 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Bad Data Leads to Good Models
May 07, 2025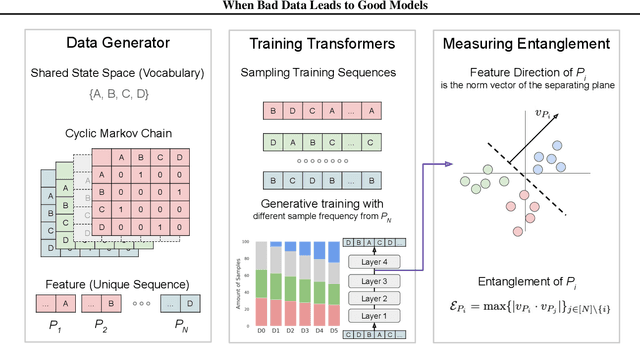
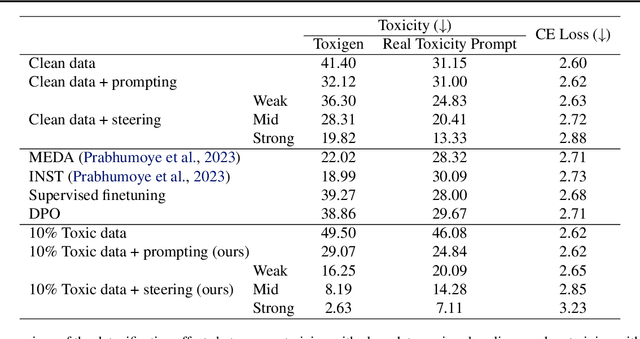
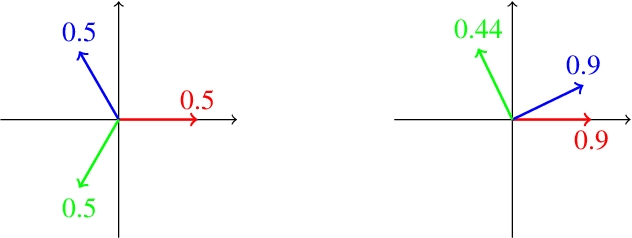
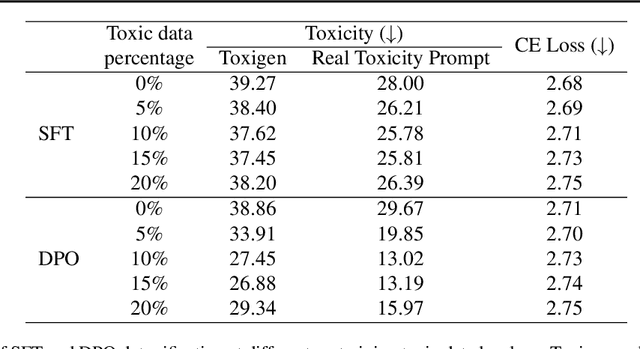
In large language model (LLM) pretraining, data quality is believed to determine model quality. In this paper, we re-examine the notion of "quality" from the perspective of pre- and post-training co-design. Specifically, we explore the possibility that pre-training on more toxic data can lead to better control in post-training, ultimately decreasing a model's output toxicity. First, we use a toy experiment to study how data composition affects the geometry of features in the representation space. Next, through controlled experiments with Olmo-1B models trained on varying ratios of clean and toxic data, we find that the concept of toxicity enjoys a less entangled linear representation as the proportion of toxic data increases. Furthermore, we show that although toxic data increases the generational toxicity of the base model, it also makes the toxicity easier to remove. Evaluations on Toxigen and Real Toxicity Prompts demonstrate that models trained on toxic data achieve a better trade-off between reducing generational toxicity and preserving general capabilities when detoxifying techniques such as inference-time intervention (ITI) are applied. Our findings suggest that, with post-training taken into account, bad data may lead to good models.
ChatGPT Doesn't Trust Chargers Fans: Guardrail Sensitivity in Context
Jul 10, 2024While the biases of language models in production are extensively documented, the biases of their guardrails have been neglected. This paper studies how contextual information about the user influences the likelihood of an LLM to refuse to execute a request. By generating user biographies that offer ideological and demographic information, we find a number of biases in guardrail sensitivity on GPT-3.5. Younger, female, and Asian-American personas are more likely to trigger a refusal guardrail when requesting censored or illegal information. Guardrails are also sycophantic, refusing to comply with requests for a political position the user is likely to disagree with. We find that certain identity groups and seemingly innocuous information, e.g., sports fandom, can elicit changes in guardrail sensitivity similar to direct statements of political ideology. For each demographic category and even for American football team fandom, we find that ChatGPT appears to infer a likely political ideology and modify guardrail behavior accordingly.
Designing a Dashboard for Transparency and Control of Conversational AI
Jun 12, 2024



Conversational LLMs function as black box systems, leaving users guessing about why they see the output they do. This lack of transparency is potentially problematic, especially given concerns around bias and truthfulness. To address this issue, we present an end-to-end prototype-connecting interpretability techniques with user experience design-that seeks to make chatbots more transparent. We begin by showing evidence that a prominent open-source LLM has a "user model": examining the internal state of the system, we can extract data related to a user's age, gender, educational level, and socioeconomic status. Next, we describe the design of a dashboard that accompanies the chatbot interface, displaying this user model in real time. The dashboard can also be used to control the user model and the system's behavior. Finally, we discuss a study in which users conversed with the instrumented system. Our results suggest that users appreciate seeing internal states, which helped them expose biased behavior and increased their sense of control. Participants also made valuable suggestions that point to future directions for both design and machine learning research. The project page and video demo of our TalkTuner system are available at https://bit.ly/talktuner-project-page
More than Correlation: Do Large Language Models Learn Causal Representations of Space?
Dec 26, 2023Recent work found high mutual information between the learned representations of large language models (LLMs) and the geospatial property of its input, hinting an emergent internal model of space. However, whether this internal space model has any causal effects on the LLMs' behaviors was not answered by that work, led to criticism of these findings as mere statistical correlation. Our study focused on uncovering the causality of the spatial representations in LLMs. In particular, we discovered the potential spatial representations in DeBERTa, GPT-Neo using representational similarity analysis and linear and non-linear probing. Our casual intervention experiments showed that the spatial representations influenced the model's performance on next word prediction and a downstream task that relies on geospatial information. Our experiments suggested that the LLMs learn and use an internal model of space in solving geospatial related tasks.
Soil Image Segmentation Based on Mask R-CNN
Sep 02, 2023The complex background in the soil image collected in the field natural environment will affect the subsequent soil image recognition based on machine vision. Segmenting the soil center area from the soil image can eliminate the influence of the complex background, which is an important preprocessing work for subsequent soil image recognition. For the first time, the deep learning method was applied to soil image segmentation, and the Mask R-CNN model was selected to complete the positioning and segmentation of soil images. Construct a soil image dataset based on the collected soil images, use the EISeg annotation tool to mark the soil area as soil, and save the annotation information; train the Mask R-CNN soil image instance segmentation model. The trained model can obtain accurate segmentation results for soil images, and can show good performance on soil images collected in different environments; the trained instance segmentation model has a loss value of 0.1999 in the training set, and the mAP of the validation set segmentation (IoU=0.5) is 0.8804, and it takes only 0.06s to complete image segmentation based on GPU acceleration, which can meet the real-time segmentation and detection of soil images in the field under natural conditions. You can get our code in the Conclusions. The homepage is https://github.com/YidaMyth.
* 4 pages, 5 figures, Published in 2023 3rd International Conference on Consumer Electronics and Computer Engineering
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
Jun 09, 2023



Latent diffusion models (LDMs) exhibit an impressive ability to produce realistic images, yet the inner workings of these models remain mysterious. Even when trained purely on images without explicit depth information, they typically output coherent pictures of 3D scenes. In this work, we investigate a basic interpretability question: does an LDM create and use an internal representation of simple scene geometry? Using linear probes, we find evidence that the internal activations of the LDM encode linear representations of both 3D depth data and a salient-object / background distinction. These representations appear surprisingly early in the denoising process$-$well before a human can easily make sense of the noisy images. Intervention experiments further indicate these representations play a causal role in image synthesis, and may be used for simple high-level editing of an LDM's output.
AttentionViz: A Global View of Transformer Attention
May 04, 2023



Transformer models are revolutionizing machine learning, but their inner workings remain mysterious. In this work, we present a new visualization technique designed to help researchers understand the self-attention mechanism in transformers that allows these models to learn rich, contextual relationships between elements of a sequence. The main idea behind our method is to visualize a joint embedding of the query and key vectors used by transformer models to compute attention. Unlike previous attention visualization techniques, our approach enables the analysis of global patterns across multiple input sequences. We create an interactive visualization tool, AttentionViz, based on these joint query-key embeddings, and use it to study attention mechanisms in both language and vision transformers. We demonstrate the utility of our approach in improving model understanding and offering new insights about query-key interactions through several application scenarios and expert feedback.
Robust Total Least Mean M-Estimate normalized subband filter Adaptive Algorithm for impulse noises and noisy inputs
Nov 07, 2022



When the input signal is correlated input signals, and the input and output signal is contaminated by Gaussian noise, the total least squares normalized subband adaptive filter (TLS-NSAF) algorithm shows good performance. However, when it is disturbed by impulse noise, the TLS-NSAF algorithm shows the rapidly deteriorating convergence performance. To solve this problem, this paper proposed the robust total minimum mean M-estimator normalized subband filter (TLMM-NSAF) algorithm. In addition, this paper also conducts a detailed theoretical performance analysis of the TLMM-NSAF algorithm and obtains the stable step size range and theoretical steady-state mean squared deviation (MSD) of the algorithm. To further improve the performance of the algorithm, we also propose a new variable step size (VSS) method of the algorithm. Finally, the robustness of our proposed algorithm and the consistency of theoretical and simulated values are verified by computer simulations of system identification and echo cancellation under different noise models.