 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICACL: Multi-Instance Category-Aware Contrastive Learning for Long-Tailed Dynamic Facial Expression Recognition
Sep 04, 2025



Dynamic facial expression recognition (DFER) faces significant challenges due to long-tailed category distributions and complexity of spatio-temporal feature modeling. While existing deep learning-based methods have improved DFER performance, they often fail to address these issues, resulting in severe model induction bias. To overcome these limitations, we propose a novel multi-instance learning framework called MICACL, which integrates spatio-temporal dependency modeling and long-tailed contrastive learning optimization. Specifically, we design the Graph-Enhanced Instance Interaction Module (GEIIM) to capture intricate spatio-temporal between adjacent instances relationships through adaptive adjacency matrices and multiscale convolutions. To enhance instance-level feature aggregation, we develop the Weighted Instance Aggregation Network (WIAN), which dynamically assigns weights based on instance importance. Furthermore, we introduce a Multiscale Category-aware Contrastive Learning (MCCL) strategy to balance training between major and minor categories. Extensive experiments on in-the-wild datasets (i.e., DFEW and FERV39k) demonstrate that MICACL achieves state-of-the-art performance with superior robustness and generalization.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025



Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
NextBestPath: Efficient 3D Mapping of Unseen Environments
Feb 07, 2025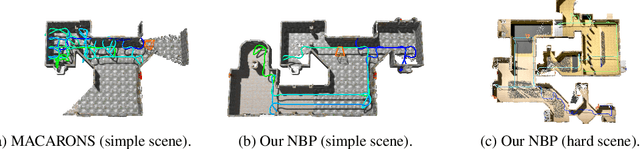


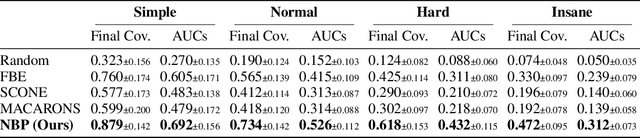
This work addresses the problem of active 3D mapping, where an agent must find an efficient trajectory to exhaustively reconstruct a new scene. Previous approaches mainly predict the next best view near the agent's location, which is prone to getting stuck in local areas. Additionally, existing indoor datasets are insufficient due to limited geometric complexity and inaccurate ground truth meshes. To overcome these limitations, we introduce a novel dataset AiMDoom with a map generator for the Doom video game, enabling to better benchmark active 3D mapping in diverse indoor environments. Moreover, we propose a new method we call next-best-path (NBP), which predicts long-term goals rather than focusing solely on short-sighted views. The model jointly predicts accumulated surface coverage gains for long-term goals and obstacle maps, allowing it to efficiently plan optimal paths with a unified model. By leveraging online data collection, data augmentation and curriculum learning, NBP significantly outperforms state-of-the-art methods on both the existing MP3D dataset and our AiMDoom dataset, achieving more efficient mapping in indoor environments of varying complexity.
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
CSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios
Sep 16, 2024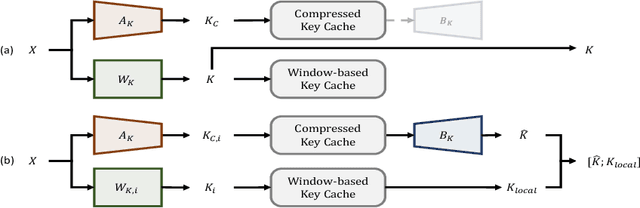
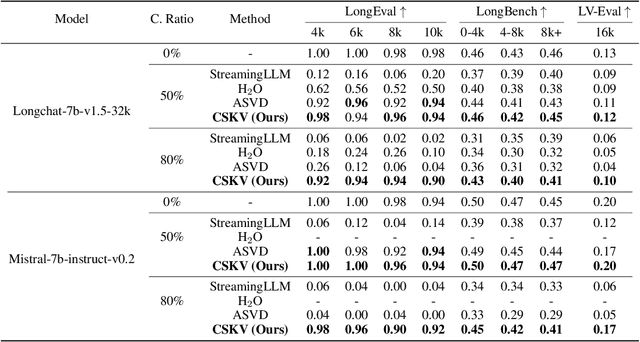
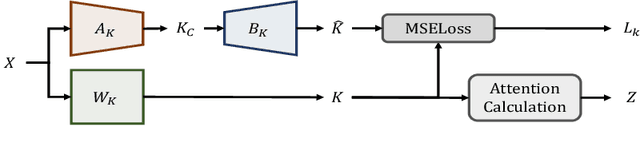
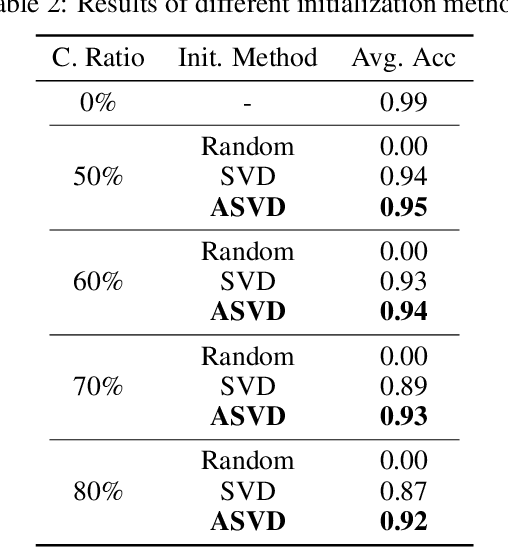
Large Language Models (LLMs) have been widely adopted to process long-context tasks. However, the large memory overhead of the key-value (KV) cache poses significant challenges in long-context scenarios. Existing training-free KV cache compression methods typically focus on quantization and token pruning, which have compression limits, and excessive sparsity can lead to severe performance degradation. Other methods design new architectures with less KV overhead but require significant training overhead. To address the above two drawbacks, we further explore the redundancy in the channel dimension and apply an architecture-level design with minor training costs. Therefore, we introduce CSKV, a training-efficient Channel Shrinking technique for KV cache compression: (1) We first analyze the singular value distribution of the KV cache, revealing significant redundancy and compression potential along the channel dimension. Based on this observation, we propose using low-rank decomposition for key and value layers and storing the low-dimension features. (2) To preserve model performance, we introduce a bi-branch KV cache, including a window-based full-precision KV cache and a low-precision compressed KV cache. (3) To reduce the training costs, we minimize the layer-wise reconstruction loss for the compressed KV cache instead of retraining the entire LLMs. Extensive experiments show that CSKV can reduce the memory overhead of the KV cache by 80% while maintaining the model's long-context capability. Moreover, we show that our method can be seamlessly combined with quantization to further reduce the memory overhead, achieving a compression ratio of up to 95%.
GateAttentionPose: Enhancing Pose Estimation with Agent Attention and Improved Gated Convolutions
Sep 12, 2024



This paper introduces GateAttentionPose, an innovative approach that enhances the UniRepLKNet architecture for pose estimation tasks. We present two key contributions: the Agent Attention module and the Gate-Enhanced Feedforward Block (GEFB). The Agent Attention module replaces large kernel convolutions, significantly improving computational efficiency while preserving global context modeling. The GEFB augments feature extraction and processing capabilities, particularly in complex scenes. Extensive evaluations on COCO and MPII datasets demonstrate that GateAttentionPose outperforms existing state-of-the-art methods, including the original UniRepLKNet, achieving superior or comparable results with improved efficiency. Our approach offers a robust solution for pose estimation across diverse applications, including autonomous driving, human motion capture, and virtual reality.
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression
Jun 21, 2024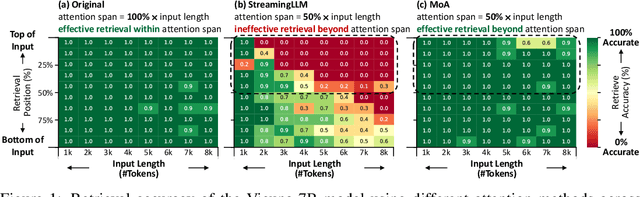
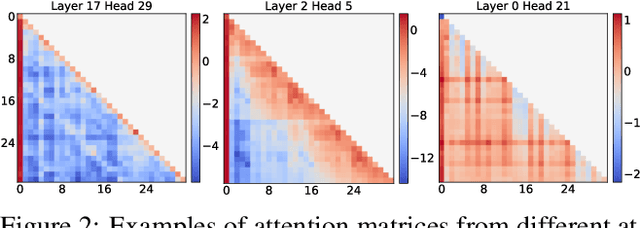

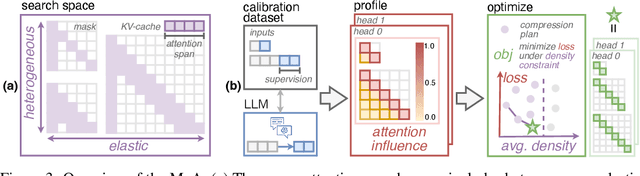
Sparse attention can effectively mitigate the significant memory and throughput demands of Large Language Models (LLMs) in long contexts. Existing methods typically employ a uniform sparse attention mask, applying the same sparse pattern across different attention heads and input lengths. However, this uniform approach fails to capture the diverse attention patterns inherent in LLMs, ignoring their distinct accuracy-latency trade-offs. To address this challenge, we propose the Mixture of Attention (MoA), which automatically tailors distinct sparse attention configurations to different heads and layers. MoA constructs and navigates a search space of various attention patterns and their scaling rules relative to input sequence lengths. It profiles the model, evaluates potential configurations, and pinpoints the optimal sparse attention compression plan. MoA adapts to varying input sizes, revealing that some attention heads expand their focus to accommodate longer sequences, while other heads consistently concentrate on fixed-length local contexts. Experiments show that MoA increases the effective context length by $3.9\times$ with the same average attention span, boosting retrieval accuracy by $1.5-7.1\times$ over the uniform-attention baseline across Vicuna-7B, Vicuna-13B, and Llama3-8B models. Moreover, MoA narrows the capability gaps between sparse and dense models, reducing the maximum relative performance drop from $9\%-36\%$ to within $5\%$ across two long-context understanding benchmarks. MoA achieves a $1.2-1.4\times$ GPU memory reduction and boosts decode throughput by $5.5-6.7 \times$ for 7B and 13B dense models on a single GPU, with minimal impact on performance.
Can LLMs Learn by Teaching? A Preliminary Study
Jun 20, 2024



Teaching to improve student models (e.g., knowledge distillation) is an extensively studied methodology in LLMs. However, for humans, teaching not only improves students but also improves teachers. We ask: Can LLMs also learn by teaching (LbT)? If yes, we can potentially unlock the possibility of continuously advancing the models without solely relying on human-produced data or stronger models. In this paper, we provide a preliminary exploration of this ambitious agenda. We show that LbT ideas can be incorporated into existing LLM training/prompting pipelines and provide noticeable improvements. Specifically, we design three methods, each mimicking one of the three levels of LbT in humans: observing students' feedback, learning from the feedback, and learning iteratively, with the goals of improving answer accuracy without training and improving models' inherent capability with fine-tuning. The findings are encouraging. For example, similar to LbT in human, we see that: (1) LbT can induce weak-to-strong generalization: strong models can improve themselves by teaching other weak models; (2) Diversity in students might help: teaching multiple students could be better than teaching one student or the teacher itself. We hope that this early promise can inspire future research on LbT and more broadly adopting the advanced techniques in education to improve LLMs. The code is available at https://github.com/imagination-research/lbt.
ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Jun 04, 2024



Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: "ViDiT-Q": Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.