 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Masked Autoencoders for Sensor-Agnostic Image Retrieval in Remote Sensing
Paper and Code
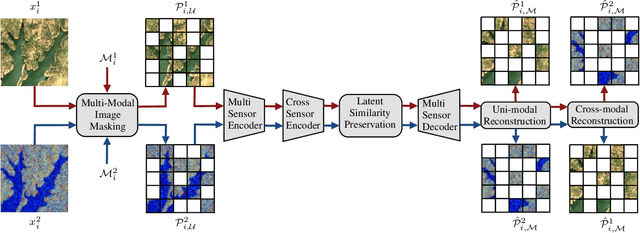

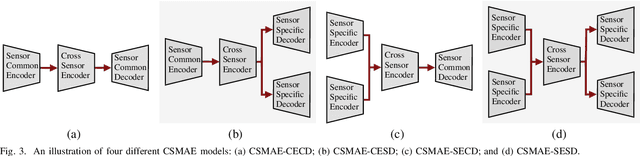

Self-supervised learning through masked autoencoders (MAEs) has recently attracted great attention for remote sensing (RS) image representation learning, and thus embodies a significant potential for content-based image retrieval (CBIR) from ever-growing RS image archives. However, the existing studies on MAEs in RS assume that the considered RS images are acquired by a single image sensor, and thus are only suitable for uni-modal CBIR problems. The effectiveness of MAEs for cross-sensor CBIR, which aims to search semantically similar images across different image modalities, has not been explored yet. In this paper, we take the first step to explore the effectiveness of MAEs for sensor-agnostic CBIR in RS. To this end, we present a systematic overview on the possible adaptations of the vanilla MAE to exploit masked image modeling on multi-sensor RS image archives (denoted as cross-sensor masked autoencoders [CSMAEs]). Based on different adjustments applied to the vanilla MAE, we introduce different CSMAE models. We also provide an extensive experimental analysis of these CSMAE models. We finally derive a guideline to exploit masked image modeling for uni-modal and cross-modal CBIR problems in RS. The code of this work is publicly available at https://github.com/jakhac/CSMAE.