 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Adaptive Explainer for Faithful Dictionary-Based Interpretability under Distribution Shift
May 21, 2026Mechanistic interpretability aims to explain a model's behavior by identifying causally responsible internal structures. Dictionary-based explainers such as sparse autoencoders and transcoders are a primary tool, but their faithfulness under out-of-distribution (OOD) shift has received little systematic attention. We show that distribution shift rotates the subspace that the model actively uses, misaligning the explainer's dictionary trained on in-distribution (ID) activations. We formalize this misalignment as the faithfulness gap, a geometric distance between the ID dictionary and the OOD-active subspace, and show that it controls OOD faithfulness degradation. To reduce this gap, we propose the Geometry-Adaptive Explainer (GAE), which realigns the explainer's dictionary with the OOD-active subspace while preserving the original feature structure. This requires only unlabeled OOD activations and no gradient updates. We prove that GAE improves over the unadapted ID explainer, with excess loss bounded quadratically by the second-moment shift. Empirically, GAE even matches or surpasses all training-based baselines in causal faithfulness across multiple models and OOD settings.
Tensor Product Representation Probes Reveal Shared Structure Across Linear Directions
May 11, 2026While researchers are finding concepts represented as linear directions in language models, a bag of linear directions fails to capture relational structure. To better understand this dichotomy, we study a model with known linear representations, but trained in a highly structured domain -- the board game Othello. While the model's internal board-state representation is linearly decodable, we find additional structure in the form of tensor product representations (TPRs). We train TPR probes to recover shared structure amongst the linear probes, yielding a factorization into square-embeddings, color-embeddings, and a binding matrix that composes them to construct the model's board-state representation. We find geometric signatures within the weights of our TPR probe that align with the structure of the board, but perhaps more importantly, that the linear probes can be recovered directly from the parameters of our TPR probe. Our findings suggest that directional representations may be projections of more structured underlying representations.
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control
Apr 03, 2026We present a method to identify a valence-arousal (VA) subspace within large language model representations. From 211k emotion-labeled texts, we derive emotion steering vectors, then learn VA axes as linear combinations of their top PCA components via ridge regression on the model's self-reported valence-arousal scores. The resulting VA subspace exhibits circular geometry consistent with established models of human emotion perception. Projections along our recovered VA subspace correlate with human-crowdsourced VA ratings across 44k lexical items. Furthermore, steering generation along these axes produces monotonic shifts in the corresponding affective dimensions of model outputs. Steering along these directions also induces near-monotonic bidirectional control over refusal and sycophancy: increasing arousal decreases refusal and increases sycophancy, and vice versa. These effects replicate across Llama-3.1-8B, Qwen3-8B, and Qwen3-14B, demonstrating cross-architecture generality. We provide a mechanistic account for these effects and prior emotionally-framed controls: refusal-associated tokens ("I can't," "sorry") occupy low-arousal, negative-valence regions, so VA steering directly modulates their emission probability.
Decomposing Query-Key Feature Interactions Using Contrastive Covariances
Feb 04, 2026Despite the central role of attention heads in Transformers, we lack tools to understand why a model attends to a particular token. To address this, we study the query-key (QK) space -- the bilinear joint embedding space between queries and keys. We present a contrastive covariance method to decompose the QK space into low-rank, human-interpretable components. It is when features in keys and queries align in these low-rank subspaces that high attention scores are produced. We first study our method both analytically and empirically in a simplified setting. We then apply our method to large language models to identify human-interpretable QK subspaces for categorical semantic features and binding features. Finally, we demonstrate how attention scores can be attributed to our identified features.
From Isolation to Entanglement: When Do Interpretability Methods Identify and Disentangle Known Concepts?
Dec 17, 2025A central goal of interpretability is to recover representations of causally relevant concepts from the activations of neural networks. The quality of these concept representations is typically evaluated in isolation, and under implicit independence assumptions that may not hold in practice. Thus, it is unclear whether common featurization methods - including sparse autoencoders (SAEs) and sparse probes - recover disentangled representations of these concepts. This study proposes a multi-concept evaluation setting where we control the correlations between textual concepts, such as sentiment, domain, and tense, and analyze performance under increasing correlations between them. We first evaluate the extent to which featurizers can learn disentangled representations of each concept under increasing correlational strengths. We observe a one-to-many relationship from concepts to features: features correspond to no more than one concept, but concepts are distributed across many features. Then, we perform steering experiments, measuring whether each concept is independently manipulable. Even when trained on uniform distributions of concepts, SAE features generally affect many concepts when steered, indicating that they are neither selective nor independent; nonetheless, features affect disjoint subspaces. These results suggest that correlational metrics for measuring disentanglement are generally not sufficient for establishing independence when steering, and that affecting disjoint subspaces is not sufficient for concept selectivity. These results underscore the importance of compositional evaluations in interpretability research.
VITA: Vision-to-Action Flow Matching Policy
Jul 17, 2025We present VITA, a Vision-To-Action flow matching policy that evolves latent visual representations into latent actions for visuomotor control. Traditional flow matching and diffusion policies sample from standard source distributions (e.g., Gaussian noise) and require additional conditioning mechanisms like cross-attention to condition action generation on visual information, creating time and space overheads. VITA proposes a novel paradigm that treats latent images as the flow source, learning an inherent mapping from vision to action while eliminating separate conditioning modules and preserving generative modeling capabilities. Learning flows between fundamentally different modalities like vision and action is challenging due to sparse action data lacking semantic structures and dimensional mismatches between high-dimensional visual representations and raw actions. We address this by creating a structured action latent space via an autoencoder as the flow matching target, up-sampling raw actions to match visual representation shapes. Crucially, we supervise flow matching with both encoder targets and final action outputs through flow latent decoding, which backpropagates action reconstruction loss through sequential flow matching ODE solving steps for effective end-to-end learning. Implemented as simple MLP layers, VITA is evaluated on challenging bi-manual manipulation tasks on the ALOHA platform, including 5 simulation and 2 real-world tasks. Despite its simplicity, MLP-only VITA outperforms or matches state-of-the-art generative policies while reducing inference latency by 50-130% compared to conventional flow matching policies requiring different conditioning mechanisms or complex architectures. To our knowledge, VITA is the first MLP-only flow matching policy capable of solving complex bi-manual manipulation tasks like those in ALOHA benchmarks.
Automating Infrastructure Surveying: A Framework for Geometric Measurements and Compliance Assessment Using Point Cloud Data
May 09, 2025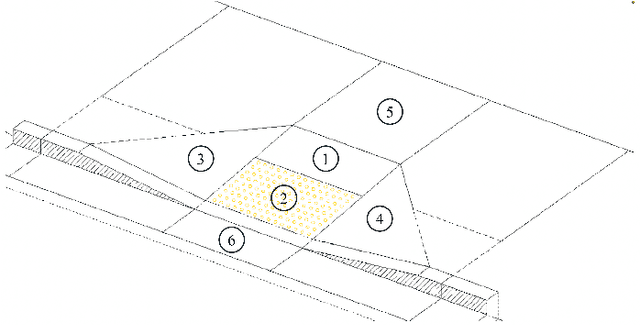
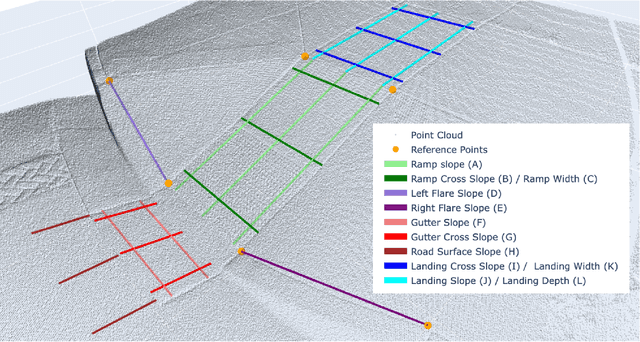
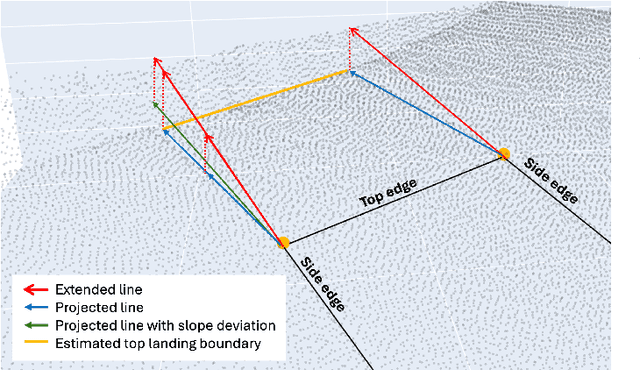
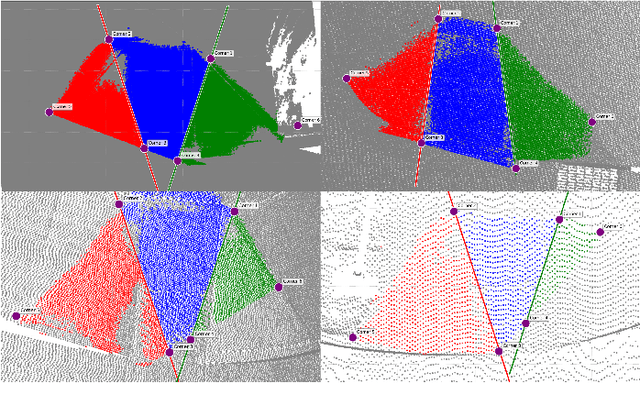
Automation can play a prominent role in improving efficiency, accuracy, and scalability in infrastructure surveying and assessing construction and compliance standards. This paper presents a framework for automation of geometric measurements and compliance assessment using point cloud data. The proposed approach integrates deep learning-based detection and segmentation, in conjunction with geometric and signal processing techniques, to automate surveying tasks. As a proof of concept, we apply this framework to automatically evaluate the compliance of curb ramps with the Americans with Disabilities Act (ADA), demonstrating the utility of point cloud data in survey automation. The method leverages a newly collected, large annotated dataset of curb ramps, made publicly available as part of this work, to facilitate robust model training and evaluation. Experimental results, including comparison with manual field measurements of several ramps, validate the accuracy and reliability of the proposed method, highlighting its potential to significantly reduce manual effort and improve consistency in infrastructure assessment. Beyond ADA compliance, the proposed framework lays the groundwork for broader applications in infrastructure surveying and automated construction evaluation, promoting wider adoption of point cloud data in these domains. The annotated database, manual ramp survey data, and developed algorithms are publicly available on the project's GitHub page: https://github.com/Soltanilara/SurveyAutomation.
The Geometry of Self-Verification in a Task-Specific Reasoning Model
Apr 19, 2025

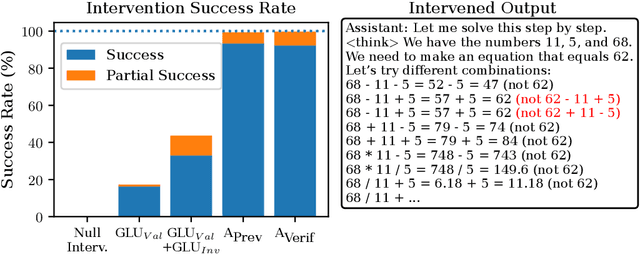

How do reasoning models verify their own answers? We study this question by training a model using DeepSeek R1's recipe on the CountDown task. We leverage the fact that preference tuning leads to mode collapse, resulting in a model that always produces highly structured and easily parse-able chain-of-thought sequences. With this setup, we do a top-down and bottom-up analysis to reverse-engineer how the model verifies its outputs. Our top-down analysis reveals Gated Linear Unit (GLU) weights encoding verification-related tokens, such as ``success'' or ``incorrect'', which activate according to the correctness of the model's reasoning steps. Our bottom-up analysis reveals that ``previous-token heads'' are mainly responsible for model verification. Our analyses meet in the middle: drawing inspiration from inter-layer communication channels, we use the identified GLU vectors to localize as few as three attention heads that can disable model verification, pointing to a necessary component of a potentially larger verification circuit.
Infrared Vision Systems for Emergency Vehicle Driver Assistance in Low-Visibility Conditions
Apr 18, 2025



This study investigates the potential of infrared (IR) camera technology to enhance driver safety for emergency vehicles operating in low-visibility conditions, particularly at night and in dense fog. Such environments significantly increase the risk of collisions, especially for tow trucks and snowplows that must remain operational in challenging conditions. Conventional driver assistance systems often struggle under these conditions due to limited visibility. In contrast, IR cameras, which detect the thermal signatures of obstacles, offer a promising alternative. The evaluation combines controlled laboratory experiments, real-world field tests, and surveys of emergency vehicle operators. In addition to assessing detection performance, the study examines the feasibility of retrofitting existing Department of Transportation (DoT) fleets with cost-effective IR-based driver assistance systems. Results underscore the utility of IR technology in enhancing driver awareness and provide data-driven recommendations for scalable deployment across legacy emergency vehicle fleets.
Shared Global and Local Geometry of Language Model Embeddings
Mar 27, 2025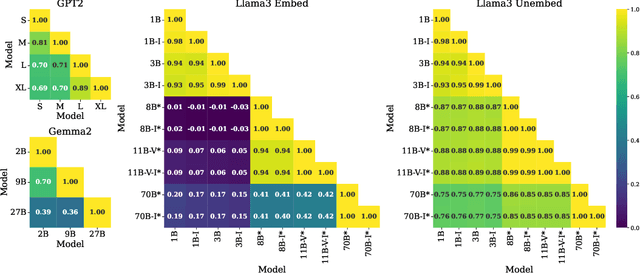

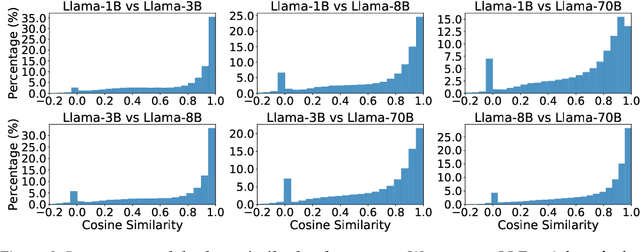

Researchers have recently suggested that models share common representations. In this work, we find that the token embeddings of language models exhibit common geometric structure. First, we find ``global'' similarities: token embeddings often share similar relative orientations. Next, we characterize local geometry in two ways: (1) by using Locally Linear Embeddings, and (2) by defining a simple measure for the intrinsic dimension of each token embedding. Our intrinsic dimension measure demonstrates that token embeddings lie on a lower dimensional manifold. We qualitatively show that tokens with lower intrinsic dimensions often have semantically coherent clusters, while those with higher intrinsic dimensions do not. Both characterizations allow us to find similarities in the local geometry of token embeddings. Perhaps most surprisingly, we find that alignment in token embeddings persists through the hidden states of language models, allowing us to develop an application for interpretability. Namely, we empirically demonstrate that steering vectors from one language model can be transferred to another, despite the two models having different dimensions.