 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop Multi-Agent Ventilator Decision Support with Contextual Bandit Preference Learning
May 22, 2026Ventilator decision support requires sequential decisions that track evolving physiology and disease trajectories while respecting safety boundaries and clinician specific tuning styles. Rule based approaches rarely generalize personalization, and end to end reinforcement learning or single large language model systems remain difficult to control and audit. We propose the Ventilator Decision Support System (VDSS), a human in the loop multi agent framework that coordinates modular decision components through contract driven structured interfaces and produces traceable evidence for review. VDSS performs online preference adaptation with a contextual bandit, updating clinician specific preferences from the final accepted decision at each adjustment cycle and using them to guide subsequent recommendations. Structured rejection feedback triggers targeted replanning to reduce unproductive iterations and improve interaction stability. Retrospective ICU trajectory replay with expert review indicates higher recommendation acceptability and fewer interaction rounds to reach an acceptable plan, supporting clinically deployable human AI collaboration.
GEAR: Granularity-Adaptive Advantage Reweighting for LLM Agents via Self-Distillation
May 14, 2026Reinforcement learning has become a widely used post-training approach for LLM agents, where training commonly relies on outcome-level rewards that provide only coarse supervision. While finer-grained credit assignment is promising for effective policy updates, obtaining reliable local credit and assigning it to the right parts of the long-horizon trajectory remains an open challenge. In this paper, we propose Granularity-adaptivE Advantage Reweighting (GEAR), an adaptive-granularity credit assignment framework that reshapes the trajectory-level GRPO advantage using token- and segment-level signals derived from self-distillation. GEAR compares an on-policy student with a ground-truth-conditioned teacher to obtain a reference-guided divergence signal for identifying adaptive segment boundaries and modulating local advantage weights. This divergence often spikes at the onset of a semantic deviation, while later tokens in the same autoregressive continuation may return to low divergence. GEAR therefore treats such spikes as anchors for adaptive credit regions: where the student remains aligned with the teacher, token-level resolution is preserved; where it departs, GEAR groups the corresponding continuation into an adaptive segment and uses the divergence at the departure point to modulate the segment' s advantage. Experiments across eight mathematical reasoning and agentic tool-use benchmarks with Qwen3 4B and 8B models show that GEAR consistently outperforms standard GRPO, self-distillation-only baselines, and token- or turn-level credit-assignment methods. The gains are especially strong on benchmarks with lower GRPO baseline accuracy, reaching up to around 20\% over GRPO, suggesting that the proposed adaptive reweighting scheme is especially useful in more challenging long-horizon settings.
Disagreement as Signals: Dual-view Calibration for Sequential Recommendation Denoising
Apr 27, 2026Sequential recommendation seeks to model the evolution of user interests by capturing temporal user intent and item-level transition patterns. Transformer-based recommenders demonstrate a strong capacity for learning long-range and interpretable dependencies, yet remain vulnerable to behavioral noise that is misaligned with users' true preferences. Recent large language model (LLM)-based approaches attempt to denoise interaction histories through static semantic editing. Such methods neglect the learning dynamics of recommendation models and fail to account for the evolving nature of user interests. To address this limitation, we propose a Dual-view Calibration framework for Sequential Recommendation denoising (DC4SR). Specifically, we introduce a semantic prior, derived from an LLM fine-tuned via labeled historical interactions, to estimate the noise distribution from a semantic perspective. From the learning perspective, we further employ a model-side posterior that infers the noise distribution based on the model's learning dynamics. The disagreement between the two distributions is then leveraged to jointly refine semantic understanding and learning-aware model-side representations. Through iterative updates, dynamic dual-view calibration is achieved for both the global semantic prior and the model-side posterior, enabling consistent alignment with evolving user interests. Extensive experiments demonstrate that DC4SR consistently outperforms strong Transformer-based recommenders and LLM-based denoising methods, exhibiting enhanced robustness across training stages and noise conditions.
MIMO OFDM-Enabled ISAC for Low-Altitude Non-Cooperative UAV Surveillance: A Survey
Apr 03, 2026The widespread use of unmanned aerial vehicles (UAVs) in low-altitude airspace has raised significant safety and security concerns, motivating the development of reliable non-cooperative UAV surveillance technologies. Integrated sensing and communication (ISAC), enabled by multiple-input multiple-output (MIMO) architectures and orthogonal frequency-division multiplexing (OFDM) waveforms, has emerged as a promising paradigm for leveraging cellular infrastructure to support large-scale sensing without additional hardware deployment. This paper presents the first comprehensive survey dedicated to MIMO OFDM-enabled ISAC for low-altitude non-cooperative UAV surveillance, where the targeted UAVs do not intentionally assist the monitoring system through dedicated signaling or prior coordinate sharing. We first analyze the unique propagation characteristics of low-altitude UAV sensing, including severe clutter, rapid channel variations, and mixed near/far-field effects, and discuss corresponding waveform design principles. We then systematically review existing MIMO OFDM-enabled UAV surveillance techniques along four key dimensions: ISAC system modeling and network optimization, UAV detection and tracking algorithms under single and networked base station (BS) architectures, UAV identification techniques based on micro-Doppler and learning-based approaches, and experimental validations and practical field trials. Subsequently, we summarize open challenges such as sensing under severe clutter and multipath, data scarcity for identification, cooperative multi-BS fusion, and real-world deployment constraints. Finally, we outline promising future research directions toward 5G-Advanced (5G-A) and 6G-enabled low-altitude surveillance systems.
A General Model for Retinal Segmentation and Quantification
Jan 31, 2026Retinal imaging is fast, non-invasive, and widely available, offering quantifiable structural and vascular signals for ophthalmic and systemic health assessment. This accessibility creates an opportunity to study how quantitative retinal phenotypes relate to ocular and systemic diseases. However, such analyses remain difficult at scale due to the limited availability of public multi-label datasets and the lack of a unified segmentation-to-quantification pipeline. We present RetSAM, a general retinal segmentation and quantification framework for fundus imaging. It delivers robust multi-target segmentation and standardized biomarker extraction, supporting downstream ophthalmologic studies and oculomics correlation analyses. Trained on over 200,000 fundus images, RetSAM supports three task categories and segments five anatomical structures, four retinal phenotypic patterns, and more than 20 distinct lesion types. It converts these segmentation results into over 30 standardized biomarkers that capture structural morphology, vascular geometry, and degenerative changes. Trained with a multi-stage strategy using both private and public fundus data, RetSAM achieves superior segmentation performance on 17 public datasets. It improves on prior best methods by 3.9 percentage points in DSC on average, with up to 15 percentage points on challenging multi-task benchmarks, and generalizes well across diverse populations, imaging devices, and clinical settings. The resulting biomarkers enable systematic correlation analyses across major ophthalmic diseases, including diabetic retinopathy, age-related macular degeneration, glaucoma, and pathologic myopia. Together, RetSAM transforms fundus images into standardized, interpretable quantitative phenotypes, enabling large-scale ophthalmic research and translation.
Curiosity Driven Knowledge Retrieval for Mobile Agents
Jan 27, 2026Mobile agents have made progress toward reliable smartphone automation, yet performance in complex applications remains limited by incomplete knowledge and weak generalization to unseen environments. We introduce a curiosity driven knowledge retrieval framework that formalizes uncertainty during execution as a curiosity score. When this score exceeds a threshold, the system retrieves external information from documentation, code repositories, and historical trajectories. Retrieved content is organized into structured AppCards, which encode functional semantics, parameter conventions, interface mappings, and interaction patterns. During execution, an enhanced agent selectively integrates relevant AppCards into its reasoning process, thereby compensating for knowledge blind spots and improving planning reliability. Evaluation on the AndroidWorld benchmark shows consistent improvements across backbones, with an average gain of six percentage points and a new state of the art success rate of 88.8\% when combined with GPT-5. Analysis indicates that AppCards are particularly effective for multi step and cross application tasks, while improvements depend on the backbone model. Case studies further confirm that AppCards reduce ambiguity, shorten exploration, and support stable execution trajectories. Task trajectories are publicly available at https://lisalsj.github.io/Droidrun-appcard/.
SRU-Pix2Pix: A Fusion-Driven Generator Network for Medical Image Translation with Few-Shot Learning
Jan 08, 2026Magnetic Resonance Imaging (MRI) provides detailed tissue information, but its clinical application is limited by long acquisition time, high cost, and restricted resolution. Image translation has recently gained attention as a strategy to address these limitations. Although Pix2Pix has been widely applied in medical image translation, its potential has not been fully explored. In this study, we propose an enhanced Pix2Pix framework that integrates Squeeze-and-Excitation Residual Networks (SEResNet) and U-Net++ to improve image generation quality and structural fidelity. SEResNet strengthens critical feature representation through channel attention, while U-Net++ enhances multi-scale feature fusion. A simplified PatchGAN discriminator further stabilizes training and refines local anatomical realism. Experimental results demonstrate that under few-shot conditions with fewer than 500 images, the proposed method achieves consistent structural fidelity and superior image quality across multiple intra-modality MRI translation tasks, showing strong generalization ability. These results suggest an effective extension of Pix2Pix for medical image translation.
Shared Representation Learning for High-Dimensional Multi-Task Forecasting under Resource Contention in Cloud-Native Backends
Dec 24, 2025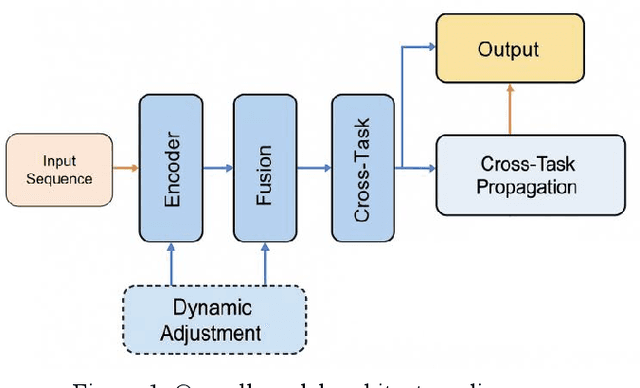
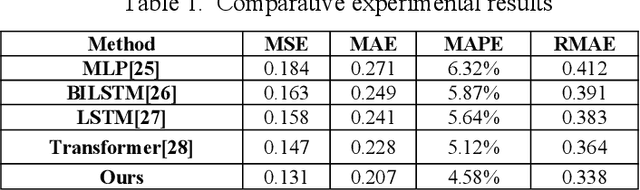
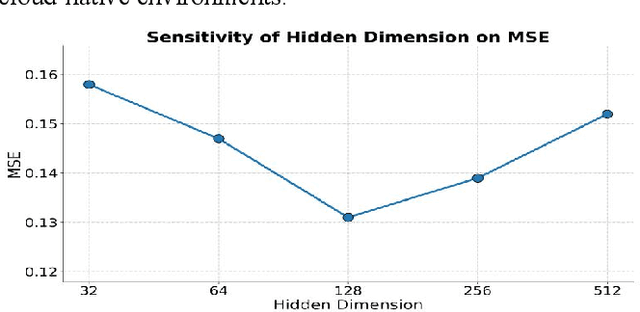
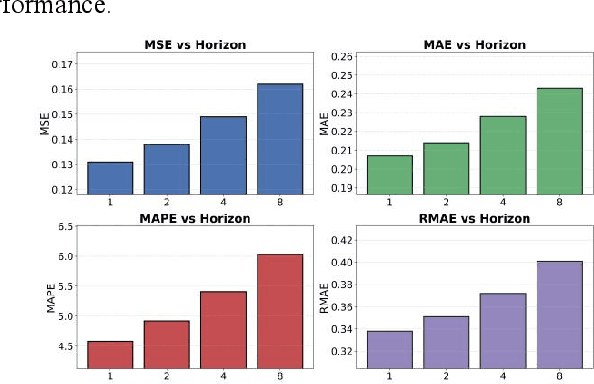
This study proposes a unified forecasting framework for high-dimensional multi-task time series to meet the prediction demands of cloud native backend systems operating under highly dynamic loads, coupled metrics, and parallel tasks. The method builds a shared encoding structure to represent diverse monitoring indicators in a unified manner and employs a state fusion mechanism to capture trend changes and local disturbances across different time scales. A cross-task structural propagation module is introduced to model potential dependencies among nodes, enabling the model to understand complex structural patterns formed by resource contention, link interactions, and changes in service topology. To enhance adaptability to non-stationary behaviors, the framework incorporates a dynamic adjustment mechanism that automatically regulates internal feature flows according to system state changes, ensuring stable predictions in the presence of sudden load shifts, topology drift, and resource jitter. The experimental evaluation compares multiple models across various metrics and verifies the effectiveness of the framework through analyses of hyperparameter sensitivity, environmental sensitivity, and data sensitivity. The results show that the proposed method achieves superior performance on several error metrics and provides more accurate representations of future states under different operating conditions. Overall, the unified forecasting framework offers reliable predictive capability for high-dimensional, multi-task, and strongly dynamic environments in cloud native systems and provides essential technical support for intelligent backend management.
Cost-TrustFL: Cost-Aware Hierarchical Federated Learning with Lightweight Reputation Evaluation across Multi-Cloud
Dec 23, 2025Federated learning across multi-cloud environments faces critical challenges, including non-IID data distributions, malicious participant detection, and substantial cross-cloud communication costs (egress fees). Existing Byzantine-robust methods focus primarily on model accuracy while overlooking the economic implications of data transfer across cloud providers. This paper presents Cost-TrustFL, a hierarchical federated learning framework that jointly optimizes model performance and communication costs while providing robust defense against poisoning attacks. We propose a gradient-based approximate Shapley value computation method that reduces the complexity from exponential to linear, enabling lightweight reputation evaluation. Our cost-aware aggregation strategy prioritizes intra-cloud communication to minimize expensive cross-cloud data transfers. Experiments on CIFAR-10 and FEMNIST datasets demonstrate that Cost-TrustFL achieves 86.7% accuracy under 30% malicious clients while reducing communication costs by 32% compared to baseline methods. The framework maintains stable performance across varying non-IID degrees and attack intensities, making it practical for real-world multi-cloud deployments.
SIT-Graph: State Integrated Tool Graph for Multi-Turn Agents
Dec 08, 2025Despite impressive advances in agent systems, multi-turn tool-use scenarios remain challenging. It is mainly because intent is clarified progressively and the environment evolves with each tool call. While reusing past experience is natural, current LLM agents either treat entire trajectories or pre-defined subtasks as indivisible units, or solely exploit tool-to-tool dependencies, hindering adaptation as states and information evolve across turns. In this paper, we propose a State Integrated Tool Graph (SIT-Graph), which enhances multi-turn tool use by exploiting partially overlapping experience. Inspired by human decision-making that integrates episodic and procedural memory, SIT-Graph captures both compact state representations (episodic-like fragments) and tool-to-tool dependencies (procedural-like routines) from historical trajectories. Specifically, we first build a tool graph from accumulated tool-use sequences, and then augment each edge with a compact state summary of the dialog and tool history that may shape the next action. At inference time, SIT-Graph enables a human-like balance between episodic recall and procedural execution: when the next decision requires recalling prior context, the agent retrieves the state summaries stored on relevant edges and uses them to guide its next action; when the step is routine, it follows high-confidence tool dependencies without explicit recall. Experiments across multiple stateful multi-turn tool-use benchmarks show that SIT-Graph consistently outperforms strong memory- and graph-based baselines, delivering more robust tool selection and more effective experience transfer.