 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robot Soccer from Egocentric Vision with Deep Reinforcement Learning
May 03, 2024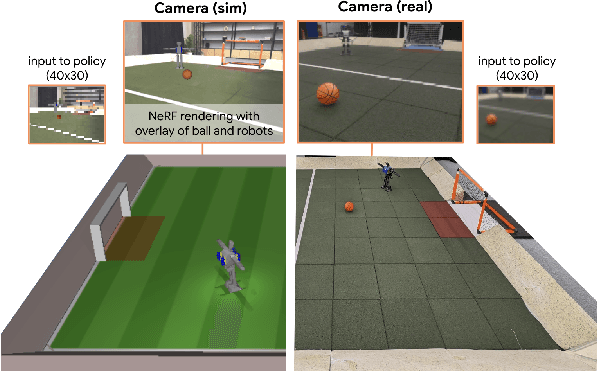
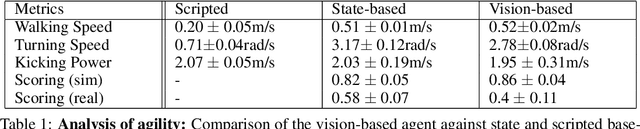
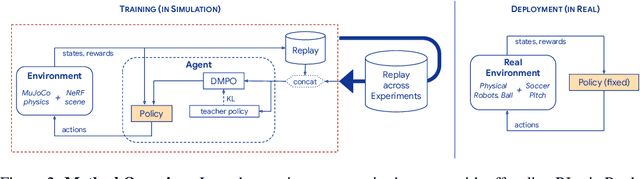
We apply multi-agent deep reinforcement learning (RL) to train end-to-end robot soccer policies with fully onboard computation and sensing via egocentric RGB vision. This setting reflects many challenges of real-world robotics, including active perception, agile full-body control, and long-horizon planning in a dynamic, partially-observable, multi-agent domain. We rely on large-scale, simulation-based data generation to obtain complex behaviors from egocentric vision which can be successfully transferred to physical robots using low-cost sensors. To achieve adequate visual realism, our simulation combines rigid-body physics with learned, realistic rendering via multiple Neural Radiance Fields (NeRFs). We combine teacher-based multi-agent RL and cross-experiment data reuse to enable the discovery of sophisticated soccer strategies. We analyze active-perception behaviors including object tracking and ball seeking that emerge when simply optimizing perception-agnostic soccer play. The agents display equivalent levels of performance and agility as policies with access to privileged, ground-truth state. To our knowledge, this paper constitutes a first demonstration of end-to-end training for multi-agent robot soccer, mapping raw pixel observations to joint-level actions, that can be deployed in the real world. Videos of the game-play and analyses can be seen on our website https://sites.google.com/view/vision-soccer .
Replay across Experiments: A Natural Extension of Off-Policy RL
Nov 28, 2023



Replaying data is a principal mechanism underlying the stability and data efficiency of off-policy reinforcement learning (RL). We present an effective yet simple framework to extend the use of replays across multiple experiments, minimally adapting the RL workflow for sizeable improvements in controller performance and research iteration times. At its core, Replay Across Experiments (RaE) involves reusing experience from previous experiments to improve exploration and bootstrap learning while reducing required changes to a minimum in comparison to prior work. We empirically show benefits across a number of RL algorithms and challenging control domains spanning both locomotion and manipulation, including hard exploration tasks from egocentric vision. Through comprehensive ablations, we demonstrate robustness to the quality and amount of data available and various hyperparameter choices. Finally, we discuss how our approach can be applied more broadly across research life cycles and can increase resilience by reloading data across random seeds or hyperparameter variations.
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
Apr 26, 2023We investigate whether Deep Reinforcement Learning (Deep RL) is able to synthesize sophisticated and safe movement skills for a low-cost, miniature humanoid robot that can be composed into complex behavioral strategies in dynamic environments. We used Deep RL to train a humanoid robot with 20 actuated joints to play a simplified one-versus-one (1v1) soccer game. We first trained individual skills in isolation and then composed those skills end-to-end in a self-play setting. The resulting policy exhibits robust and dynamic movement skills such as rapid fall recovery, walking, turning, kicking and more; and transitions between them in a smooth, stable, and efficient manner - well beyond what is intuitively expected from the robot. The agents also developed a basic strategic understanding of the game, and learned, for instance, to anticipate ball movements and to block opponent shots. The full range of behaviors emerged from a small set of simple rewards. Our agents were trained in simulation and transferred to real robots zero-shot. We found that a combination of sufficiently high-frequency control, targeted dynamics randomization, and perturbations during training in simulation enabled good-quality transfer, despite significant unmodeled effects and variations across robot instances. Although the robots are inherently fragile, minor hardware modifications together with basic regularization of the behavior during training led the robots to learn safe and effective movements while still performing in a dynamic and agile way. Indeed, even though the agents were optimized for scoring, in experiments they walked 156% faster, took 63% less time to get up, and kicked 24% faster than a scripted baseline, while efficiently combining the skills to achieve the longer term objectives. Examples of the emergent behaviors and full 1v1 matches are available on the supplementary website.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021

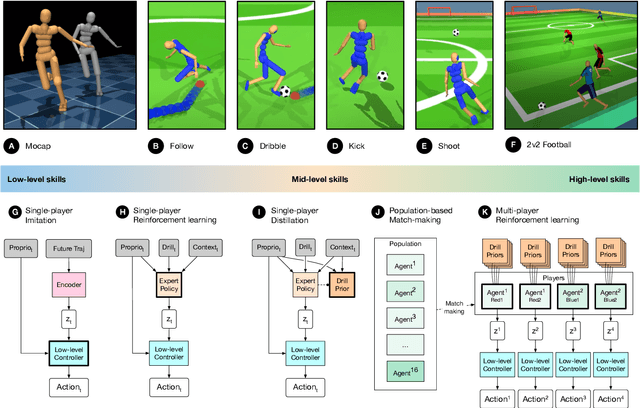

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Biases for Emergent Communication in Multi-agent Reinforcement Learning
Dec 11, 2019
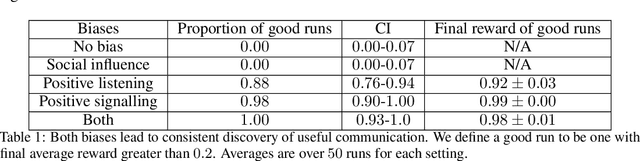
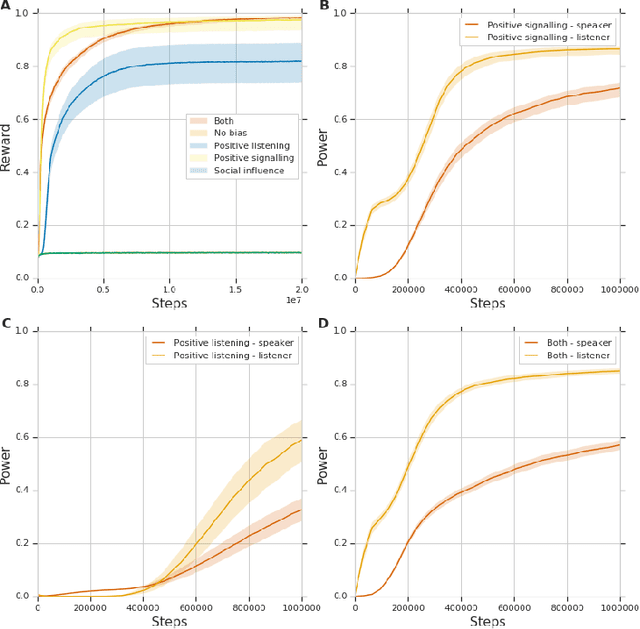
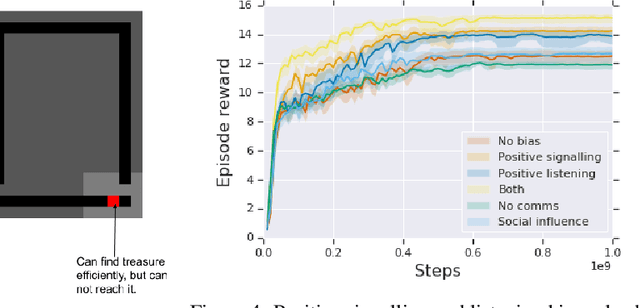
We study the problem of emergent communication, in which language arises because speakers and listeners must communicate information in order to solve tasks. In temporally extended reinforcement learning domains, it has proved hard to learn such communication without centralized training of agents, due in part to a difficult joint exploration problem. We introduce inductive biases for positive signalling and positive listening, which ease this problem. In a simple one-step environment, we demonstrate how these biases ease the learning problem. We also apply our methods to a more extended environment, showing that agents with these inductive biases achieve better performance, and analyse the resulting communication protocols.
A Generalized Training Approach for Multiagent Learning
Sep 27, 2019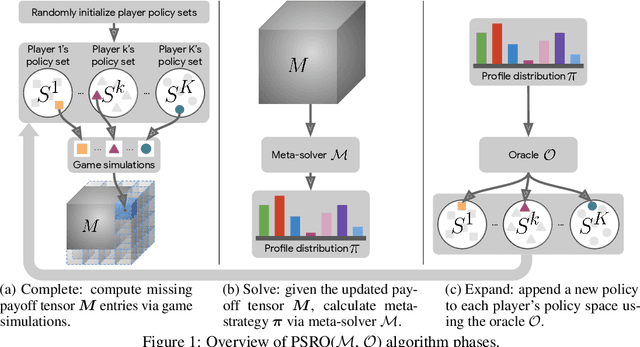
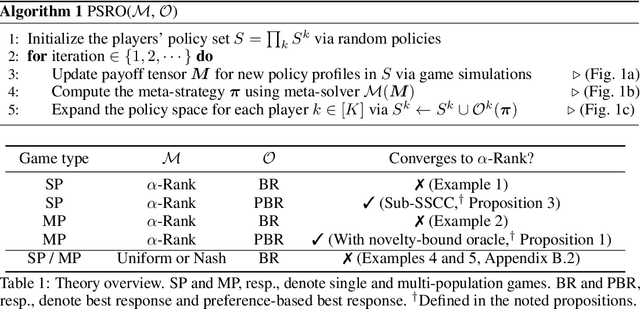
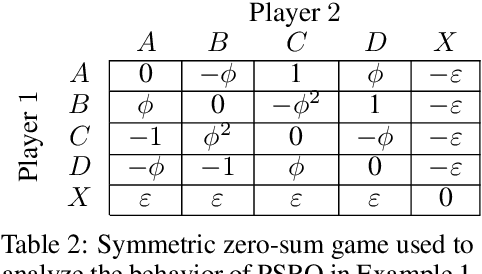
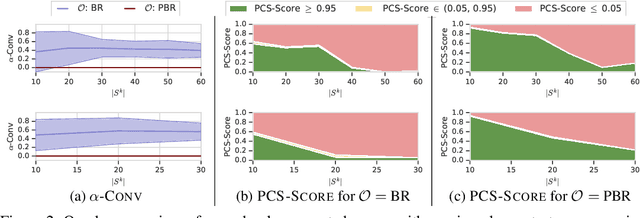
This paper investigates a population-based training regime based on game-theoretic principles called Policy-Spaced Response Oracles (PSRO). PSRO is general in the sense that it (1) encompasses well-known algorithms such as fictitious play and double oracle as special cases, and (2) in principle applies to general-sum, many-player games. Despite this, prior studies of PSRO have been focused on two-player zero-sum games, a regime wherein Nash equilibria are tractably computable. In moving from two-player zero-sum games to more general settings, computation of Nash equilibria quickly becomes infeasible. Here, we extend the theoretical underpinnings of PSRO by considering an alternative solution concept, {\alpha}-Rank, which is unique (thus faces no equilibrium selection issues, unlike Nash) and tractable to compute in general-sum, many-player settings. We establish convergence guarantees in several games classes, and identify links between Nash equilibria and {\alpha}-Rank. We demonstrate the competitive performance of {\alpha}-Rank-based PSRO against an exact Nash solver-based PSRO in 2-player Kuhn and Leduc Poker. We then go beyond the reach of prior PSRO applications by considering 3- to 5-player poker games, yielding instances where {\alpha}-Rank achieves faster convergence than approximate Nash solvers, thus establishing it as a favorable general games solver. We also carry out an initial empirical validation in MuJoCo soccer, illustrating the feasibility of the proposed approach in another complex domain.
Emergent Coordination Through Competition
Feb 21, 2019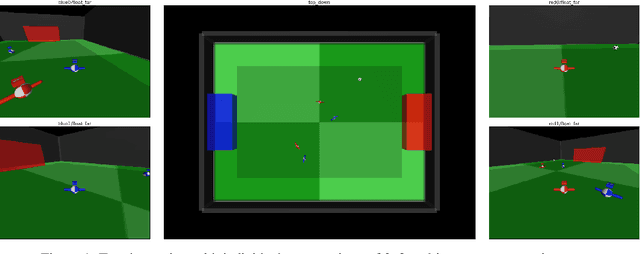
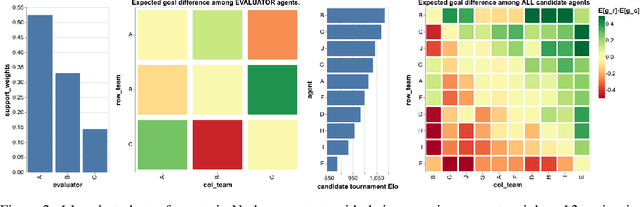
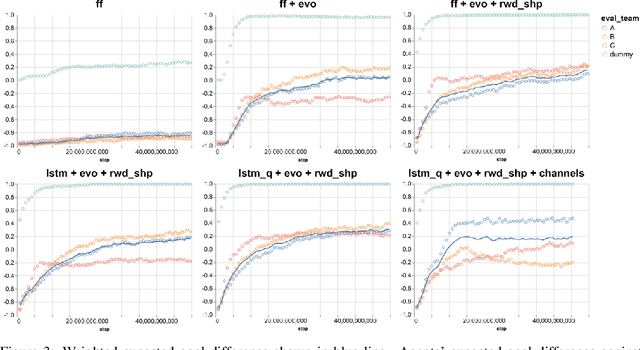
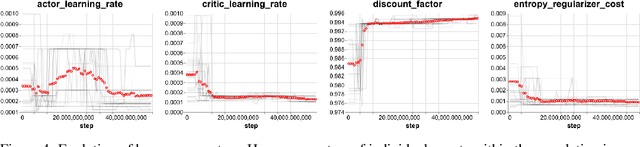
We study the emergence of cooperative behaviors in reinforcement learning agents by introducing a challenging competitive multi-agent soccer environment with continuous simulated physics. We demonstrate that decentralized, population-based training with co-play can lead to a progression in agents' behaviors: from random, to simple ball chasing, and finally showing evidence of cooperation. Our study highlights several of the challenges encountered in large scale multi-agent training in continuous control. In particular, we demonstrate that the automatic optimization of simple shaping rewards, not themselves conducive to co-operative behavior, can lead to long-horizon team behavior. We further apply an evaluation scheme, grounded by game theoretic principals, that can assess agent performance in the absence of pre-defined evaluation tasks or human baselines.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Jun 16, 2017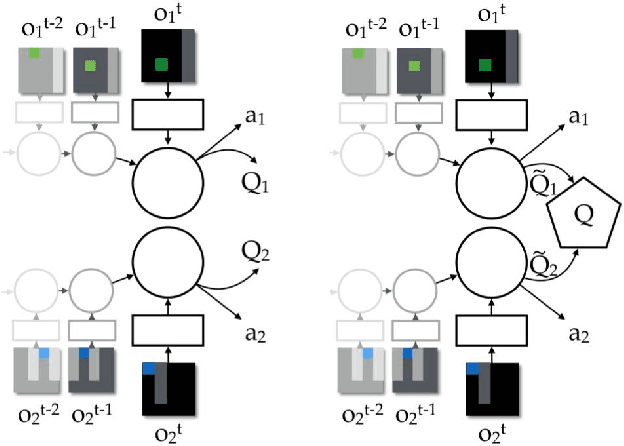
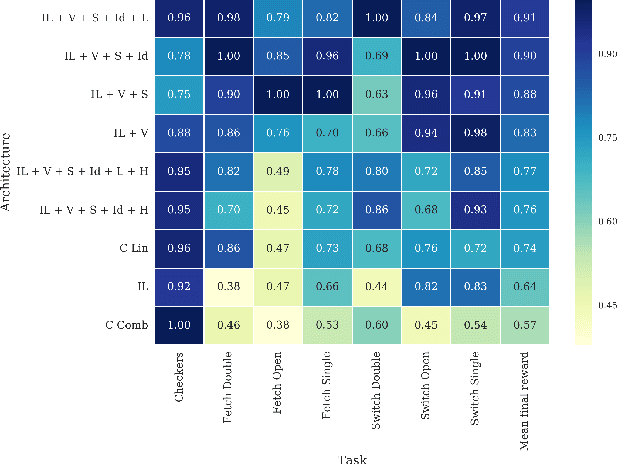
We study the problem of cooperative multi-agent reinforcement learning with a single joint reward signal. This class of learning problems is difficult because of the often large combined action and observation spaces. In the fully centralized and decentralized approaches, we find the problem of spurious rewards and a phenomenon we call the "lazy agent" problem, which arises due to partial observability. We address these problems by training individual agents with a novel value decomposition network architecture, which learns to decompose the team value function into agent-wise value functions. We perform an experimental evaluation across a range of partially-observable multi-agent domains and show that learning such value-decompositions leads to superior results, in particular when combined with weight sharing, role information and information channels.