 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Robot Semantic Navigation Through Multimodal Chain-of-Thought Score Collaboration
Dec 24, 2024



Understanding how humans cooperatively utilize semantic knowledge to explore unfamiliar environments and decide on navigation directions is critical for house service multi-robot systems. Previous methods primarily focused on single-robot centralized planning strategies, which severely limited exploration efficiency. Recent research has considered decentralized planning strategies for multiple robots, assigning separate planning models to each robot, but these approaches often overlook communication costs. In this work, we propose Multimodal Chain-of-Thought Co-Navigation (MCoCoNav), a modular approach that utilizes multimodal Chain-of-Thought to plan collaborative semantic navigation for multiple robots. MCoCoNav combines visual perception with Vision Language Models (VLMs) to evaluate exploration value through probabilistic scoring, thus reducing time costs and achieving stable outputs. Additionally, a global semantic map is used as a communication bridge, minimizing communication overhead while integrating observational results. Guided by scores that reflect exploration trends, robots utilize this map to assess whether to explore new frontier points or revisit history nodes. Experiments on HM3D_v0.2 and MP3D demonstrate the effectiveness of our approach. Our code is available at https://github.com/FrankZxShen/MCoCoNav.git.
GatedUniPose: A Novel Approach for Pose Estimation Combining UniRepLKNet and Gated Convolution
Sep 12, 2024

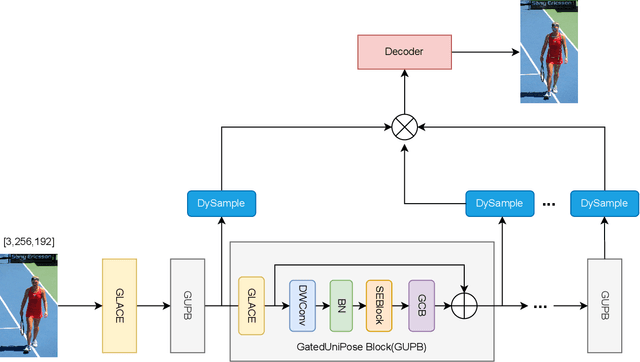
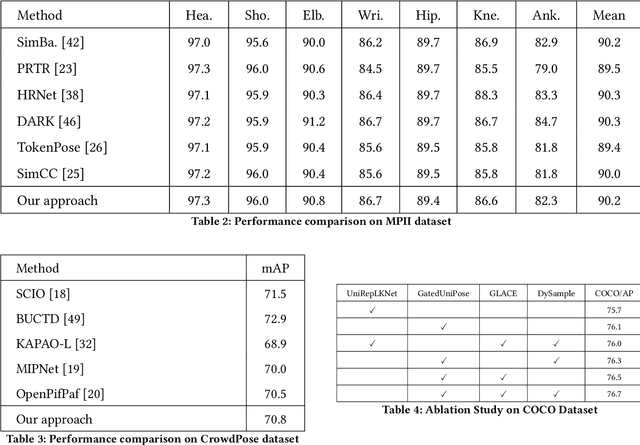
Pose estimation is a crucial task in computer vision, with wide applications in autonomous driving, human motion capture, and virtual reality. However, existing methods still face challenges in achieving high accuracy, particularly in complex scenes. This paper proposes a novel pose estimation method, GatedUniPose, which combines UniRepLKNet and Gated Convolution and introduces the GLACE module for embedding. Additionally, we enhance the feature map concatenation method in the head layer by using DySample upsampling. Compared to existing methods, GatedUniPose excels in handling complex scenes and occlusion challenges. Experimental results on the COCO, MPII, and CrowdPose datasets demonstrate that GatedUniPose achieves significant performance improvements with a relatively small number of parameters, yielding better or comparable results to models with similar or larger parameter sizes.
GateAttentionPose: Enhancing Pose Estimation with Agent Attention and Improved Gated Convolutions
Sep 12, 2024



This paper introduces GateAttentionPose, an innovative approach that enhances the UniRepLKNet architecture for pose estimation tasks. We present two key contributions: the Agent Attention module and the Gate-Enhanced Feedforward Block (GEFB). The Agent Attention module replaces large kernel convolutions, significantly improving computational efficiency while preserving global context modeling. The GEFB augments feature extraction and processing capabilities, particularly in complex scenes. Extensive evaluations on COCO and MPII datasets demonstrate that GateAttentionPose outperforms existing state-of-the-art methods, including the original UniRepLKNet, achieving superior or comparable results with improved efficiency. Our approach offers a robust solution for pose estimation across diverse applications, including autonomous driving, human motion capture, and virtual reality.
Adversarial Training with OCR Modality Perturbation for Scene-Text Visual Question Answering
Mar 14, 2024Scene-Text Visual Question Answering (ST-VQA) aims to understand scene text in images and answer questions related to the text content. Most existing methods heavily rely on the accuracy of Optical Character Recognition (OCR) systems, and aggressive fine-tuning based on limited spatial location information and erroneous OCR text information often leads to inevitable overfitting. In this paper, we propose a multimodal adversarial training architecture with spatial awareness capabilities. Specifically, we introduce an Adversarial OCR Enhancement (AOE) module, which leverages adversarial training in the embedding space of OCR modality to enhance fault-tolerant representation of OCR texts, thereby reducing noise caused by OCR errors. Simultaneously, We add a Spatial-Aware Self-Attention (SASA) mechanism to help the model better capture the spatial relationships among OCR tokens. Various experiments demonstrate that our method achieves significant performance improvements on both the ST-VQA and TextVQA datasets and provides a novel paradigm for multimodal adversarial training.