 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgereBEN: Refined BigEarthNet Dataset for Remote Sensing Image Analysis
Jul 04, 2024



This paper presents refined BigEarthNet (reBEN) that is a large-scale, multi-modal remote sensing dataset constructed to support deep learning (DL) studies for remote sensing image analysis. The reBEN dataset consists of 549,488 pairs of Sentinel-1 and Sentinel-2 image patches. To construct reBEN, we initially consider the Sentinel-1 and Sentinel-2 tiles used to construct the BigEarthNet dataset and then divide them into patches of size 1200 m x 1200 m. We apply atmospheric correction to the Sentinel-2 patches using the latest version of the sen2cor tool, resulting in higher-quality patches compared to those present in BigEarthNet. Each patch is then associated with a pixel-level reference map and scene-level multi-labels. This makes reBEN suitable for pixel- and scene-based learning tasks. The labels are derived from the most recent CORINE Land Cover (CLC) map of 2018 by utilizing the 19-class nomenclature as in BigEarthNet. The use of the most recent CLC map results in overcoming the label noise present in BigEarthNet. Furthermore, we introduce a new geographical-based split assignment algorithm that significantly reduces the spatial correlation among the train, validation, and test sets with respect to those present in BigEarthNet. This increases the reliability of the evaluation of DL models. To minimize the DL model training time, we introduce software tools that convert the reBEN dataset into a DL-optimized data format. In our experiments, we show the potential of reBEN for multi-modal multi-label image classification problems by considering several state-of-the-art DL models. The pre-trained model weights, associated code, and complete dataset are available at https://bigearth.net.
A Label Propagation Strategy for CutMix in Multi-Label Remote Sensing Image Classification
May 22, 2024



The development of supervised deep learning-based methods for multi-label scene classification (MLC) is one of the prominent research directions in remote sensing (RS). Yet, collecting annotations for large RS image archives is time-consuming and costly. To address this issue, several data augmentation methods have been introduced in RS. Among others, the data augmentation technique CutMix, which combines parts of two existing training images to generate an augmented image, stands out as a particularly effective approach. However, the direct application of CutMix in RS MLC can lead to the erasure or addition of class labels (i.e., label noise) in the augmented (i.e., combined) training image. To address this problem, we introduce a label propagation (LP) strategy that allows the effective application of CutMix in the context of MLC problems in RS without being affected by label noise. To this end, our proposed LP strategy exploits pixel-level class positional information to update the multi-label of the augmented training image. We propose to access such class positional information from reference maps associated to each training image (e.g., thematic products) or from class explanation masks provided by an explanation method if no reference maps are available. Similarly to pairing two training images, our LP strategy carries out a pairing operation on the associated pixel-level class positional information to derive the updated multi-label for the augmented image. Experimental results show the effectiveness of our LP strategy in general and its robustness in the case of various simulated and real scenarios with noisy class positional information in particular.
Exploring Masked Autoencoders for Sensor-Agnostic Image Retrieval in Remote Sensing
Jan 15, 2024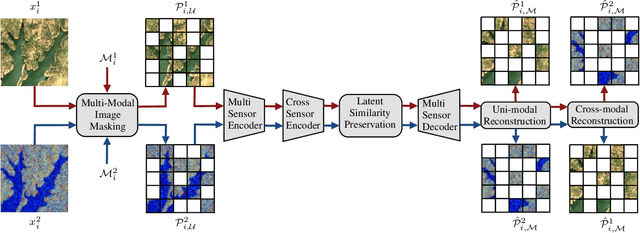

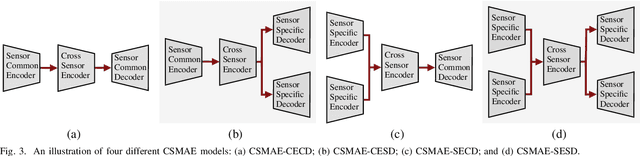

Self-supervised learning through masked autoencoders (MAEs) has recently attracted great attention for remote sensing (RS) image representation learning, and thus embodies a significant potential for content-based image retrieval (CBIR) from ever-growing RS image archives. However, the existing studies on MAEs in RS assume that the considered RS images are acquired by a single image sensor, and thus are only suitable for uni-modal CBIR problems. The effectiveness of MAEs for cross-sensor CBIR, which aims to search semantically similar images across different image modalities, has not been explored yet. In this paper, we take the first step to explore the effectiveness of MAEs for sensor-agnostic CBIR in RS. To this end, we present a systematic overview on the possible adaptations of the vanilla MAE to exploit masked image modeling on multi-sensor RS image archives (denoted as cross-sensor masked autoencoders [CSMAEs]). Based on different adjustments applied to the vanilla MAE, we introduce different CSMAE models. We also provide an extensive experimental analysis of these CSMAE models. We finally derive a guideline to exploit masked image modeling for uni-modal and cross-modal CBIR problems in RS. The code of this work is publicly available at https://github.com/jakhac/CSMAE.
LiT-4-RSVQA: Lightweight Transformer-based Visual Question Answering in Remote Sensing
Jun 02, 2023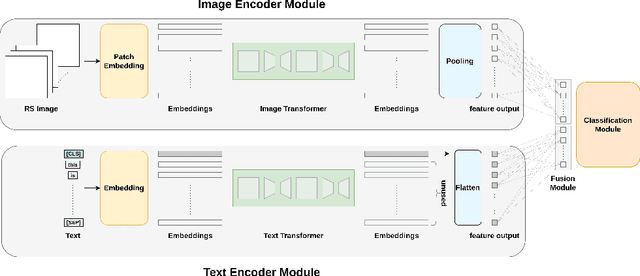
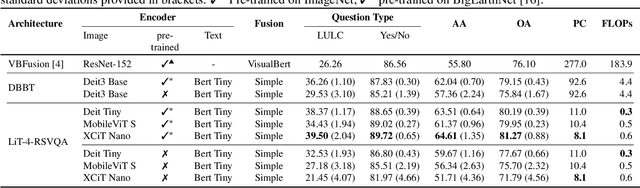
Visual question answering (VQA) methods in remote sensing (RS) aim to answer natural language questions with respect to an RS image. Most of the existing methods require a large amount of computational resources, which limits their application in operational scenarios in RS. To address this issue, in this paper we present an effective lightweight transformer-based VQA in RS (LiT-4-RSVQA) architecture for efficient and accurate VQA in RS. Our architecture consists of: i) a lightweight text encoder module; ii) a lightweight image encoder module; iii) a fusion module; and iv) a classification module. The experimental results obtained on a VQA benchmark dataset demonstrate that our proposed LiT-4-RSVQA architecture provides accurate VQA results while significantly reducing the computational requirements on the executing hardware. Our code is publicly available at https://git.tu-berlin.de/rsim/lit4rsvqa.
Transformer-based Multi-Modal Learning for Multi Label Remote Sensing Image Classification
Jun 02, 2023In this paper, we introduce a novel Synchronized Class Token Fusion (SCT Fusion) architecture in the framework of multi-modal multi-label classification (MLC) of remote sensing (RS) images. The proposed architecture leverages modality-specific attention-based transformer encoders to process varying input modalities, while exchanging information across modalities by synchronizing the special class tokens after each transformer encoder block. The synchronization involves fusing the class tokens with a trainable fusion transformation, resulting in a synchronized class token that contains information from all modalities. As the fusion transformation is trainable, it allows to reach an accurate representation of the shared features among different modalities. Experimental results show the effectiveness of the proposed architecture over single-modality architectures and an early fusion multi-modal architecture when evaluated on a multi-modal MLC dataset. The code of the proposed architecture is publicly available at https://git.tu-berlin.de/rsim/sct-fusion.
Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing
Oct 10, 2022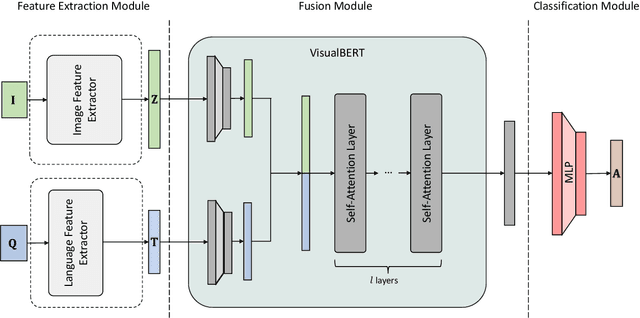
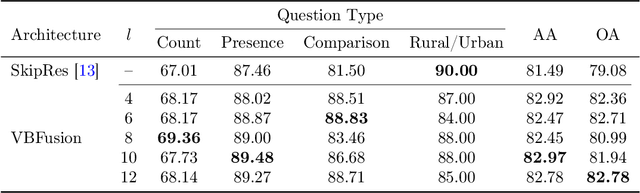
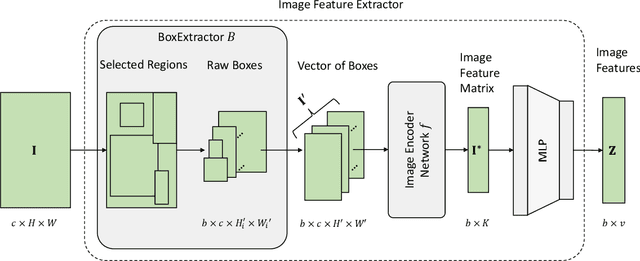
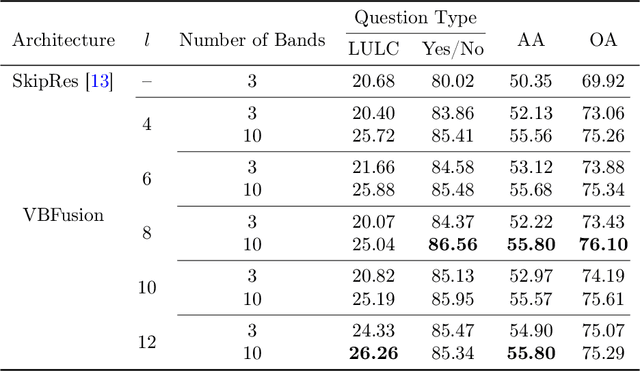
With the new generation of satellite technologies, the archives of remote sensing (RS) images are growing very fast. To make the intrinsic information of each RS image easily accessible, visual question answering (VQA) has been introduced in RS. VQA allows a user to formulate a free-form question concerning the content of RS images to extract generic information. It has been shown that the fusion of the input modalities (i.e., image and text) is crucial for the performance of VQA systems. Most of the current fusion approaches use modality-specific representations in their fusion modules instead of joint representation learning. However, to discover the underlying relation between both the image and question modality, the model is required to learn the joint representation instead of simply combining (e.g., concatenating, adding, or multiplying) the modality-specific representations. We propose a multi-modal transformer-based architecture to overcome this issue. Our proposed architecture consists of three main modules: i) the feature extraction module for extracting the modality-specific features; ii) the fusion module, which leverages a user-defined number of multi-modal transformer layers of the VisualBERT model (VB); and iii) the classification module to obtain the answer. Experimental results obtained on the RSVQAxBEN and RSVQA-LR datasets (which are made up of RGB bands of Sentinel-2 images) demonstrate the effectiveness of VBFusion for VQA tasks in RS. To analyze the importance of using other spectral bands for the description of the complex content of RS images in the framework of VQA, we extend the RSVQAxBEN dataset to include all the spectral bands of Sentinel-2 images with 10m and 20m spatial resolution.