 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperhuman Safe and Agile Racing through Multi-Agent Reinforcement Learning
May 21, 2026Autonomous systems have achieved superhuman performance in isolation or simulation, yet they remain brittle in shared, dynamic real-world spaces. This failure stems from the dominant single-agent paradigm for physical applications, where other actors are ignored or treated as environmental noise, preventing effective coordination. Here we show that multi-agent reinforcement learning provides the essential safety scaffolding required for real-world interaction. Using high-speed quadrotor racing as a high-stakes testbed, we train agents to navigate complex aerodynamic interactions and strategic maneuvering with a variable number of racers. Through league-based self-play, agents evolve sophisticated anticipatory behaviors, including proactive collision avoidance, overtaking, and handling multi-agent physical interactions, including aerodynamic downwash. Our agents outperform a champion-level human pilot in multi-player races at speeds exceeding 22 m/s, while simultaneously reducing collision rates by 50 % compared to state-of-the-art single-agent baselines. Crucially, training with diverse artificial agents enables zero-shot generalization to safer human interaction. These results suggest that the path to robust robotic co-existence lies not in isolated safety constraints, but in the rigorous demands of multi-agent interaction. Multimedia materials are available at: https://rpg.ifi.uzh.ch/marl
What Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
Improving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
Sep 17, 2025Improved low-frequency sensitivity of gravitational wave observatories would unlock study of intermediate-mass black hole mergers, binary black hole eccentricity, and provide early warnings for multi-messenger observations of binary neutron star mergers. Today's mirror stabilization control injects harmful noise, constituting a major obstacle to sensitivity improvements. We eliminated this noise through Deep Loop Shaping, a reinforcement learning method using frequency domain rewards. We proved our methodology on the LIGO Livingston Observatory (LLO). Our controller reduced control noise in the 10--30Hz band by over 30x, and up to 100x in sub-bands surpassing the design goal motivated by the quantum limit. These results highlight the potential of Deep Loop Shaping to improve current and future GW observatories, and more broadly instrumentation and control systems.
Value from Observations: Towards Large-Scale Imitation Learning via Self-Improvement
Jul 09, 2025Imitation Learning from Observation (IfO) offers a powerful way to learn behaviors at large-scale: Unlike behavior cloning or offline reinforcement learning, IfO can leverage action-free demonstrations and thus circumvents the need for costly action-labeled demonstrations or reward functions. However, current IfO research focuses on idealized scenarios with mostly bimodal-quality data distributions, restricting the meaningfulness of the results. In contrast, this paper investigates more nuanced distributions and introduces a method to learn from such data, moving closer to a paradigm in which imitation learning can be performed iteratively via self-improvement. Our method adapts RL-based imitation learning to action-free demonstrations, using a value function to transfer information between expert and non-expert data. Through comprehensive evaluation, we delineate the relation between different data distributions and the applicability of algorithms and highlight the limitations of established methods. Our findings provide valuable insights for developing more robust and practical IfO techniques on a path to scalable behaviour learning.
Inside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Jun 25, 2025



Navigating everyday social situations often requires juggling conflicting goals, such as conveying a harsh truth, maintaining trust, all while still being mindful of another person's feelings. These value trade-offs are an integral part of human decision-making and language use, however, current tools for interpreting such dynamic and multi-faceted notions of values in LLMs are limited. In cognitive science, so-called "cognitive models" provide formal accounts of these trade-offs in humans, by modeling the weighting of a speaker's competing utility functions in choosing an action or utterance. In this work, we use a leading cognitive model of polite speech to interpret the extent to which LLMs represent human-like trade-offs. We apply this lens to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning "effort" in frontier black-box models, and RL post-training dynamics of open-source models. Our results highlight patterns of higher informational utility than social utility in reasoning models, and in open-source models shown to be stronger in mathematical reasoning. Our findings from LLMs' training dynamics suggest large shifts in utility values early on in training with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method. We show that our method is responsive to diverse aspects of the rapidly evolving LLM landscape, with insights for forming hypotheses about other high-level behaviors, shaping training regimes for reasoning models, and better controlling trade-offs between values during model training.
The AI Imperative: Scaling High-Quality Peer Review in Machine Learning
Jun 09, 2025Peer review, the bedrock of scientific advancement in machine learning (ML), is strained by a crisis of scale. Exponential growth in manuscript submissions to premier ML venues such as NeurIPS, ICML, and ICLR is outpacing the finite capacity of qualified reviewers, leading to concerns about review quality, consistency, and reviewer fatigue. This position paper argues that AI-assisted peer review must become an urgent research and infrastructure priority. We advocate for a comprehensive AI-augmented ecosystem, leveraging Large Language Models (LLMs) not as replacements for human judgment, but as sophisticated collaborators for authors, reviewers, and Area Chairs (ACs). We propose specific roles for AI in enhancing factual verification, guiding reviewer performance, assisting authors in quality improvement, and supporting ACs in decision-making. Crucially, we contend that the development of such systems hinges on access to more granular, structured, and ethically-sourced peer review process data. We outline a research agenda, including illustrative experiments, to develop and validate these AI assistants, and discuss significant technical and ethical challenges. We call upon the ML community to proactively build this AI-assisted future, ensuring the continued integrity and scalability of scientific validation, while maintaining high standards of peer review.
LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Apr 22, 2025The success of Large Language Models (LLMs) has sparked interest in various agentic applications. A key hypothesis is that LLMs, leveraging common sense and Chain-of-Thought (CoT) reasoning, can effectively explore and efficiently solve complex domains. However, LLM agents have been found to suffer from sub-optimal exploration and the knowing-doing gap, the inability to effectively act on knowledge present in the model. In this work, we systematically study why LLMs perform sub-optimally in decision-making scenarios. In particular, we closely examine three prevalent failure modes: greediness, frequency bias, and the knowing-doing gap. We propose mitigation of these shortcomings by fine-tuning via Reinforcement Learning (RL) on self-generated CoT rationales. Our experiments across multi-armed bandits, contextual bandits, and Tic-tac-toe, demonstrate that RL fine-tuning enhances the decision-making abilities of LLMs by increasing exploration and narrowing the knowing-doing gap. Finally, we study both classic exploration mechanisms, such as $\epsilon$-greedy, and LLM-specific approaches, such as self-correction and self-consistency, to enable more effective fine-tuning of LLMs for decision-making.
Imitating Language via Scalable Inverse Reinforcement Learning
Sep 02, 2024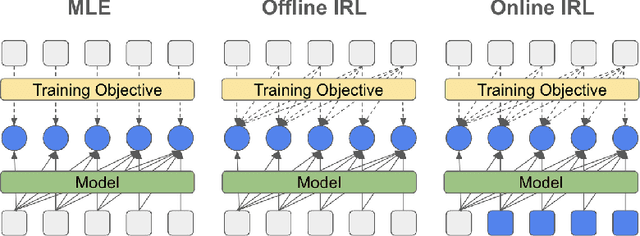
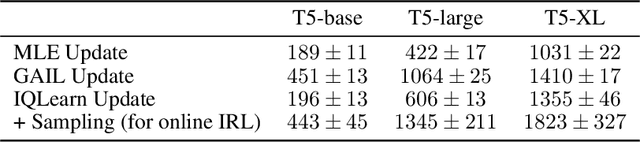
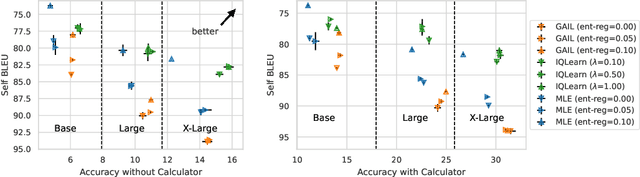

The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
Learning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
May 03, 2024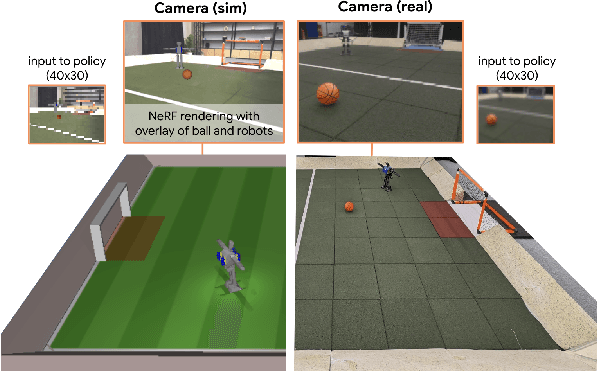
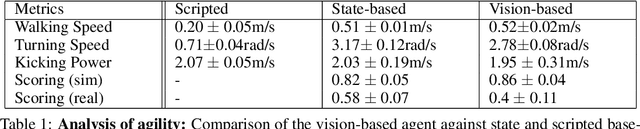
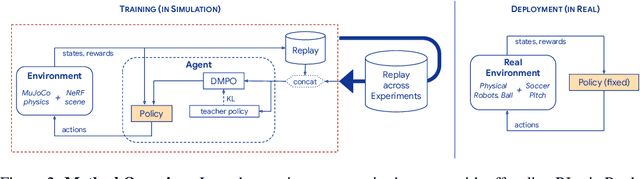
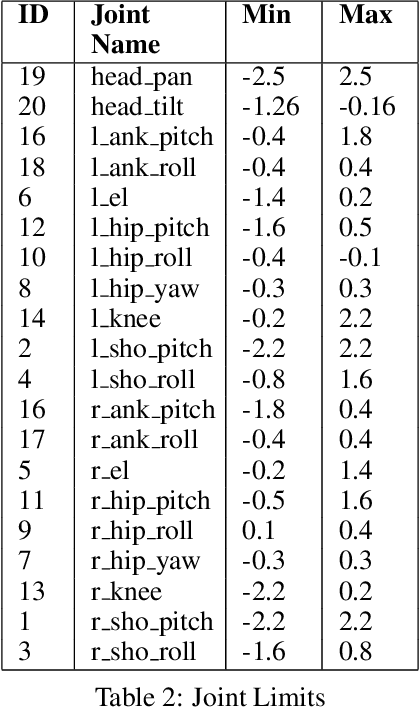
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Growing Q-Networks: Solving Continuous Control Tasks with Adaptive Control Resolution
Apr 05, 2024



Recent reinforcement learning approaches have shown surprisingly strong capabilities of bang-bang policies for solving continuous control benchmarks. The underlying coarse action space discretizations often yield favourable exploration characteristics while final performance does not visibly suffer in the absence of action penalization in line with optimal control theory. In robotics applications, smooth control signals are commonly preferred to reduce system wear and energy efficiency, but action costs can be detrimental to exploration during early training. In this work, we aim to bridge this performance gap by growing discrete action spaces from coarse to fine control resolution, taking advantage of recent results in decoupled Q-learning to scale our approach to high-dimensional action spaces up to dim(A) = 38. Our work indicates that an adaptive control resolution in combination with value decomposition yields simple critic-only algorithms that yield surprisingly strong performance on continuous control tasks.