 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCache: Training-free Acceleration of Diffusion Models via Hermite Polynomial-based Feature Caching
Aug 23, 2025Diffusion models have achieved remarkable success in content generation but suffer from prohibitive computational costs due to iterative sampling. While recent feature caching methods tend to accelerate inference through temporal extrapolation, these methods still suffer from server quality loss due to the failure in modeling the complex dynamics of feature evolution. To solve this problem, this paper presents HiCache, a training-free acceleration framework that fundamentally improves feature prediction by aligning mathematical tools with empirical properties. Our key insight is that feature derivative approximations in Diffusion Transformers exhibit multivariate Gaussian characteristics, motivating the use of Hermite polynomials-the potentially theoretically optimal basis for Gaussian-correlated processes. Besides, We further introduce a dual-scaling mechanism that ensures numerical stability while preserving predictive accuracy. Extensive experiments demonstrate HiCache's superiority: achieving 6.24x speedup on FLUX.1-dev while exceeding baseline quality, maintaining strong performance across text-to-image, video generation, and super-resolution tasks. Core implementation is provided in the appendix, with complete code to be released upon acceptance.
Detection of Disease on Nasal Breath Sound by New Lightweight Architecture: Using COVID-19 as An Example
Apr 01, 2025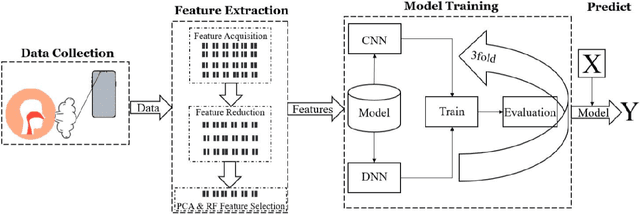



Background. Infectious diseases, particularly COVID-19, continue to be a significant global health issue. Although many countries have reduced or stopped large-scale testing measures, the detection of such diseases remains a propriety. Objective. This study aims to develop a novel, lightweight deep neural network for efficient, accurate, and cost-effective detection of COVID-19 using a nasal breathing audio data collected via smartphones. Methodology. Nasal breathing audio from 128 patients diagnosed with the Omicron variant was collected. Mel-Frequency Cepstral Coefficients (MFCCs), a widely used feature in speech and sound analysis, were employed for extracting important characteristics from the audio signals. Additional feature selection was performed using Random Forest (RF) and Principal Component Analysis (PCA) for dimensionality reduction. A Dense-ReLU-Dropout model was trained with K-fold cross-validation (K=3), and performance metrics like accuracy, precision, recall, and F1-score were used to evaluate the model. Results. The proposed model achieved 97% accuracy in detecting COVID-19 from nasal breathing sounds, outperforming state-of-the-art methods such as those by [23] and [13]. Our Dense-ReLU-Dropout model, using RF and PCA for feature selection, achieves high accuracy with greater computational efficiency compared to existing methods that require more complex models or larger datasets. Conclusion. The findings suggest that the proposed method holds significant potential for clinical implementation, advancing smartphone-based diagnostics in infectious diseases. The Dense-ReLU-Dropout model, combined with innovative feature processing techniques, offers a promising approach for efficient and accurate COVID-19 detection, showcasing the capabilities of mobile device-based diagnostics
A Theoretical Analysis of Analogy-Based Evolutionary Transfer Optimization
Mar 27, 2025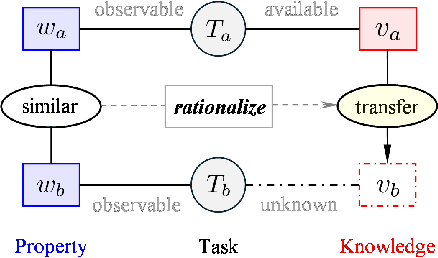

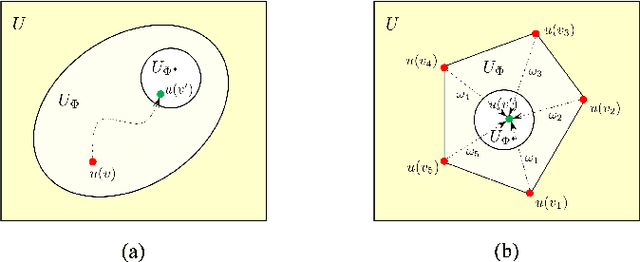
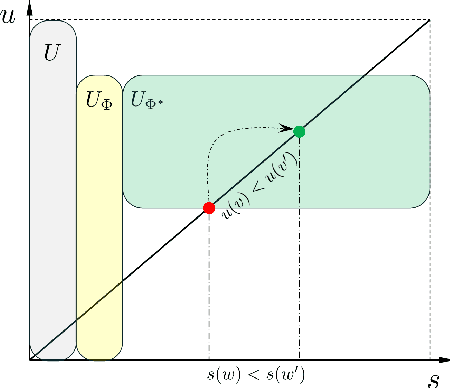
Evolutionary transfer optimization (ETO) has been gaining popularity in research over the years due to its outstanding knowledge transfer ability to address various challenges in optimization. However, a pressing issue in this field is that the invention of new ETO algorithms has far outpaced the development of fundamental theories needed to clearly understand the key factors contributing to the success of these algorithms for effective generalization. In response to this challenge, this study aims to establish theoretical foundations for analogy-based ETO, specifically to support various algorithms that frequently reference a key concept known as similarity. First, we introduce analogical reasoning and link its subprocesses to three key issues in ETO. Then, we develop theories for analogy-based knowledge transfer, rooted in the principles that underlie the subprocesses. Afterwards, we present two theorems related to the performance gain of analogy-based knowledge transfer, namely unconditionally nonnegative performance gain and conditionally positive performance gain, to theoretically demonstrate the effectiveness of various analogy-based ETO methods. Last but not least, we offer a novel insight into analogy-based ETO that interprets its conditional superiority over traditional evolutionary optimization through the lens of the no free lunch theorem for optimization.
Towards Fault Tolerance in Multi-Agent Reinforcement Learning
Nov 30, 2024



Agent faults pose a significant threat to the performance of multi-agent reinforcement learning (MARL) algorithms, introducing two key challenges. First, agents often struggle to extract critical information from the chaotic state space created by unexpected faults. Second, transitions recorded before and after faults in the replay buffer affect training unevenly, leading to a sample imbalance problem. To overcome these challenges, this paper enhances the fault tolerance of MARL by combining optimized model architecture with a tailored training data sampling strategy. Specifically, an attention mechanism is incorporated into the actor and critic networks to automatically detect faults and dynamically regulate the attention given to faulty agents. Additionally, a prioritization mechanism is introduced to selectively sample transitions critical to current training needs. To further support research in this area, we design and open-source a highly decoupled code platform for fault-tolerant MARL, aimed at improving the efficiency of studying related problems. Experimental results demonstrate the effectiveness of our method in handling various types of faults, faults occurring in any agent, and faults arising at random times.
HM3: Hierarchical Multi-Objective Model Merging for Pretrained Models
Sep 27, 2024



Model merging is a technique that combines multiple large pretrained models into a single model with enhanced performance and broader task adaptability. It has gained popularity in large pretrained model development due to its ability to bypass the need for original training data and further training processes. However, most existing model merging approaches focus solely on exploring the parameter space, merging models with identical architectures. Merging within the architecture space, despite its potential, remains in its early stages due to the vast search space and the challenges of layer compatibility. This paper marks a significant advance toward more flexible and comprehensive model merging techniques by modeling the architecture-space merging process as a reinforcement learning task. We train policy and value networks using offline sampling of weight vectors, which are then employed for the online optimization of merging strategies. Moreover, a multi-objective optimization paradigm is introduced to accommodate users' diverse task preferences, learning the Pareto front of optimal models to offer customized merging suggestions. Experimental results across multiple tasks, including text translation, mathematical reasoning, and code generation, validate the effectiveness and superiority of the proposed framework in model merging. The code will be made publicly available after the review process.
GatedUniPose: A Novel Approach for Pose Estimation Combining UniRepLKNet and Gated Convolution
Sep 12, 2024

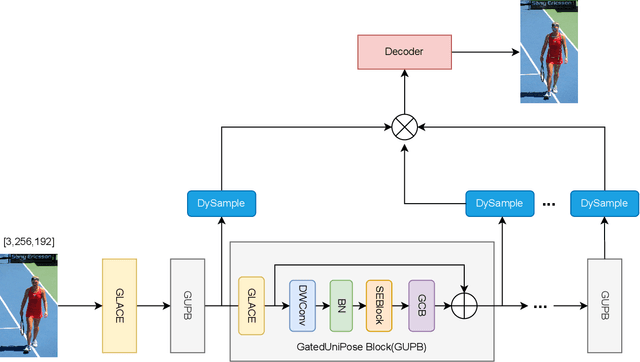
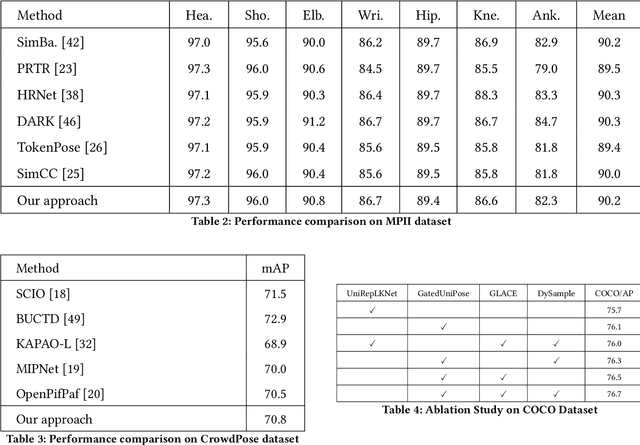
Pose estimation is a crucial task in computer vision, with wide applications in autonomous driving, human motion capture, and virtual reality. However, existing methods still face challenges in achieving high accuracy, particularly in complex scenes. This paper proposes a novel pose estimation method, GatedUniPose, which combines UniRepLKNet and Gated Convolution and introduces the GLACE module for embedding. Additionally, we enhance the feature map concatenation method in the head layer by using DySample upsampling. Compared to existing methods, GatedUniPose excels in handling complex scenes and occlusion challenges. Experimental results on the COCO, MPII, and CrowdPose datasets demonstrate that GatedUniPose achieves significant performance improvements with a relatively small number of parameters, yielding better or comparable results to models with similar or larger parameter sizes.
GateAttentionPose: Enhancing Pose Estimation with Agent Attention and Improved Gated Convolutions
Sep 12, 2024



This paper introduces GateAttentionPose, an innovative approach that enhances the UniRepLKNet architecture for pose estimation tasks. We present two key contributions: the Agent Attention module and the Gate-Enhanced Feedforward Block (GEFB). The Agent Attention module replaces large kernel convolutions, significantly improving computational efficiency while preserving global context modeling. The GEFB augments feature extraction and processing capabilities, particularly in complex scenes. Extensive evaluations on COCO and MPII datasets demonstrate that GateAttentionPose outperforms existing state-of-the-art methods, including the original UniRepLKNet, achieving superior or comparable results with improved efficiency. Our approach offers a robust solution for pose estimation across diverse applications, including autonomous driving, human motion capture, and virtual reality.
Advancing Automated Knowledge Transfer in Evolutionary Multitasking via Large Language Models
Sep 06, 2024



Evolutionary Multi-task Optimization (EMTO) is a paradigm that leverages knowledge transfer across simultaneously optimized tasks for enhanced search performance. To facilitate EMTO's performance, various knowledge transfer models have been developed for specific optimization tasks. However, designing these models often requires substantial expert knowledge. Recently, large language models (LLMs) have achieved remarkable success in autonomous programming, aiming to produce effective solvers for specific problems. In this work, a LLM-based optimization paradigm is introduced to establish an autonomous model factory for generating knowledge transfer models, ensuring effective and efficient knowledge transfer across various optimization tasks. To evaluate the performance of the proposed method, we conducted comprehensive empirical studies comparing the knowledge transfer model generated by the LLM with existing state-of-the-art knowledge transfer methods. The results demonstrate that the generated model is able to achieve superior or competitive performance against hand-crafted knowledge transfer models in terms of both efficiency and effectiveness.
Design Principle Transfer in Neural Architecture Search via Large Language Models
Aug 21, 2024



Transferable neural architecture search (TNAS) has been introduced to design efficient neural architectures for multiple tasks, to enhance the practical applicability of NAS in real-world scenarios. In TNAS, architectural knowledge accumulated in previous search processes is reused to warm up the architecture search for new tasks. However, existing TNAS methods still search in an extensive search space, necessitating the evaluation of numerous architectures. To overcome this challenge, this work proposes a novel transfer paradigm, i.e., design principle transfer. In this work, the linguistic description of various structural components' effects on architectural performance is termed design principles. They are learned from established architectures and then can be reused to reduce the search space by discarding unpromising architectures. Searching in the refined search space can boost both the search performance and efficiency for new NAS tasks. To this end, a large language model (LLM)-assisted design principle transfer (LAPT) framework is devised. In LAPT, LLM is applied to automatically reason the design principles from a set of given architectures, and then a principle adaptation method is applied to refine these principles progressively based on the new search results. Experimental results show that LAPT can beat the state-of-the-art TNAS methods on most tasks and achieve comparable performance on others.
Surrogate-Assisted Search with Competitive Knowledge Transfer for Expensive Optimization
Aug 13, 2024
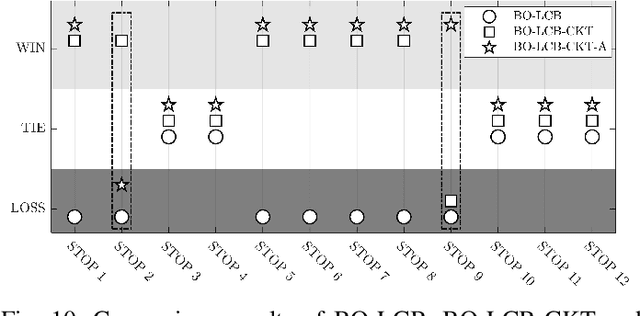

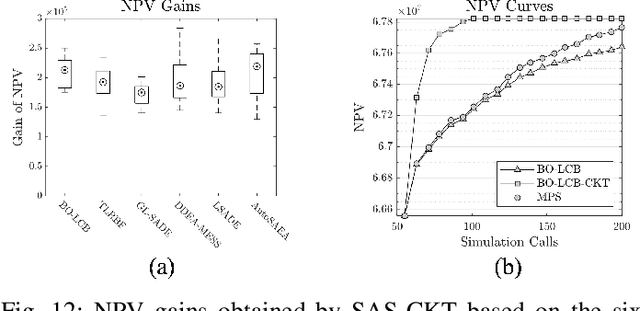
Expensive optimization problems (EOPs) have attracted increasing research attention over the decades due to their ubiquity in a variety of practical applications. Despite many sophisticated surrogate-assisted evolutionary algorithms (SAEAs) that have been developed for solving such problems, most of them lack the ability to transfer knowledge from previously-solved tasks and always start their search from scratch, making them troubled by the notorious cold-start issue. A few preliminary studies that integrate transfer learning into SAEAs still face some issues, such as defective similarity quantification that is prone to underestimate promising knowledge, surrogate-dependency that makes the transfer methods not coherent with the state-of-the-art in SAEAs, etc. In light of the above, a plug and play competitive knowledge transfer method is proposed to boost various SAEAs in this paper. Specifically, both the optimized solutions from the source tasks and the promising solutions acquired by the target surrogate are treated as task-solving knowledge, enabling them to compete with each other to elect the winner for expensive evaluation, thus boosting the search speed on the target task. Moreover, the lower bound of the convergence gain brought by the knowledge competition is mathematically analyzed, which is expected to strengthen the theoretical foundation of sequential transfer optimization. Experimental studies conducted on a series of benchmark problems and a practical application from the petroleum industry verify the efficacy of the proposed method. The source code of the competitive knowledge transfer is available at https://github.com/XmingHsueh/SAS-CKT.