 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Product Representation Probes Reveal Shared Structure Across Linear Directions
May 11, 2026While researchers are finding concepts represented as linear directions in language models, a bag of linear directions fails to capture relational structure. To better understand this dichotomy, we study a model with known linear representations, but trained in a highly structured domain -- the board game Othello. While the model's internal board-state representation is linearly decodable, we find additional structure in the form of tensor product representations (TPRs). We train TPR probes to recover shared structure amongst the linear probes, yielding a factorization into square-embeddings, color-embeddings, and a binding matrix that composes them to construct the model's board-state representation. We find geometric signatures within the weights of our TPR probe that align with the structure of the board, but perhaps more importantly, that the linear probes can be recovered directly from the parameters of our TPR probe. Our findings suggest that directional representations may be projections of more structured underlying representations.
AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
May 07, 2026We introduce the AI co-mathematician, a workbench for mathematicians to interactively leverage AI agents to pursue open-ended research. The AI co-mathematician is optimized to provide holistic support for the exploratory and iterative reality of mathematical workflows, including ideation, literature search, computational exploration, theorem proving and theory building. By providing an asynchronous, stateful workspace that manages uncertainty, refines user intent, tracks failed hypotheses, and outputs native mathematical artifacts, the system mirrors human collaborative workflows. In early tests, the AI co-mathematician helped researchers solve open problems, identify new research directions, and uncover overlooked literature references. Besides demonstrating a highly interactive paradigm for AI-assisted mathematical discovery, the AI co-mathematician also achieves state of the art results on hard problem-solving benchmarks, including scoring 48% on FrontierMath Tier 4, a new high score among all AI systems evaluated.
Intentmaking and Sensemaking: Human Interaction with AI-Guided Mathematical Discovery
May 07, 2026Artificial intelligence offers powerful new tools for scientific discovery, but the interaction paradigms required to effectively harness these systems remain underexplored. In this paper, we present findings from a formative user study with 11 expert mathematicians who used AlphaEvolve, an evolutionary coding agent, to tackle advanced problems in their fields of expertise. We identify and characterize a distinct workflow we term intentmaking, the iterative process of discovering, defining, and refining one's experimental goals through active system interaction. We frame this as a natural extension to sensemaking, the cognitive process of building an understanding of complex or novel data. We suggest that users enter a cycle of intentmaking (defining and updating their experiment) and sensemaking (interpreting the results) which repeats many times during the course of an investigation. Our documentation of these themes suggests an approach to designing AI tools for scientific discovery that goes beyond the existing question/answer model of many current systems, treating them as collaborative instruments rather than opaque black-box assistants.
Large Language Models Generate Harmful Content Using a Distinct, Unified Mechanism
Apr 10, 2026Large language models (LLMs) undergo alignment training to avoid harmful behaviors, yet the resulting safeguards remain brittle: jailbreaks routinely bypass them, and fine-tuning on narrow domains can induce ``emergent misalignment'' that generalizes broadly. Whether this brittleness reflects a fundamental lack of coherent internal organization for harmfulness remains unclear. Here we use targeted weight pruning as a causal intervention to probe the internal organization of harmfulness in LLMs. We find that harmful content generation depends on a compact set of weights that are general across harm types and distinct from benign capabilities. Aligned models exhibit a greater compression of harm generation weights than unaligned counterparts, indicating that alignment reshapes harmful representations internally--despite the brittleness of safety guardrails at the surface level. This compression explains emergent misalignment: if weights of harmful capabilities are compressed, fine-tuning that engages these weights in one domain can trigger broad misalignment. Consistent with this, pruning harm generation weights in a narrow domain substantially reduces emergent misalignment. Notably, LLMs harmful generation capability is dissociated from how they recognize and explain such content. Together, these results reveal a coherent internal structure for harmfulness in LLMs that may serve as a foundation for more principled approaches to safety.
Think Before You Lie: How Reasoning Leads to Honesty
Mar 16, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Think Before You Lie: How Reasoning Improves Honesty
Mar 10, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Decomposing Query-Key Feature Interactions Using Contrastive Covariances
Feb 04, 2026Despite the central role of attention heads in Transformers, we lack tools to understand why a model attends to a particular token. To address this, we study the query-key (QK) space -- the bilinear joint embedding space between queries and keys. We present a contrastive covariance method to decompose the QK space into low-rank, human-interpretable components. It is when features in keys and queries align in these low-rank subspaces that high attention scores are produced. We first study our method both analytically and empirically in a simplified setting. We then apply our method to large language models to identify human-interpretable QK subspaces for categorical semantic features and binding features. Finally, we demonstrate how attention scores can be attributed to our identified features.
Does visualization help AI understand data?
Jul 24, 2025

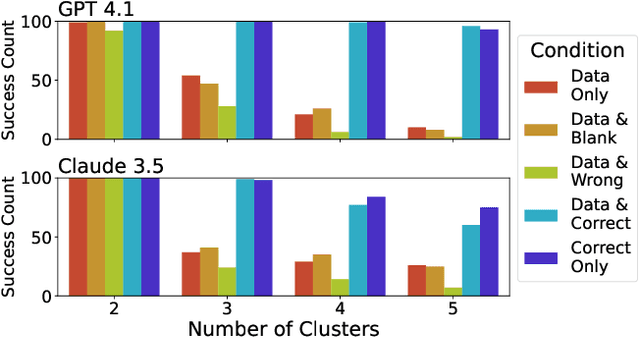

Charts and graphs help people analyze data, but can they also be useful to AI systems? To investigate this question, we perform a series of experiments with two commercial vision-language models: GPT 4.1 and Claude 3.5. Across three representative analysis tasks, the two systems describe synthetic datasets more precisely and accurately when raw data is accompanied by a scatterplot, especially as datasets grow in complexity. Comparison with two baselines -- providing a blank chart and a chart with mismatched data -- shows that the improved performance is due to the content of the charts. Our results are initial evidence that AI systems, like humans, can benefit from visualization.
Can Interpretation Predict Behavior on Unseen Data?
Jul 08, 2025Interpretability research often aims to predict how a model will respond to targeted interventions on specific mechanisms. However, it rarely predicts how a model will respond to unseen input data. This paper explores the promises and challenges of interpretability as a tool for predicting out-of-distribution (OOD) model behavior. Specifically, we investigate the correspondence between attention patterns and OOD generalization in hundreds of Transformer models independently trained on a synthetic classification task. These models exhibit several distinct systematic generalization rules OOD, forming a diverse population for correlational analysis. In this setting, we find that simple observational tools from interpretability can predict OOD performance. In particular, when in-distribution attention exhibits hierarchical patterns, the model is likely to generalize hierarchically on OOD data -- even when the rule's implementation does not rely on these hierarchical patterns, according to ablation tests. Our findings offer a proof-of-concept to motivate further interpretability work on predicting unseen model behavior.
When Bad Data Leads to Good Models
May 07, 2025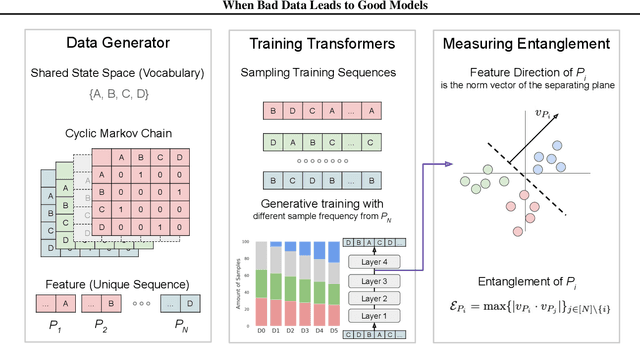
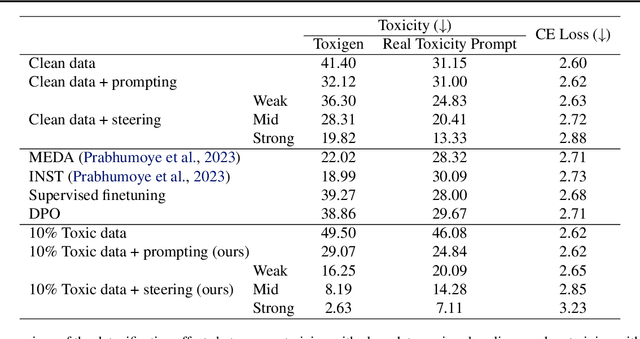
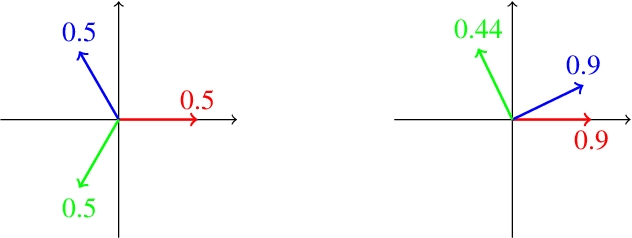
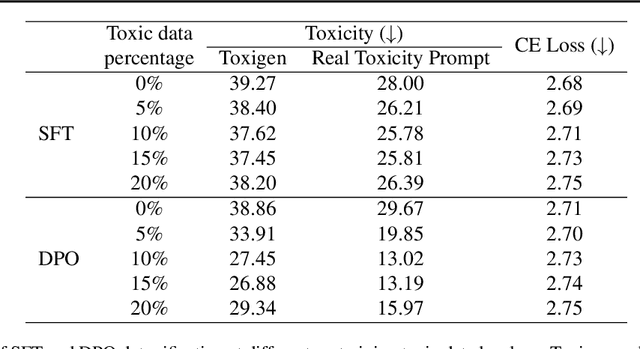
In large language model (LLM) pretraining, data quality is believed to determine model quality. In this paper, we re-examine the notion of "quality" from the perspective of pre- and post-training co-design. Specifically, we explore the possibility that pre-training on more toxic data can lead to better control in post-training, ultimately decreasing a model's output toxicity. First, we use a toy experiment to study how data composition affects the geometry of features in the representation space. Next, through controlled experiments with Olmo-1B models trained on varying ratios of clean and toxic data, we find that the concept of toxicity enjoys a less entangled linear representation as the proportion of toxic data increases. Furthermore, we show that although toxic data increases the generational toxicity of the base model, it also makes the toxicity easier to remove. Evaluations on Toxigen and Real Toxicity Prompts demonstrate that models trained on toxic data achieve a better trade-off between reducing generational toxicity and preserving general capabilities when detoxifying techniques such as inference-time intervention (ITI) are applied. Our findings suggest that, with post-training taken into account, bad data may lead to good models.