contribution. To overcome these limitations, we introduce MaskSDM, a novel deep learning-based SDM that enables flexible predictor selection by employing a masked training strategy. This approach allows the model to make predictions with arbitrary subsets of input variables while remaining robust to missing data. It also provides a clearer understanding of how adding or removing a given predictor affects model performance and predictions. Additionally, MaskSDM leverages Shapley values for precise predictor contribution assessments, improving upon traditional approximations. We evaluate MaskSDM on the global sPlotOpen dataset, modeling the distributions of 12,738 plant species. Our results show that MaskSDM outperforms imputation-based methods and approximates models trained on specific subsets of variables. These findings underscore MaskSDM's potential to increase the applicability and adoption of SDMs, laying the groundwork for developing foundation models in SDMs that can be readily applied to diverse ecological applications.
A Multi-Modal Federated Learning Framework for Remote Sensing Image Classification
Mar 13, 2025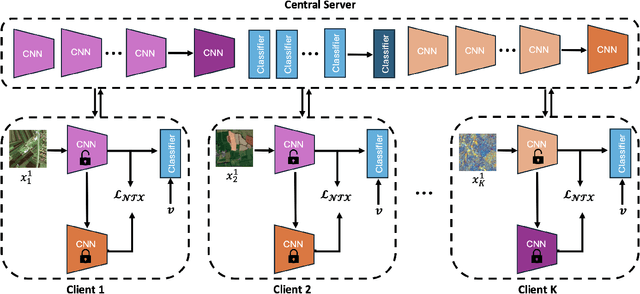
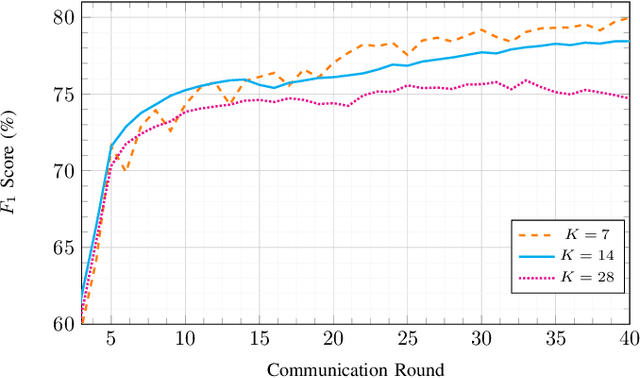
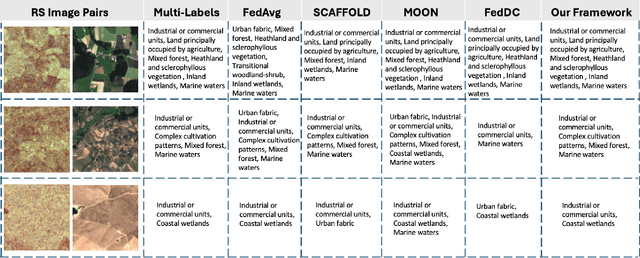
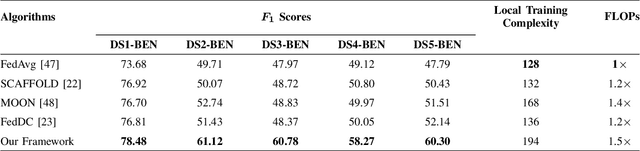
Federated learning (FL) enables the collaborative training of deep neural networks across decentralized data archives (i.e., clients) without sharing the local data of the clients. Most of the existing FL methods assume that the data distributed across all clients is associated with the same data modality. However, remote sensing (RS) images present in different clients can be associated with diverse data modalities. The joint use of the multi-modal RS data can significantly enhance classification performance. To effectively exploit decentralized and unshared multi-modal RS data, our paper introduces a novel multi-modal FL framework for RS image classification problems. The proposed framework comprises three modules: 1) multi-modal fusion (MF); 2) feature whitening (FW); and 3) mutual information maximization (MIM). The MF module employs iterative model averaging to facilitate learning without accessing multi-modal training data on clients. The FW module aims to address the limitations of training data heterogeneity by aligning data distributions across clients. The MIM module aims to model mutual information by maximizing the similarity between images from different modalities. For the experimental analyses, we focus our attention on multi-label classification and pixel-based classification tasks in RS. The results obtained using two benchmark archives show the effectiveness of the proposed framework when compared to state-of-the-art algorithms in the literature. The code of the proposed framework will be available at https://git.tu-berlin.de/rsim/multi-modal-FL.
reBEN: Refined BigEarthNet Dataset for Remote Sensing Image Analysis
Jul 04, 2024



This paper presents refined BigEarthNet (reBEN) that is a large-scale, multi-modal remote sensing dataset constructed to support deep learning (DL) studies for remote sensing image analysis. The reBEN dataset consists of 549,488 pairs of Sentinel-1 and Sentinel-2 image patches. To construct reBEN, we initially consider the Sentinel-1 and Sentinel-2 tiles used to construct the BigEarthNet dataset and then divide them into patches of size 1200 m x 1200 m. We apply atmospheric correction to the Sentinel-2 patches using the latest version of the sen2cor tool, resulting in higher-quality patches compared to those present in BigEarthNet. Each patch is then associated with a pixel-level reference map and scene-level multi-labels. This makes reBEN suitable for pixel- and scene-based learning tasks. The labels are derived from the most recent CORINE Land Cover (CLC) map of 2018 by utilizing the 19-class nomenclature as in BigEarthNet. The use of the most recent CLC map results in overcoming the label noise present in BigEarthNet. Furthermore, we introduce a new geographical-based split assignment algorithm that significantly reduces the spatial correlation among the train, validation, and test sets with respect to those present in BigEarthNet. This increases the reliability of the evaluation of DL models. To minimize the DL model training time, we introduce software tools that convert the reBEN dataset into a DL-optimized data format. In our experiments, we show the potential of reBEN for multi-modal multi-label image classification problems by considering several state-of-the-art DL models. The pre-trained model weights, associated code, and complete dataset are available at https://bigearth.net.
Exploring Masked Autoencoders for Sensor-Agnostic Image Retrieval in Remote Sensing
Jan 15, 2024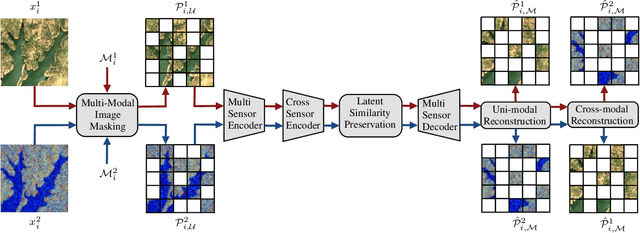

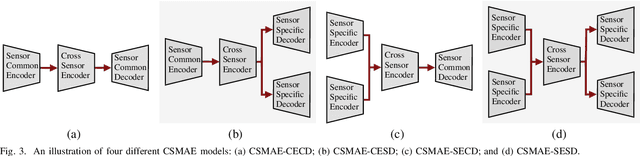

Self-supervised learning through masked autoencoders (MAEs) has recently attracted great attention for remote sensing (RS) image representation learning, and thus embodies a significant potential for content-based image retrieval (CBIR) from ever-growing RS image archives. However, the existing studies on MAEs in RS assume that the considered RS images are acquired by a single image sensor, and thus are only suitable for uni-modal CBIR problems. The effectiveness of MAEs for cross-sensor CBIR, which aims to search semantically similar images across different image modalities, has not been explored yet. In this paper, we take the first step to explore the effectiveness of MAEs for sensor-agnostic CBIR in RS. To this end, we present a systematic overview on the possible adaptations of the vanilla MAE to exploit masked image modeling on multi-sensor RS image archives (denoted as cross-sensor masked autoencoders [CSMAEs]). Based on different adjustments applied to the vanilla MAE, we introduce different CSMAE models. We also provide an extensive experimental analysis of these CSMAE models. We finally derive a guideline to exploit masked image modeling for uni-modal and cross-modal CBIR problems in RS. The code of this work is publicly available at https://github.com/jakhac/CSMAE.
Federated Learning Across Decentralized and Unshared Archives for Remote Sensing Image Classification
Nov 10, 2023Federated learning (FL) enables the collaboration of multiple deep learning models to learn from decentralized data archives (i.e., clients) without accessing data on clients. Although FL offers ample opportunities in knowledge discovery from distributed image archives, it is seldom considered in remote sensing (RS). In this paper, as a first time in RS, we present a comparative study of state-of-the-art FL algorithms. To this end, we initially provide a systematic review of the FL algorithms presented in the computer vision community for image classification problems, and select several state-of-the-art FL algorithms based on their effectiveness with respect to training data heterogeneity across clients (known as non-IID data). After presenting an extensive overview of the selected algorithms, a theoretical comparison of the algorithms is conducted based on their: 1) local training complexity; 2) aggregation complexity; 3) learning efficiency; 4) communication cost; and 5) scalability in terms of number of clients. As the classification task, we consider multi-label classification (MLC) problem since RS images typically consist of multiple classes, and thus can simultaneously be associated with multi-labels. After the theoretical comparison, experimental analyses are presented to compare them under different decentralization scenarios in terms of MLC performance. Based on our comprehensive analyses, we finally derive a guideline for selecting suitable FL algorithms in RS. The code of this work will be publicly available at https://git.tu-berlin.de/rsim/FL-RS.
Annotation Cost Efficient Active Learning for Content Based Image Retrieval
Jun 26, 2023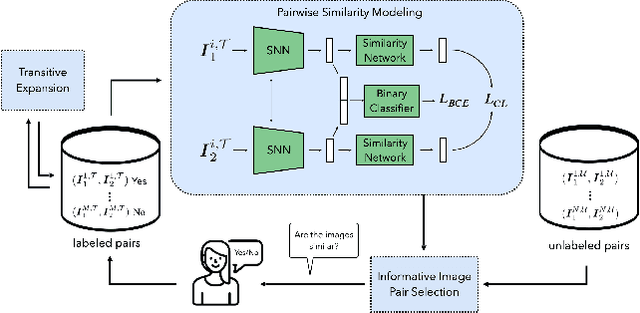
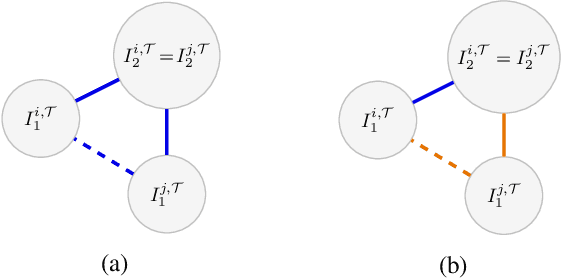
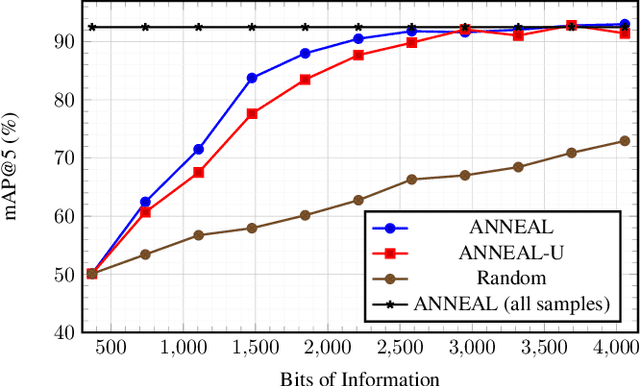
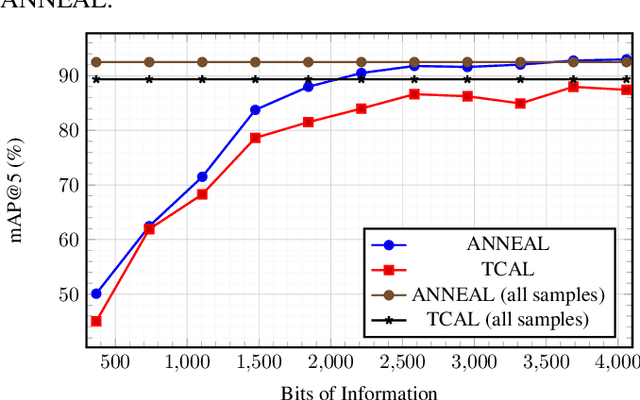
Deep metric learning (DML) based methods have been found very effective for content-based image retrieval (CBIR) in remote sensing (RS). For accurately learning the model parameters of deep neural networks, most of the DML methods require a high number of annotated training images, which can be costly to gather. To address this problem, in this paper we present an annotation cost efficient active learning (AL) method (denoted as ANNEAL). The proposed method aims to iteratively enrich the training set by annotating the most informative image pairs as similar or dissimilar, while accurately modelling a deep metric space. This is achieved by two consecutive steps. In the first step the pairwise image similarity is modelled based on the available training set. Then, in the second step the most uncertain and diverse (i.e., informative) image pairs are selected to be annotated. Unlike the existing AL methods for CBIR, at each AL iteration of ANNEAL a human expert is asked to annotate the most informative image pairs as similar/dissimilar. This significantly reduces the annotation cost compared to annotating images with land-use/land cover class labels. Experimental results show the effectiveness of our method. The code of ANNEAL is publicly available at https://git.tu-berlin.de/rsim/ANNEAL.
Label Noise Robust Image Representation Learning based on Supervised Variational Autoencoders in Remote Sensing
Jun 14, 2023Due to the publicly available thematic maps and crowd-sourced data, remote sensing (RS) image annotations can be gathered at zero cost for training deep neural networks (DNNs). However, such annotation sources may increase the risk of including noisy labels in training data, leading to inaccurate RS image representation learning (IRL). To address this issue, in this paper we propose a label noise robust IRL method that aims to prevent the interference of noisy labels on IRL, independently from the learning task being considered in RS. To this end, the proposed method combines a supervised variational autoencoder (SVAE) with any kind of DNN. This is achieved by defining variational generative process based on image features. This allows us to define the importance of each training sample for IRL based on the loss values acquired from the SVAE and the task head of the considered DNN. Then, the proposed method imposes lower importance to images with noisy labels, while giving higher importance to those with correct labels during IRL. Experimental results show the effectiveness of the proposed method when compared to well-known label noise robust IRL methods applied to RS images. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/RS-IRL-SVAE.