 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoComposition: Terrain-Adaptive Energy-Efficient Quadruped Locomotion without Gait Priors
Jun 14, 2026Learning-based quadrupedal locomotion typically relies on complex reward formulations that entangle task specification, operational limits, gait preference, and terrain adaptation within a single optimization objective. We instead treat these functions through distinct mechanisms: rewards for task specification, constraints for operational limits, energy minimization for gait preference, and exteroceptive perception for adapting energy use to terrain difficulty. We show that these components jointly enable efficient, terrain-adaptive locomotion, and that removing each component exposes a distinct failure mode. Our formulation removes explicit gait priors (including air-time, contact-count, and foot-clearance targets) in favor of emergent behavior. Compared to a conventional complex-reward baseline, our formulation achieves comparable terrain traversal while reducing cost of transport by 56% and operational-limit violations by 96%. The resulting policies transfer zero-shot to a physical Unitree Go2 using LiDAR-based elevation mapping. Project website with videos: https://tinyurl.com/locomposition.
GASP: Guided Asymmetric Self-Play For Coding LLMs
Mar 16, 2026Asymmetric self-play has emerged as a promising paradigm for post-training large language models, where a teacher continually generates questions for a student to solve at the edge of the student's learnability. Although these methods promise open-ended data generation bootstrapped from no human data, they suffer from one major problem: not all problems that are hard to solve are interesting or informative to improve the overall capabilities of the model. Current asymmetric self-play methods are goal-agnostic with no real grounding. We propose Guided Asymmetric Self-Play (GASP), where grounding is provided by real-data goalpost questions that are identified to pose a hard exploration challenge to the model. During self-play, the teacher first generates an easier variant of a hard question, and then a harder variant of that easier question, with the goal of gradually closing the gap to the goalpost throughout training. Doing so, we improve pass@20 on LiveCodeBench (LCB) by 2.5% over unguided asymmetric self-play, and through the curriculum constructed by the teacher, we manage to solve hard goalpost questions that remain out of reach for all baselines.
Stochastic Decision Horizons for Constrained Reinforcement Learning
Feb 04, 2026Constrained Markov decision processes (CMDPs) provide a principled model for handling constraints, such as safety and other auxiliary objectives, in reinforcement learning. The common approach of using additive-cost constraints and dual variables often hinders off-policy scalability. We propose a Control as Inference formulation based on stochastic decision horizons, where constraint violations attenuate reward contributions and shorten the effective planning horizon via state-action-dependent continuation. This yields survival-weighted objectives that remain replay-compatible for off-policy actor-critic learning. We propose two violation semantics, absorbing and virtual termination, that share the same survival-weighted return but result in distinct optimization structures that lead to SAC/MPO-style policy improvement. Experiments demonstrate improved sample efficiency and favorable return-violation trade-offs on standard benchmarks. Moreover, MPO with virtual termination (VT-MPO) scales effectively to our high-dimensional musculoskeletal Hyfydy setup.
SENSEI: Semantic Exploration Guided by Foundation Models to Learn Versatile World Models
Mar 03, 2025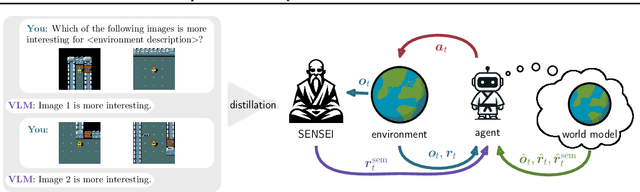
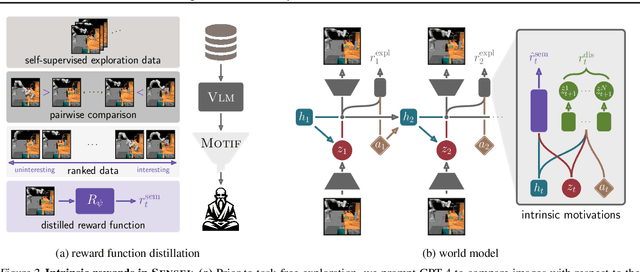
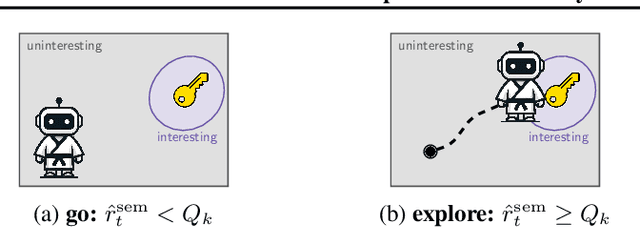
Exploration is a cornerstone of reinforcement learning (RL). Intrinsic motivation attempts to decouple exploration from external, task-based rewards. However, established approaches to intrinsic motivation that follow general principles such as information gain, often only uncover low-level interactions. In contrast, children's play suggests that they engage in meaningful high-level behavior by imitating or interacting with their caregivers. Recent work has focused on using foundation models to inject these semantic biases into exploration. However, these methods often rely on unrealistic assumptions, such as language-embedded environments or access to high-level actions. We propose SEmaNtically Sensible ExploratIon (SENSEI), a framework to equip model-based RL agents with an intrinsic motivation for semantically meaningful behavior. SENSEI distills a reward signal of interestingness from Vision Language Model (VLM) annotations, enabling an agent to predict these rewards through a world model. Using model-based RL, SENSEI trains an exploration policy that jointly maximizes semantic rewards and uncertainty. We show that in both robotic and video game-like simulations SENSEI discovers a variety of meaningful behaviors from image observations and low-level actions. SENSEI provides a general tool for learning from foundation model feedback, a crucial research direction, as VLMs become more powerful.
Dual-Force: Enhanced Offline Diversity Maximization under Imitation Constraints
Jan 08, 2025


While many algorithms for diversity maximization under imitation constraints are online in nature, many applications require offline algorithms without environment interactions. Tackling this problem in the offline setting, however, presents significant challenges that require non-trivial, multi-stage optimization processes with non-stationary rewards. In this work, we present a novel offline algorithm that enhances diversity using an objective based on Van der Waals (VdW) force and successor features, and eliminates the need to learn a previously used skill discriminator. Moreover, by conditioning the value function and policy on a pre-trained Functional Reward Encoding (FRE), our method allows for better handling of non-stationary rewards and provides zero-shot recall of all skills encountered during training, significantly expanding the set of skills learned in prior work. Consequently, our algorithm benefits from receiving a consistently strong diversity signal (VdW), and enjoys more stable and efficient training. We demonstrate the effectiveness of our method in generating diverse skills for two robotic tasks in simulation: locomotion of a quadruped and local navigation with obstacle traversal.
Learning Diverse Skills for Local Navigation under Multi-constraint Optimality
Oct 03, 2023



Despite many successful applications of data-driven control in robotics, extracting meaningful diverse behaviors remains a challenge. Typically, task performance needs to be compromised in order to achieve diversity. In many scenarios, task requirements are specified as a multitude of reward terms, each requiring a different trade-off. In this work, we take a constrained optimization viewpoint on the quality-diversity trade-off and show that we can obtain diverse policies while imposing constraints on their value functions which are defined through distinct rewards. In line with previous work, further control of the diversity level can be achieved through an attract-repel reward term motivated by the Van der Waals force. We demonstrate the effectiveness of our method on a local navigation task where a quadruped robot needs to reach the target within a finite horizon. Finally, our trained policies transfer well to the real 12-DoF quadruped robot, Solo12, and exhibit diverse agile behaviors with successful obstacle traversal.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
Jul 28, 2023



Learning policies from previously recorded data is a promising direction for real-world robotics tasks, as online learning is often infeasible. Dexterous manipulation in particular remains an open problem in its general form. The combination of offline reinforcement learning with large diverse datasets, however, has the potential to lead to a breakthrough in this challenging domain analogously to the rapid progress made in supervised learning in recent years. To coordinate the efforts of the research community toward tackling this problem, we propose a benchmark including: i) a large collection of data for offline learning from a dexterous manipulation platform on two tasks, obtained with capable RL agents trained in simulation; ii) the option to execute learned policies on a real-world robotic system and a simulation for efficient debugging. We evaluate prominent open-sourced offline reinforcement learning algorithms on the datasets and provide a reproducible experimental setup for offline reinforcement learning on real systems.
Diverse Offline Imitation via Fenchel Duality
Jul 21, 2023



There has been significant recent progress in the area of unsupervised skill discovery, with various works proposing mutual information based objectives, as a source of intrinsic motivation. Prior works predominantly focused on designing algorithms that require online access to the environment. In contrast, we develop an \textit{offline} skill discovery algorithm. Our problem formulation considers the maximization of a mutual information objective constrained by a KL-divergence. More precisely, the constraints ensure that the state occupancy of each skill remains close to the state occupancy of an expert, within the support of an offline dataset with good state-action coverage. Our main contribution is to connect Fenchel duality, reinforcement learning and unsupervised skill discovery, and to give a simple offline algorithm for learning diverse skills that are aligned with an expert.
On Imitation in Mean-field Games
Jun 26, 2023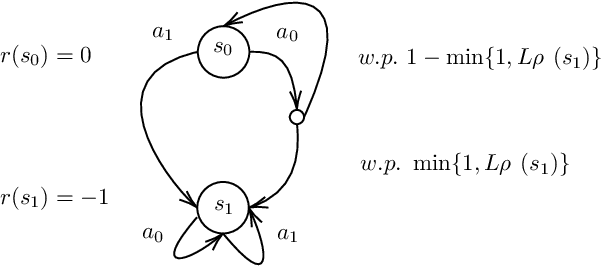
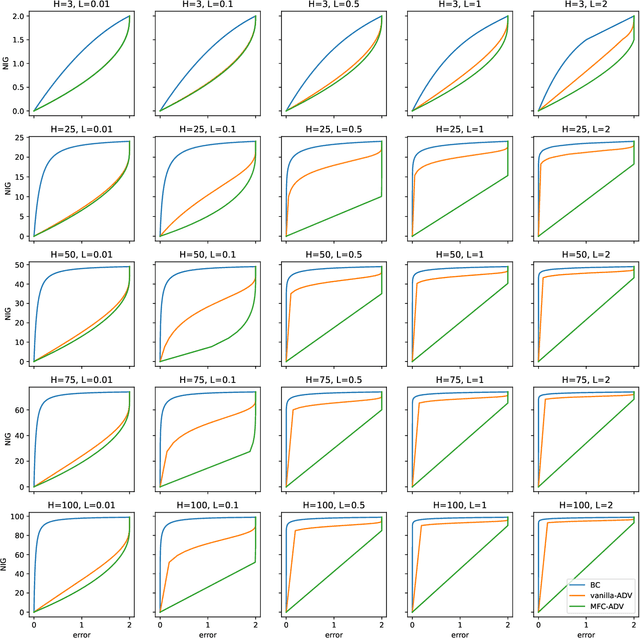
We explore the problem of imitation learning (IL) in the context of mean-field games (MFGs), where the goal is to imitate the behavior of a population of agents following a Nash equilibrium policy according to some unknown payoff function. IL in MFGs presents new challenges compared to single-agent IL, particularly when both the reward function and the transition kernel depend on the population distribution. In this paper, departing from the existing literature on IL for MFGs, we introduce a new solution concept called the Nash imitation gap. Then we show that when only the reward depends on the population distribution, IL in MFGs can be reduced to single-agent IL with similar guarantees. However, when the dynamics is population-dependent, we provide a novel upper-bound that suggests IL is harder in this setting. To address this issue, we propose a new adversarial formulation where the reinforcement learning problem is replaced by a mean-field control (MFC) problem, suggesting progress in IL within MFGs may have to build upon MFC.