 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Rank: A Graph Theoretical Approach to Pruning Large Language Models
Oct 17, 2024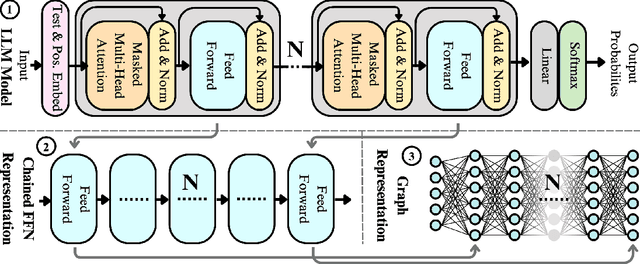

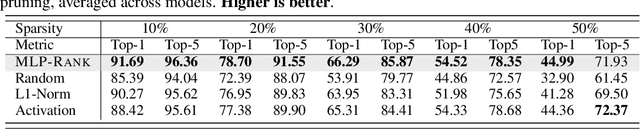
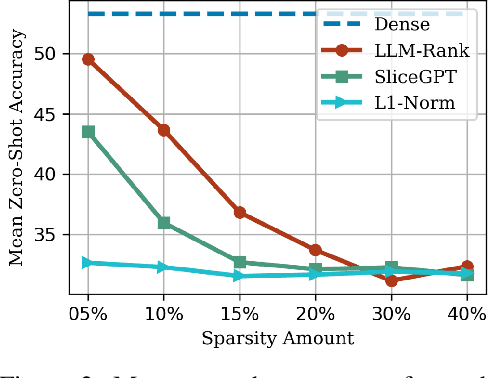
The evolving capabilities of large language models are accompanied by growing sizes and deployment costs, necessitating effective inference optimisation techniques. We propose a novel pruning method utilising centrality measures from graph theory, reducing both the computational requirements and the memory footprint of these models. Specifically, we devise a method for creating a weighted directed acyclical graph representation of multilayer perceptrons to which we apply a modified version of the weighted PageRank centrality measure to compute node importance scores. In combination with uniform pruning this leads to structured sparsity. We call this pruning method MLPRank. Furthermore we introduce an extension to decoder-only transformer models and call it LLMRank. For both variants we demonstrate a strong performance. With MLPRank on average leading to 6.09 % higher accuracy retention than three popular baselines and 13.42 % with LLMRank compared to two popular baselines.
Evaluating the Fairness of Discriminative Foundation Models in Computer Vision
Oct 18, 2023We propose a novel taxonomy for bias evaluation of discriminative foundation models, such as Contrastive Language-Pretraining (CLIP), that are used for labeling tasks. We then systematically evaluate existing methods for mitigating bias in these models with respect to our taxonomy. Specifically, we evaluate OpenAI's CLIP and OpenCLIP models for key applications, such as zero-shot classification, image retrieval and image captioning. We categorize desired behaviors based around three axes: (i) if the task concerns humans; (ii) how subjective the task is (i.e., how likely it is that people from a diverse range of backgrounds would agree on a labeling); and (iii) the intended purpose of the task and if fairness is better served by impartiality (i.e., making decisions independent of the protected attributes) or representation (i.e., making decisions to maximize diversity). Finally, we provide quantitative fairness evaluations for both binary-valued and multi-valued protected attributes over ten diverse datasets. We find that fair PCA, a post-processing method for fair representations, works very well for debiasing in most of the aforementioned tasks while incurring only minor loss of performance. However, different debiasing approaches vary in their effectiveness depending on the task. Hence, one should choose the debiasing approach depending on the specific use case.
Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
Jul 11, 2022

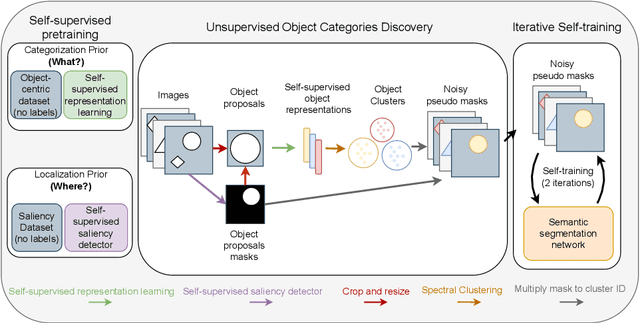
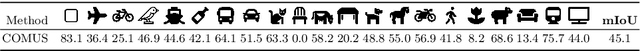
In this paper, we show that recent advances in self-supervised feature learning enable unsupervised object discovery and semantic segmentation with a performance that matches the state of the field on supervised semantic segmentation 10 years ago. We propose a methodology based on unsupervised saliency masks and self-supervised feature clustering to kickstart object discovery followed by training a semantic segmentation network on pseudo-labels to bootstrap the system on images with multiple objects. We present results on PASCAL VOC that go far beyond the current state of the art (47.3 mIoU), and we report for the first time results on MS COCO for the whole set of 81 classes: our method discovers 34 categories with more than $20\%$ IoU, while obtaining an average IoU of 19.6 for all 81 categories.
Evaluating Fairness of Machine Learning Models Under Uncertain and Incomplete Information
Feb 16, 2021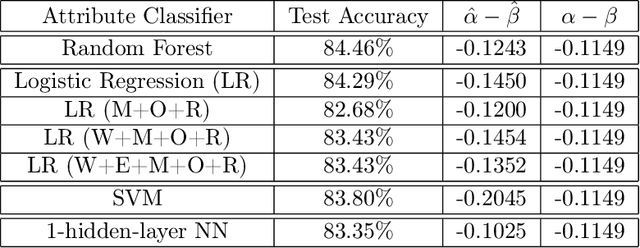
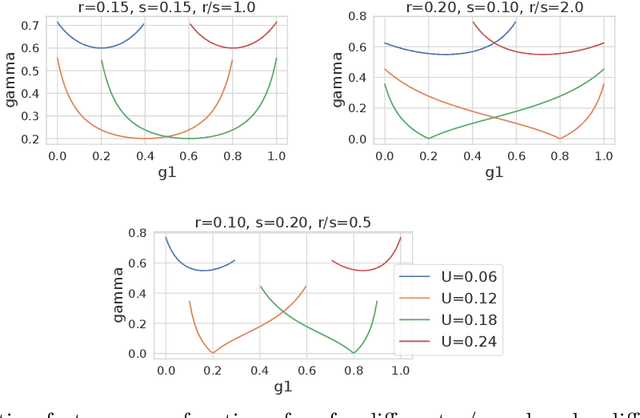
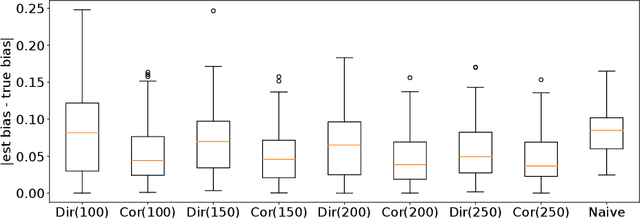
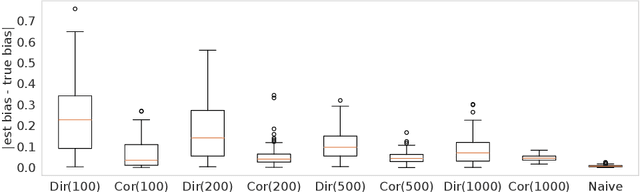
Training and evaluation of fair classifiers is a challenging problem. This is partly due to the fact that most fairness metrics of interest depend on both the sensitive attribute information and label information of the data points. In many scenarios it is not possible to collect large datasets with such information. An alternate approach that is commonly used is to separately train an attribute classifier on data with sensitive attribute information, and then use it later in the ML pipeline to evaluate the bias of a given classifier. While such decoupling helps alleviate the problem of demographic scarcity, it raises several natural questions such as: how should the attribute classifier be trained?, and how should one use a given attribute classifier for accurate bias estimation? In this work we study this question from both theoretical and empirical perspectives. We first experimentally demonstrate that the test accuracy of the attribute classifier is not always correlated with its effectiveness in bias estimation for a downstream model. In order to further investigate this phenomenon, we analyze an idealized theoretical model and characterize the structure of the optimal classifier. Our analysis has surprising and counter-intuitive implications where in certain regimes one might want to distribute the error of the attribute classifier as unevenly as possible among the different subgroups. Based on our analysis we develop heuristics for both training and using attribute classifiers for bias estimation in the data scarce regime. We empirically demonstrate the effectiveness of our approach on real and simulated data.