 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Aug 09, 2024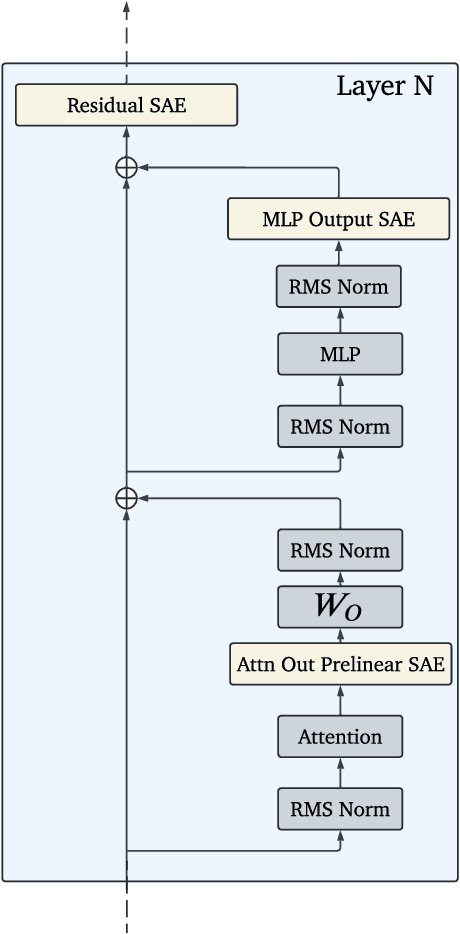
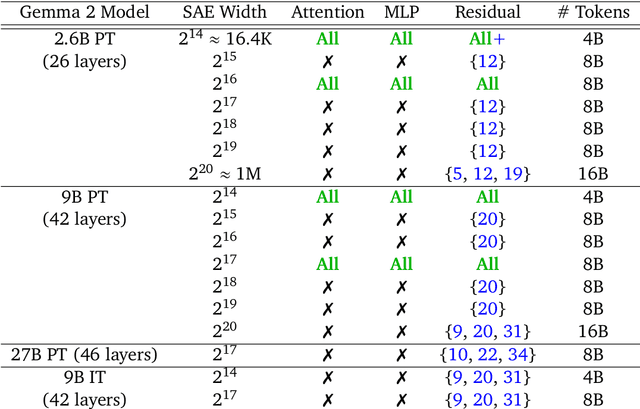
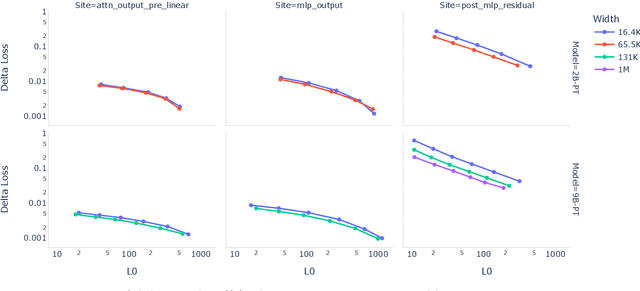
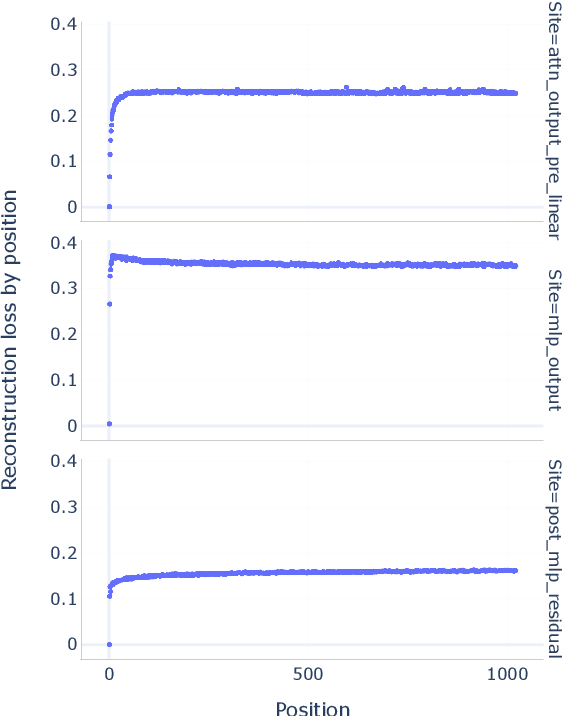
Sparse autoencoders (SAEs) are an unsupervised method for learning a sparse decomposition of a neural network's latent representations into seemingly interpretable features. Despite recent excitement about their potential, research applications outside of industry are limited by the high cost of training a comprehensive suite of SAEs. In this work, we introduce Gemma Scope, an open suite of JumpReLU SAEs trained on all layers and sub-layers of Gemma 2 2B and 9B and select layers of Gemma 2 27B base models. We primarily train SAEs on the Gemma 2 pre-trained models, but additionally release SAEs trained on instruction-tuned Gemma 2 9B for comparison. We evaluate the quality of each SAE on standard metrics and release these results. We hope that by releasing these SAE weights, we can help make more ambitious safety and interpretability research easier for the community. Weights and a tutorial can be found at https://huggingface.co/google/gemma-scope and an interactive demo can be found at https://www.neuronpedia.org/gemma-scope
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Jul 19, 2024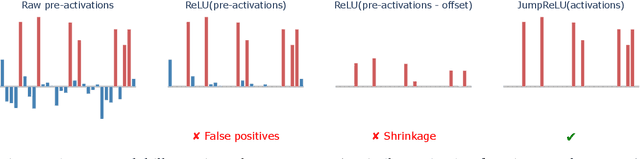
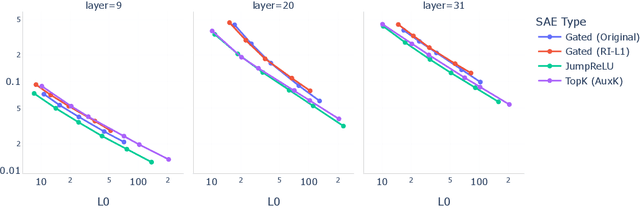
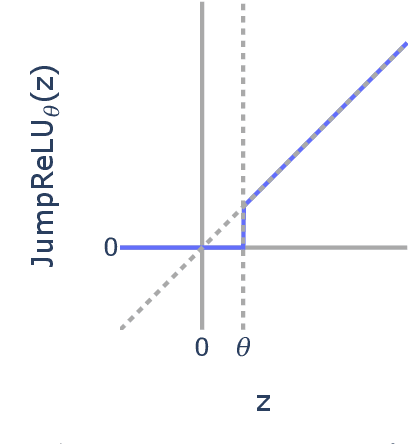
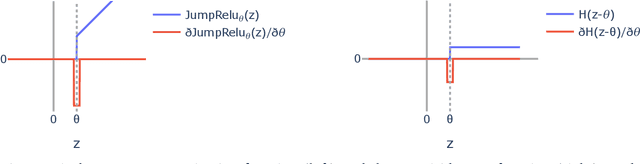
Sparse autoencoders (SAEs) are a promising unsupervised approach for identifying causally relevant and interpretable linear features in a language model's (LM) activations. To be useful for downstream tasks, SAEs need to decompose LM activations faithfully; yet to be interpretable the decomposition must be sparse -- two objectives that are in tension. In this paper, we introduce JumpReLU SAEs, which achieve state-of-the-art reconstruction fidelity at a given sparsity level on Gemma 2 9B activations, compared to other recent advances such as Gated and TopK SAEs. We also show that this improvement does not come at the cost of interpretability through manual and automated interpretability studies. JumpReLU SAEs are a simple modification of vanilla (ReLU) SAEs -- where we replace the ReLU with a discontinuous JumpReLU activation function -- and are similarly efficient to train and run. By utilising straight-through-estimators (STEs) in a principled manner, we show how it is possible to train JumpReLU SAEs effectively despite the discontinuous JumpReLU function introduced in the SAE's forward pass. Similarly, we use STEs to directly train L0 to be sparse, instead of training on proxies such as L1, avoiding problems like shrinkage.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search
Nov 06, 2023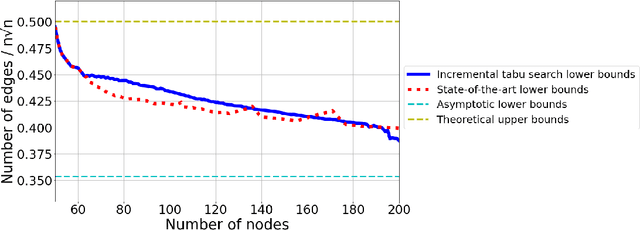
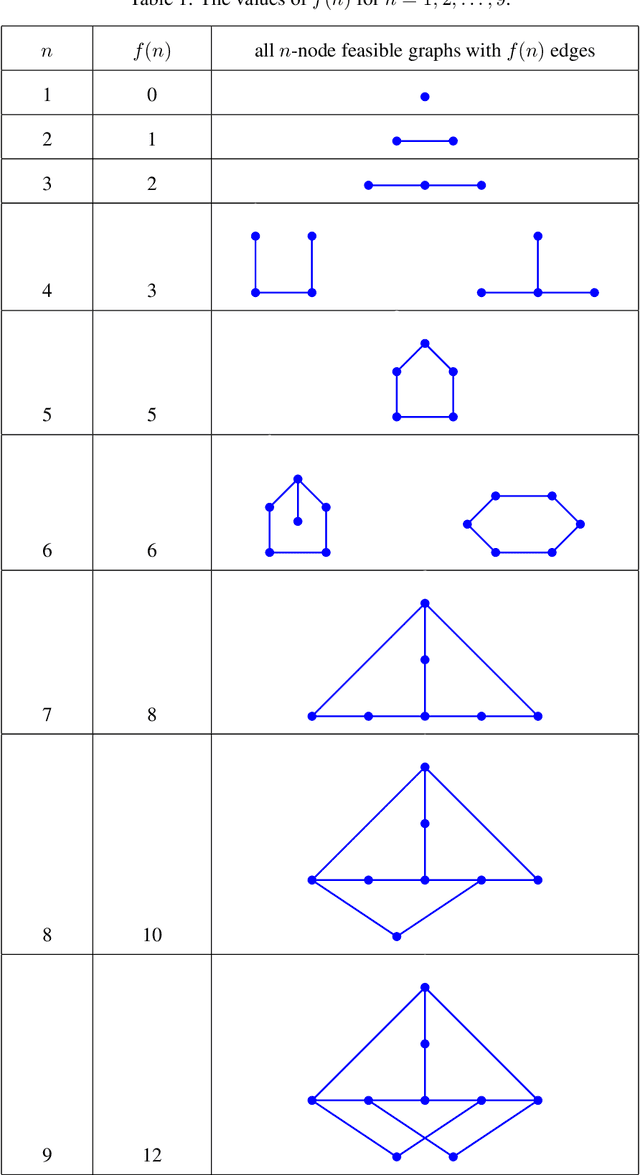
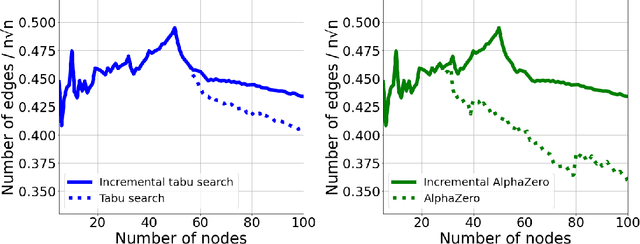

This work studies a central extremal graph theory problem inspired by a 1975 conjecture of Erd\H{o}s, which aims to find graphs with a given size (number of nodes) that maximize the number of edges without having 3- or 4-cycles. We formulate this problem as a sequential decision-making problem and compare AlphaZero, a neural network-guided tree search, with tabu search, a heuristic local search method. Using either method, by introducing a curriculum -- jump-starting the search for larger graphs using good graphs found at smaller sizes -- we improve the state-of-the-art lower bounds for several sizes. We also propose a flexible graph-generation environment and a permutation-invariant network architecture for learning to search in the space of graphs.
Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs
Jul 22, 2021
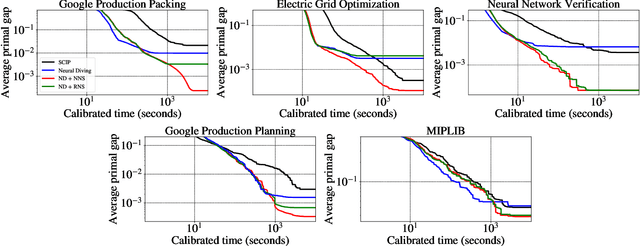
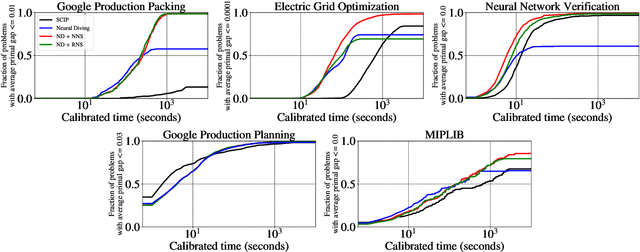
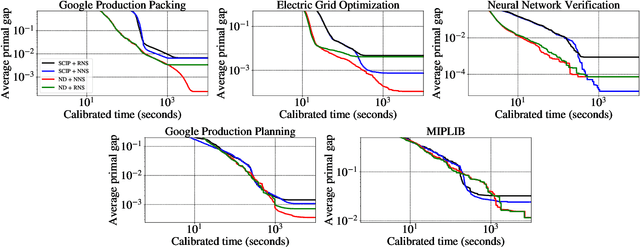
Large Neighborhood Search (LNS) is a combinatorial optimization heuristic that starts with an assignment of values for the variables to be optimized, and iteratively improves it by searching a large neighborhood around the current assignment. In this paper we consider a learning-based LNS approach for mixed integer programs (MIPs). We train a Neural Diving model to represent a probability distribution over assignments, which, together with an off-the-shelf MIP solver, generates an initial assignment. Formulating the subsequent search steps as a Markov Decision Process, we train a Neural Neighborhood Selection policy to select a search neighborhood at each step, which is searched using a MIP solver to find the next assignment. The policy network is trained using imitation learning. We propose a target policy for imitation that, given enough compute resources, is guaranteed to select the neighborhood containing the optimal next assignment amongst all possible choices for the neighborhood of a specified size. Our approach matches or outperforms all the baselines on five real-world MIP datasets with large-scale instances from diverse applications, including two production applications at Google. It achieves $2\times$ to $37.8\times$ better average primal gap than the best baseline on three of the datasets at large running times.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020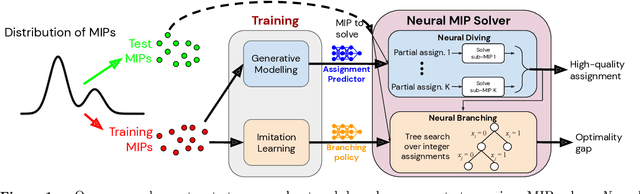
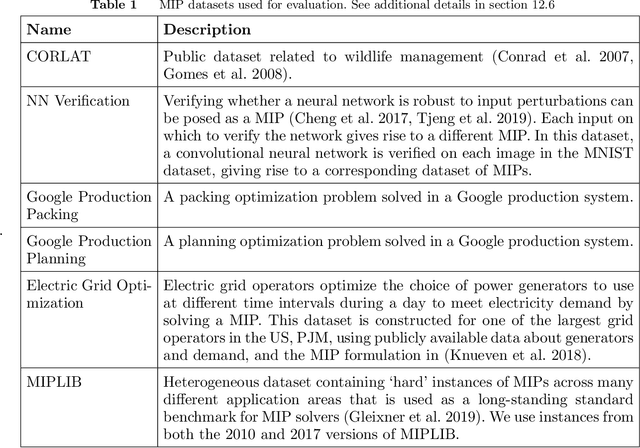
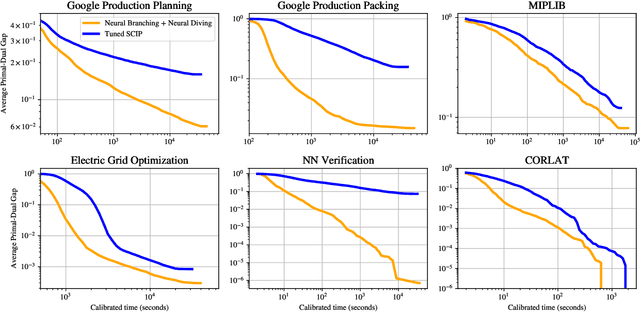
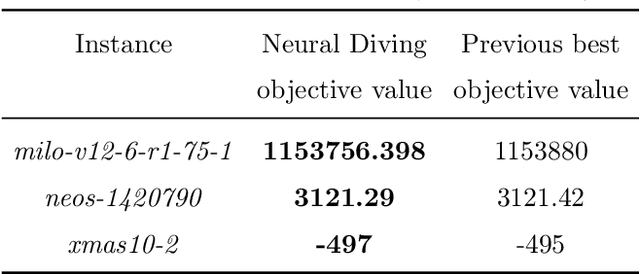
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.
Deep Reinforcement Learning and the Deadly Triad
Dec 06, 2018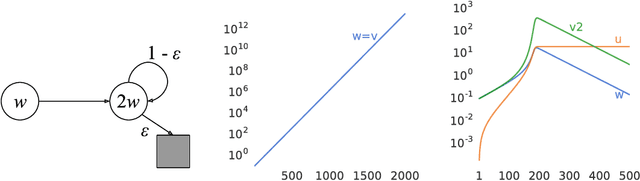
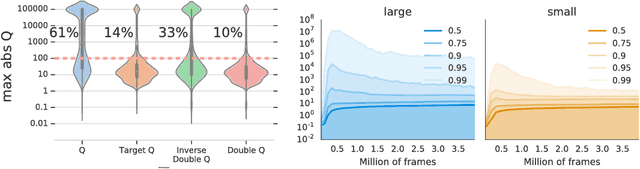
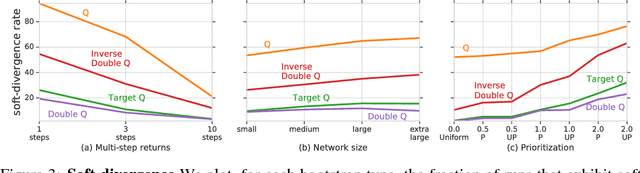
We know from reinforcement learning theory that temporal difference learning can fail in certain cases. Sutton and Barto (2018) identify a deadly triad of function approximation, bootstrapping, and off-policy learning. When these three properties are combined, learning can diverge with the value estimates becoming unbounded. However, several algorithms successfully combine these three properties, which indicates that there is at least a partial gap in our understanding. In this work, we investigate the impact of the deadly triad in practice, in the context of a family of popular deep reinforcement learning models - deep Q-networks trained with experience replay - analysing how the components of this system play a role in the emergence of the deadly triad, and in the agent's performance
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
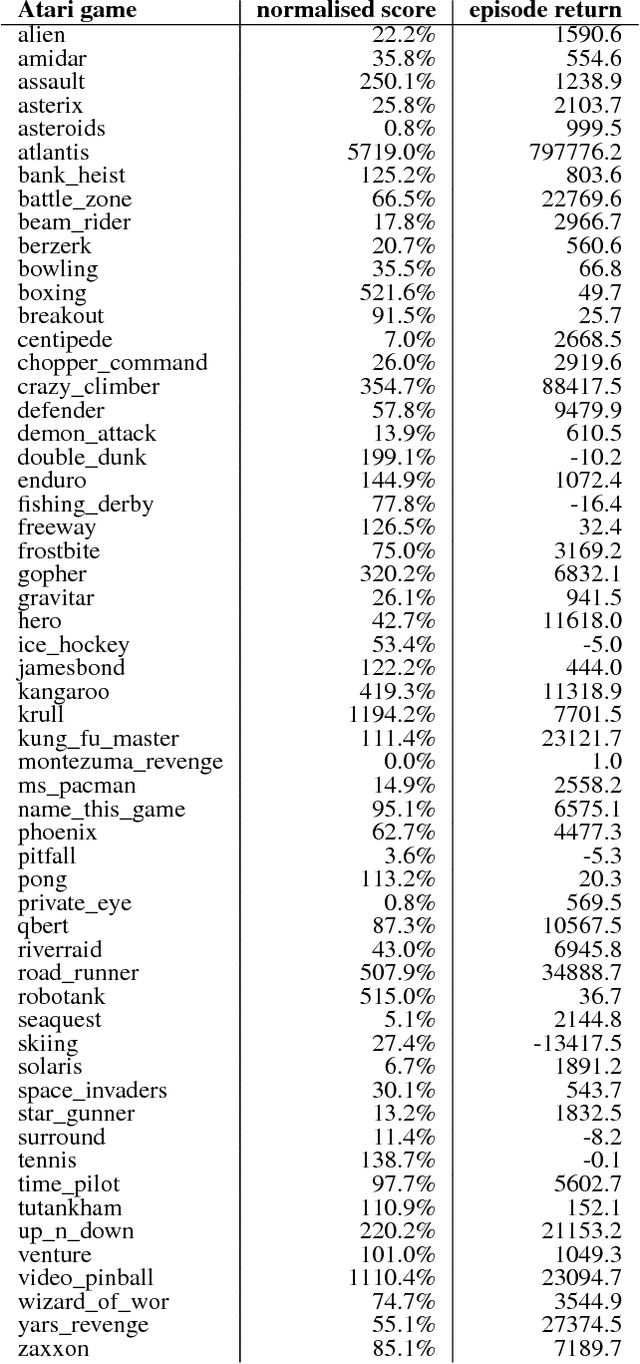
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
SCAN: Learning Hierarchical Compositional Visual Concepts
Jun 06, 2018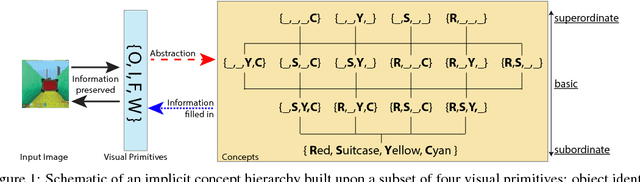
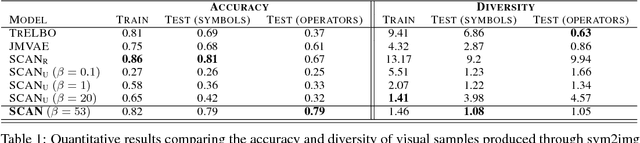
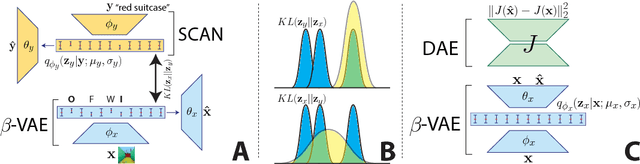
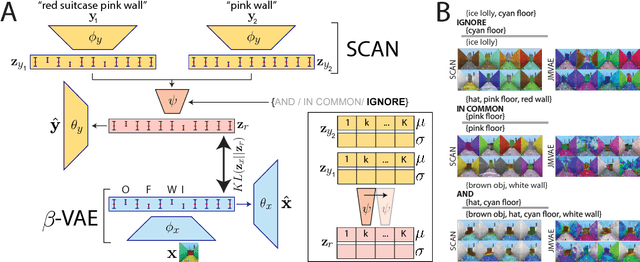
The seemingly infinite diversity of the natural world arises from a relatively small set of coherent rules, such as the laws of physics or chemistry. We conjecture that these rules give rise to regularities that can be discovered through primarily unsupervised experiences and represented as abstract concepts. If such representations are compositional and hierarchical, they can be recombined into an exponentially large set of new concepts. This paper describes SCAN (Symbol-Concept Association Network), a new framework for learning such abstractions in the visual domain. SCAN learns concepts through fast symbol association, grounding them in disentangled visual primitives that are discovered in an unsupervised manner. Unlike state of the art multimodal generative model baselines, our approach requires very few pairings between symbols and images and makes no assumptions about the form of symbol representations. Once trained, SCAN is capable of multimodal bi-directional inference, generating a diverse set of image samples from symbolic descriptions and vice versa. It also allows for traversal and manipulation of the implicit hierarchy of visual concepts through symbolic instructions and learnt logical recombination operations. Such manipulations enable SCAN to break away from its training data distribution and imagine novel visual concepts through symbolically instructed recombination of previously learnt concepts.
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Jun 16, 2017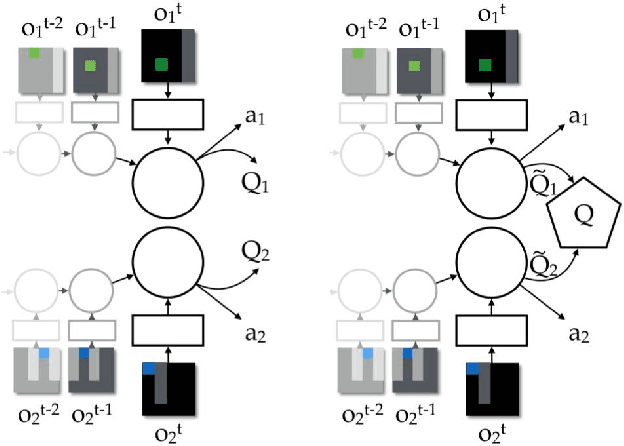
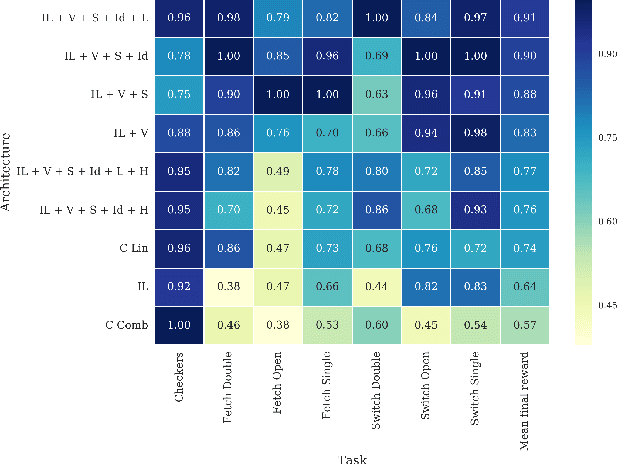
We study the problem of cooperative multi-agent reinforcement learning with a single joint reward signal. This class of learning problems is difficult because of the often large combined action and observation spaces. In the fully centralized and decentralized approaches, we find the problem of spurious rewards and a phenomenon we call the "lazy agent" problem, which arises due to partial observability. We address these problems by training individual agents with a novel value decomposition network architecture, which learns to decompose the team value function into agent-wise value functions. We perform an experimental evaluation across a range of partially-observable multi-agent domains and show that learning such value-decompositions leads to superior results, in particular when combined with weight sharing, role information and information channels.