 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Rank: A Graph Theoretical Approach to Pruning Large Language Models
Oct 17, 2024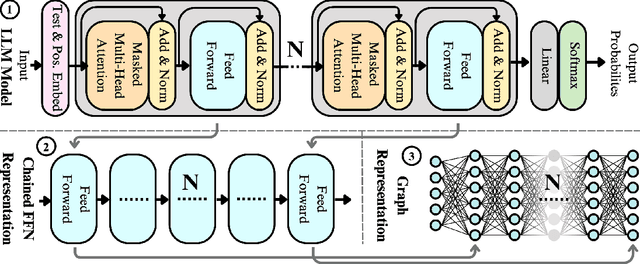

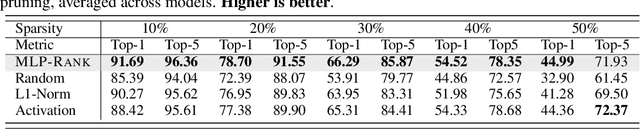
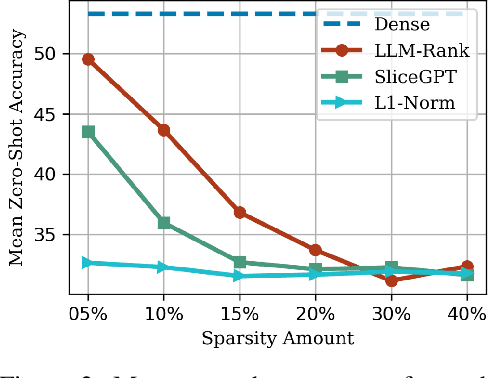
The evolving capabilities of large language models are accompanied by growing sizes and deployment costs, necessitating effective inference optimisation techniques. We propose a novel pruning method utilising centrality measures from graph theory, reducing both the computational requirements and the memory footprint of these models. Specifically, we devise a method for creating a weighted directed acyclical graph representation of multilayer perceptrons to which we apply a modified version of the weighted PageRank centrality measure to compute node importance scores. In combination with uniform pruning this leads to structured sparsity. We call this pruning method MLPRank. Furthermore we introduce an extension to decoder-only transformer models and call it LLMRank. For both variants we demonstrate a strong performance. With MLPRank on average leading to 6.09 % higher accuracy retention than three popular baselines and 13.42 % with LLMRank compared to two popular baselines.
Impact of HPO on AutoML Forecasting Ensembles
Nov 07, 2023A forecasting ensemble consisting of a diverse range of estimators for both local and global univariate forecasting, in particular MQ-CNN,DeepAR, Prophet, NPTS, ARIMA and ETS, can be used to make forecasts for a variety of problems. This paper delves into the aspect of adding different hyperparameter optimization strategies to the deep learning models in such a setup (DeepAR and MQ-CNN), exploring the trade-off between added training cost and the increase in accuracy for different configurations. It shows that in such a setup, adding hyperparameter optimization can lead to performance improvements, with the final setup having a 9.9 % percent accuracy improvement with respect to the avg-wQL over the baseline ensemble without HPO, accompanied by a 65.8 % increase in end-to-end ensemble latency. This improvement is based on an empirical analysis of combining the ensemble pipeline with different tuning strategies, namely Bayesian Optimisation and Hyperband and different configurations of those strategies. In the final configuration, the proposed combination of ensemble learning and HPO outperforms the state of the art commercial AutoML forecasting solution, Amazon Forecast, with a 3.5 % lower error and 16.0 % lower end-to-end ensemble latency.
Transformer-based Multi-Modal Learning for Multi Label Remote Sensing Image Classification
Jun 02, 2023In this paper, we introduce a novel Synchronized Class Token Fusion (SCT Fusion) architecture in the framework of multi-modal multi-label classification (MLC) of remote sensing (RS) images. The proposed architecture leverages modality-specific attention-based transformer encoders to process varying input modalities, while exchanging information across modalities by synchronizing the special class tokens after each transformer encoder block. The synchronization involves fusing the class tokens with a trainable fusion transformation, resulting in a synchronized class token that contains information from all modalities. As the fusion transformation is trainable, it allows to reach an accurate representation of the shared features among different modalities. Experimental results show the effectiveness of the proposed architecture over single-modality architectures and an early fusion multi-modal architecture when evaluated on a multi-modal MLC dataset. The code of the proposed architecture is publicly available at https://git.tu-berlin.de/rsim/sct-fusion.