 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalanced Classification through the Lens of Spurious Correlations
Oct 31, 2025Class imbalance poses a fundamental challenge in machine learning, frequently leading to unreliable classification performance. While prior methods focus on data- or loss-reweighting schemes, we view imbalance as a data condition that amplifies Clever Hans (CH) effects by underspecification of minority classes. In a counterfactual explanations-based approach, we propose to leverage Explainable AI to jointly identify and eliminate CH effects emerging under imbalance. Our method achieves competitive classification performance on three datasets and demonstrates how CH effects emerge under imbalance, a perspective largely overlooked by existing approaches.
SCAM: A Real-World Typographic Robustness Evaluation for Multimodal Foundation Models
Apr 07, 2025Typographic attacks exploit the interplay between text and visual content in multimodal foundation models, causing misclassifications when misleading text is embedded within images. However, existing datasets are limited in size and diversity, making it difficult to study such vulnerabilities. In this paper, we introduce SCAM, the largest and most diverse dataset of real-world typographic attack images to date, containing 1,162 images across hundreds of object categories and attack words. Through extensive benchmarking of Vision-Language Models (VLMs) on SCAM, we demonstrate that typographic attacks significantly degrade performance, and identify that training data and model architecture influence the susceptibility to these attacks. Our findings reveal that typographic attacks persist in state-of-the-art Large Vision-Language Models (LVLMs) due to the choice of their vision encoder, though larger Large Language Models (LLMs) backbones help mitigate their vulnerability. Additionally, we demonstrate that synthetic attacks closely resemble real-world (handwritten) attacks, validating their use in research. Our work provides a comprehensive resource and empirical insights to facilitate future research toward robust and trustworthy multimodal AI systems. We publicly release the datasets introduced in this paper under https://huggingface.co/datasets/BLISS-e-V/SCAM, along with the code for evaluations at https://github.com/Bliss-e-V/SCAM.
Exploring Masked Autoencoders for Sensor-Agnostic Image Retrieval in Remote Sensing
Jan 15, 2024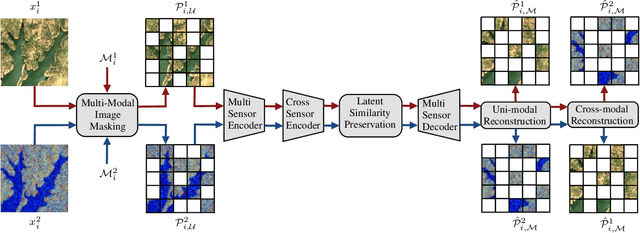

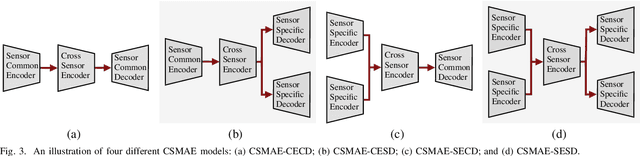

Self-supervised learning through masked autoencoders (MAEs) has recently attracted great attention for remote sensing (RS) image representation learning, and thus embodies a significant potential for content-based image retrieval (CBIR) from ever-growing RS image archives. However, the existing studies on MAEs in RS assume that the considered RS images are acquired by a single image sensor, and thus are only suitable for uni-modal CBIR problems. The effectiveness of MAEs for cross-sensor CBIR, which aims to search semantically similar images across different image modalities, has not been explored yet. In this paper, we take the first step to explore the effectiveness of MAEs for sensor-agnostic CBIR in RS. To this end, we present a systematic overview on the possible adaptations of the vanilla MAE to exploit masked image modeling on multi-sensor RS image archives (denoted as cross-sensor masked autoencoders [CSMAEs]). Based on different adjustments applied to the vanilla MAE, we introduce different CSMAE models. We also provide an extensive experimental analysis of these CSMAE models. We finally derive a guideline to exploit masked image modeling for uni-modal and cross-modal CBIR problems in RS. The code of this work is publicly available at https://github.com/jakhac/CSMAE.