 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAP3D: Generative Alignment of VLM Latents to Patch-Level Embeddings for 3D Generation
May 27, 2026Recent approaches integrating vision-language models (VLMs) as prompt encoders for generative model conditioning typically rely on expensive end-to-end training or map features to compressed representations, discarding the dense spatial structure required for geometry-aware tasks like 3D asset generation. To address this, we propose GAP3D, a modular, diffusion-based approach that aligns VLM-generated latents directly to the complete, patch-level feature space of a pre-trained image encoder, enabling a frozen downstream generative model to utilize a VLM as prompt encoder while maintaining a spatially structured conditioning signal. Evaluated on 3D asset generation, our method bypasses the need for large-scale 3D data by training mainly on general-domain image-text pairs. It also exhibits emergent zero-shot capabilities for multimodal prompts, despite being trained exclusively on text input. Finally, while currently prioritizing high-level semantics over fine-grained detail, GAP3D demonstrates that the representation gap between VLM and image-encoder feature spaces can be partially bridged through diffusion-based alignment, taking the first steps towards a modular integration of foundation models through generative alignment to dense embedding spaces.
CTRL-O: Language-Controllable Object-Centric Visual Representation Learning
Mar 27, 2025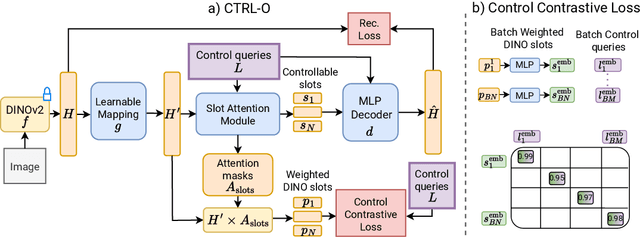

Object-centric representation learning aims to decompose visual scenes into fixed-size vectors called "slots" or "object files", where each slot captures a distinct object. Current state-of-the-art object-centric models have shown remarkable success in object discovery in diverse domains, including complex real-world scenes. However, these models suffer from a key limitation: they lack controllability. Specifically, current object-centric models learn representations based on their preconceived understanding of objects, without allowing user input to guide which objects are represented. Introducing controllability into object-centric models could unlock a range of useful capabilities, such as the ability to extract instance-specific representations from a scene. In this work, we propose a novel approach for user-directed control over slot representations by conditioning slots on language descriptions. The proposed ConTRoLlable Object-centric representation learning approach, which we term CTRL-O, achieves targeted object-language binding in complex real-world scenes without requiring mask supervision. Next, we apply these controllable slot representations on two downstream vision language tasks: text-to-image generation and visual question answering. The proposed approach enables instance-specific text-to-image generation and also achieves strong performance on visual question answering.
SENSEI: Semantic Exploration Guided by Foundation Models to Learn Versatile World Models
Mar 03, 2025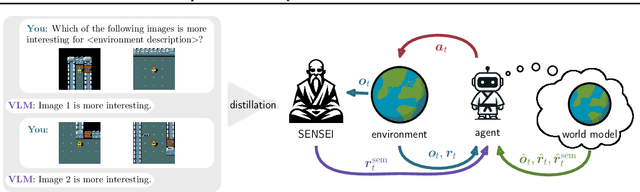
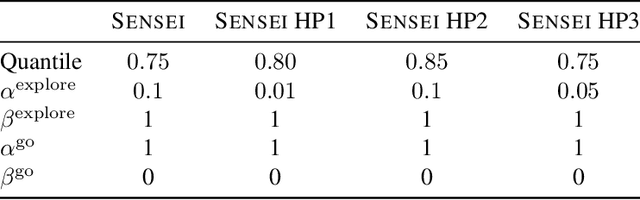
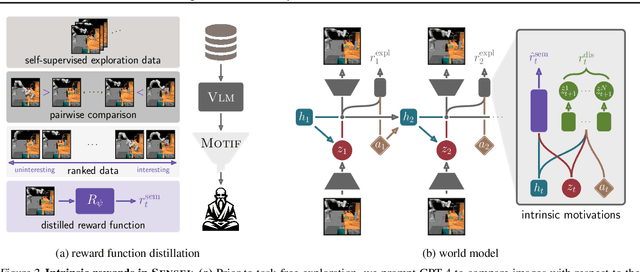
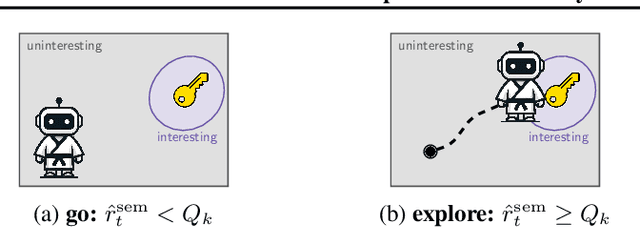
Exploration is a cornerstone of reinforcement learning (RL). Intrinsic motivation attempts to decouple exploration from external, task-based rewards. However, established approaches to intrinsic motivation that follow general principles such as information gain, often only uncover low-level interactions. In contrast, children's play suggests that they engage in meaningful high-level behavior by imitating or interacting with their caregivers. Recent work has focused on using foundation models to inject these semantic biases into exploration. However, these methods often rely on unrealistic assumptions, such as language-embedded environments or access to high-level actions. We propose SEmaNtically Sensible ExploratIon (SENSEI), a framework to equip model-based RL agents with an intrinsic motivation for semantically meaningful behavior. SENSEI distills a reward signal of interestingness from Vision Language Model (VLM) annotations, enabling an agent to predict these rewards through a world model. Using model-based RL, SENSEI trains an exploration policy that jointly maximizes semantic rewards and uncertainty. We show that in both robotic and video game-like simulations SENSEI discovers a variety of meaningful behaviors from image observations and low-level actions. SENSEI provides a general tool for learning from foundation model feedback, a crucial research direction, as VLMs become more powerful.
Dream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
Dec 19, 2024A world model provides an agent with a representation of its environment, enabling it to predict the causal consequences of its actions. Current world models typically cannot directly and explicitly imitate the actual environment in front of a robot, often resulting in unrealistic behaviors and hallucinations that make them unsuitable for real-world applications. In this paper, we introduce a new paradigm for constructing world models that are explicit representations of the real world and its dynamics. By integrating cutting-edge advances in real-time photorealism with Gaussian Splatting and physics simulators, we propose the first compositional manipulation world model, which we call DreMa. DreMa replicates the observed world and its dynamics, allowing it to imagine novel configurations of objects and predict the future consequences of robot actions. We leverage this capability to generate new data for imitation learning by applying equivariant transformations to a small set of demonstrations. Our evaluations across various settings demonstrate significant improvements in both accuracy and robustness by incrementing actions and object distributions, reducing the data needed to learn a policy and improving the generalization of the agents. As a highlight, we show that a real Franka Emika Panda robot, powered by DreMa's imagination, can successfully learn novel physical tasks from just a single example per task variation (one-shot policy learning). Our project page and source code can be found in https://leobarcellona.github.io/DreamToManipulate/
Temporally Consistent Object-Centric Learning by Contrasting Slots
Dec 18, 2024



Unsupervised object-centric learning from videos is a promising approach to extract structured representations from large, unlabeled collections of videos. To support downstream tasks like autonomous control, these representations must be both compositional and temporally consistent. Existing approaches based on recurrent processing often lack long-term stability across frames because their training objective does not enforce temporal consistency. In this work, we introduce a novel object-level temporal contrastive loss for video object-centric models that explicitly promotes temporal consistency. Our method significantly improves the temporal consistency of the learned object-centric representations, yielding more reliable video decompositions that facilitate challenging downstream tasks such as unsupervised object dynamics prediction. Furthermore, the inductive bias added by our loss strongly improves object discovery, leading to state-of-the-art results on both synthetic and real-world datasets, outperforming even weakly-supervised methods that leverage motion masks as additional cues.
Zero-Shot Object-Centric Representation Learning
Aug 17, 2024



The goal of object-centric representation learning is to decompose visual scenes into a structured representation that isolates the entities. Recent successes have shown that object-centric representation learning can be scaled to real-world scenes by utilizing pre-trained self-supervised features. However, so far, object-centric methods have mostly been applied in-distribution, with models trained and evaluated on the same dataset. This is in contrast to the wider trend in machine learning towards general-purpose models directly applicable to unseen data and tasks. Thus, in this work, we study current object-centric methods through the lens of zero-shot generalization by introducing a benchmark comprising eight different synthetic and real-world datasets. We analyze the factors influencing zero-shot performance and find that training on diverse real-world images improves transferability to unseen scenarios. Furthermore, inspired by the success of task-specific fine-tuning in foundation models, we introduce a novel fine-tuning strategy to adapt pre-trained vision encoders for the task of object discovery. We find that the proposed approach results in state-of-the-art performance for unsupervised object discovery, exhibiting strong zero-shot transfer to unseen datasets.
Object-Centric Learning for Real-World Videos by Predicting Temporal Feature Similarities
Jun 07, 2023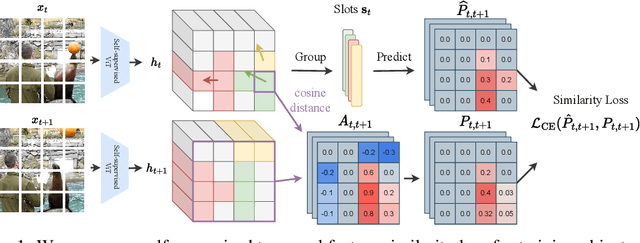
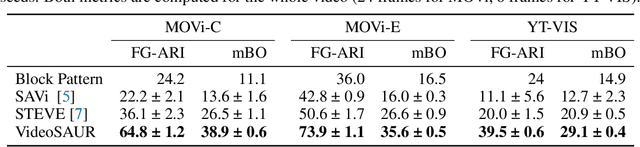
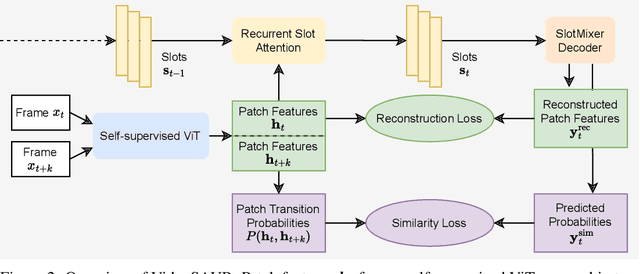

Unsupervised video-based object-centric learning is a promising avenue to learn structured representations from large, unlabeled video collections, but previous approaches have only managed to scale to real-world datasets in restricted domains. Recently, it was shown that the reconstruction of pre-trained self-supervised features leads to object-centric representations on unconstrained real-world image datasets. Building on this approach, we propose a novel way to use such pre-trained features in the form of a temporal feature similarity loss. This loss encodes temporal correlations between image patches and is a natural way to introduce a motion bias for object discovery. We demonstrate that this loss leads to state-of-the-art performance on the challenging synthetic MOVi datasets. When used in combination with the feature reconstruction loss, our model is the first object-centric video model that scales to unconstrained video datasets such as YouTube-VIS.
Bridging the Gap to Real-World Object-Centric Learning
Sep 29, 2022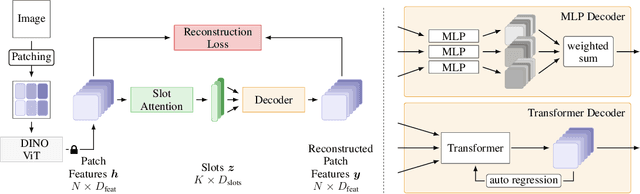
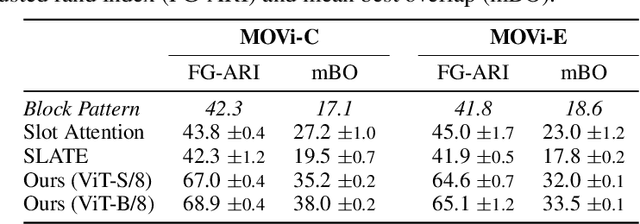


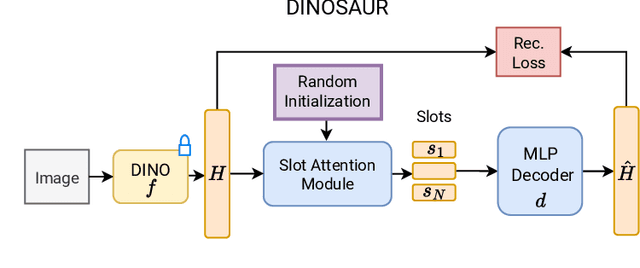
Humans naturally decompose their environment into entities at the appropriate level of abstraction to act in the world. Allowing machine learning algorithms to derive this decomposition in an unsupervised way has become an important line of research. However, current methods are restricted to simulated data or require additional information in the form of motion or depth in order to successfully discover objects. In this work, we overcome this limitation by showing that reconstructing features from models trained in a self-supervised manner is a sufficient training signal for object-centric representations to arise in a fully unsupervised way. Our approach, DINOSAUR, significantly out-performs existing object-centric learning models on simulated data and is the first unsupervised object-centric model that scales to real world-datasets such as COCO and PASCAL VOC. DINOSAUR is conceptually simple and shows competitive performance compared to more involved pipelines from the computer vision literature.
Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
Jul 11, 2022

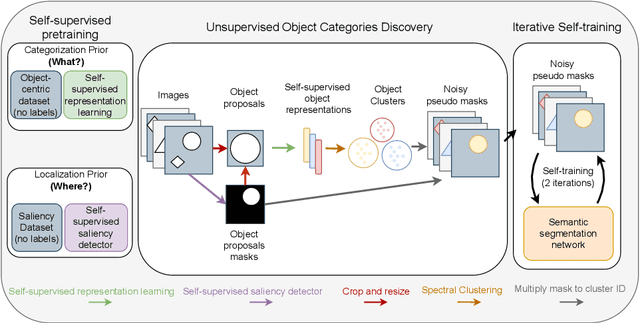
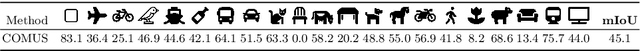
In this paper, we show that recent advances in self-supervised feature learning enable unsupervised object discovery and semantic segmentation with a performance that matches the state of the field on supervised semantic segmentation 10 years ago. We propose a methodology based on unsupervised saliency masks and self-supervised feature clustering to kickstart object discovery followed by training a semantic segmentation network on pseudo-labels to bootstrap the system on images with multiple objects. We present results on PASCAL VOC that go far beyond the current state of the art (47.3 mIoU), and we report for the first time results on MS COCO for the whole set of 81 classes: our method discovers 34 categories with more than $20\%$ IoU, while obtaining an average IoU of 19.6 for all 81 categories.
Self-supervised Reinforcement Learning with Independently Controllable Subgoals
Sep 09, 2021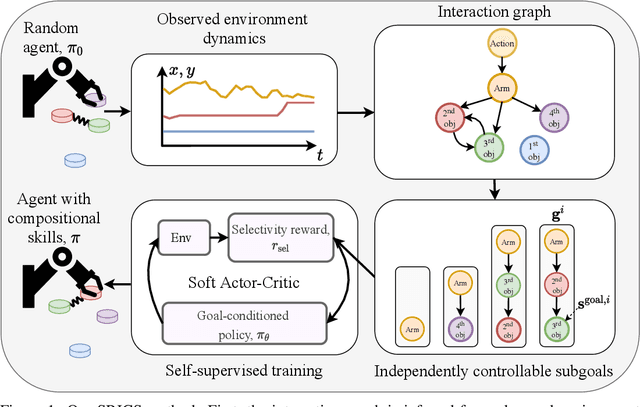

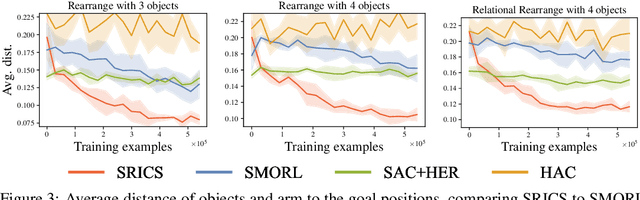
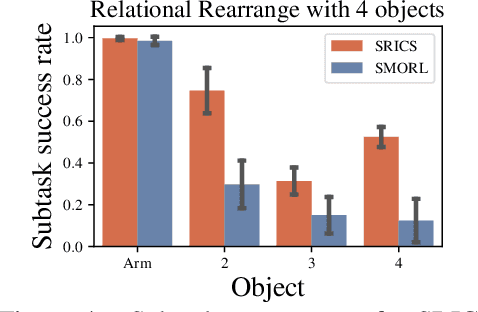
To successfully tackle challenging manipulation tasks, autonomous agents must learn a diverse set of skills and how to combine them. Recently, self-supervised agents that set their own abstract goals by exploiting the discovered structure in the environment were shown to perform well on many different tasks. In particular, some of them were applied to learn basic manipulation skills in compositional multi-object environments. However, these methods learn skills without taking the dependencies between objects into account. Thus, the learned skills are difficult to combine in realistic environments. We propose a novel self-supervised agent that estimates relations between environment components and uses them to independently control different parts of the environment state. In addition, the estimated relations between objects can be used to decompose a complex goal into a compatible sequence of subgoals. We show that, by using this framework, an agent can efficiently and automatically learn manipulation tasks in multi-object environments with different relations between objects.