 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
Aug 07, 2025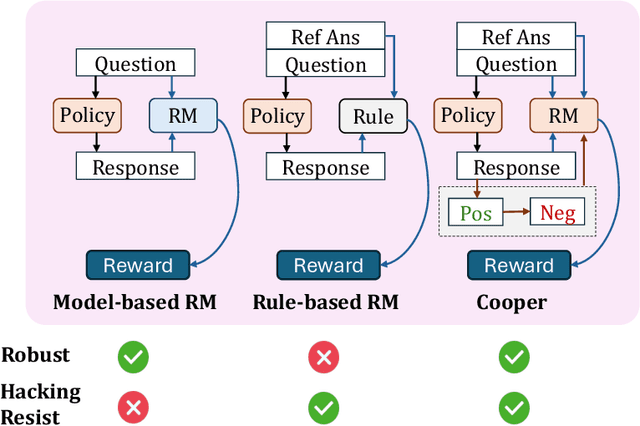



Large language models (LLMs) have demonstrated remarkable performance in reasoning tasks, where reinforcement learning (RL) serves as a key algorithm for enhancing their reasoning capabilities. Currently, there are two mainstream reward paradigms: model-based rewards and rule-based rewards. However, both approaches suffer from limitations: rule-based rewards lack robustness, while model-based rewards are vulnerable to reward hacking. To address these issues, we propose Cooper(Co-optimizing Policy Model and Reward Model), a RL framework that jointly optimizes both the policy model and the reward model. Cooper leverages the high precision of rule-based rewards when identifying correct responses, and dynamically constructs and selects positive-negative sample pairs for continued training the reward model. This design enhances robustness and mitigates the risk of reward hacking. To further support Cooper, we introduce a hybrid annotation strategy that efficiently and accurately generates training data for the reward model. We also propose a reference-based reward modeling paradigm, where the reward model takes a reference answer as input. Based on this design, we train a reward model named VerifyRM, which achieves higher accuracy on VerifyBench compared to other models of the same size. We conduct reinforcement learning using both VerifyRM and Cooper. Our experiments show that Cooper not only alleviates reward hacking but also improves end-to-end RL performance, for instance, achieving a 0.54% gain in average accuracy on Qwen2.5-1.5B-Instruct. Our findings demonstrate that dynamically updating reward model is an effective way to combat reward hacking, providing a reference for better integrating reward models into RL.
When Large Language Models Meet Law: Dual-Lens Taxonomy, Technical Advances, and Ethical Governance
Jul 10, 2025This paper establishes the first comprehensive review of Large Language Models (LLMs) applied within the legal domain. It pioneers an innovative dual lens taxonomy that integrates legal reasoning frameworks and professional ontologies to systematically unify historical research and contemporary breakthroughs. Transformer-based LLMs, which exhibit emergent capabilities such as contextual reasoning and generative argumentation, surmount traditional limitations by dynamically capturing legal semantics and unifying evidence reasoning. Significant progress is documented in task generalization, reasoning formalization, workflow integration, and addressing core challenges in text processing, knowledge integration, and evaluation rigor via technical innovations like sparse attention mechanisms and mixture-of-experts architectures. However, widespread adoption of LLM introduces critical challenges: hallucination, explainability deficits, jurisdictional adaptation difficulties, and ethical asymmetry. This review proposes a novel taxonomy that maps legal roles to NLP subtasks and computationally implements the Toulmin argumentation framework, thus systematizing advances in reasoning, retrieval, prediction, and dispute resolution. It identifies key frontiers including low-resource systems, multimodal evidence integration, and dynamic rebuttal handling. Ultimately, this work provides both a technical roadmap for researchers and a conceptual framework for practitioners navigating the algorithmic future, laying a robust foundation for the next era of legal artificial intelligence. We have created a GitHub repository to index the relevant papers: https://github.com/Kilimajaro/LLMs_Meet_Law.
Diversity-Aware Policy Optimization for Large Language Model Reasoning
May 29, 2025The reasoning capabilities of large language models (LLMs) have advanced rapidly, particularly following the release of DeepSeek R1, which has inspired a surge of research into data quality and reinforcement learning (RL) algorithms. Despite the pivotal role diversity plays in RL, its influence on LLM reasoning remains largely underexplored. To bridge this gap, this work presents a systematic investigation into the impact of diversity in RL-based training for LLM reasoning, and proposes a novel diversity-aware policy optimization method. Across evaluations on 12 LLMs, we observe a strong positive correlation between the solution diversity and Potential at k (a novel metric quantifying an LLM's reasoning potential) in high-performing models. This finding motivates our method to explicitly promote diversity during RL training. Specifically, we design a token-level diversity and reformulate it into a practical objective, then we selectively apply it to positive samples. Integrated into the R1-zero training framework, our method achieves a 3.5 percent average improvement across four mathematical reasoning benchmarks, while generating more diverse and robust solutions.
Semi-Supervised Multi-Label Feature Selection with Consistent Sparse Graph Learning
May 23, 2025In practical domains, high-dimensional data are usually associated with diverse semantic labels, whereas traditional feature selection methods are designed for single-label data. Moreover, existing multi-label methods encounter two main challenges in semi-supervised scenarios: (1). Most semi-supervised methods fail to evaluate the label correlations without enough labeled samples, which are the critical information of multi-label feature selection, making label-specific features discarded. (2). The similarity graph structure directly derived from the original feature space is suboptimal for multi-label problems in existing graph-based methods, leading to unreliable soft labels and degraded feature selection performance. To overcome them, we propose a consistent sparse graph learning method for multi-label semi-supervised feature selection (SGMFS), which can enhance the feature selection performance by maintaining space consistency and learning label correlations in semi-supervised scenarios. Specifically, for Challenge (1), SGMFS learns a low-dimensional and independent label subspace from the projected features, which can compatibly cross multiple labels and effectively achieve the label correlations. For Challenge (2), instead of constructing a fixed similarity graph for semi-supervised learning, SGMFS thoroughly explores the intrinsic structure of the data by performing sparse reconstruction of samples in both the label space and the learned subspace simultaneously. In this way, the similarity graph can be adaptively learned to maintain the consistency between label space and the learned subspace, which can promote propagating proper soft labels for unlabeled samples, facilitating the ultimate feature selection. An effective solution with fast convergence is designed to optimize the objective function. Extensive experiments validate the superiority of SGMFS.
Hybrid Local Causal Discovery
Dec 27, 2024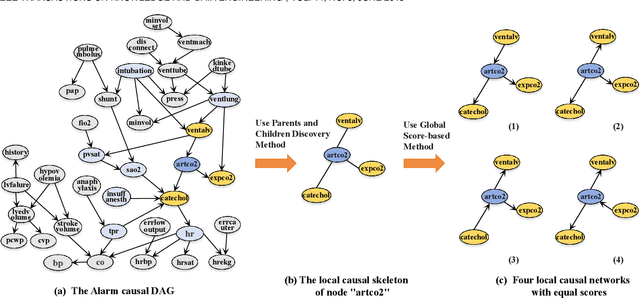
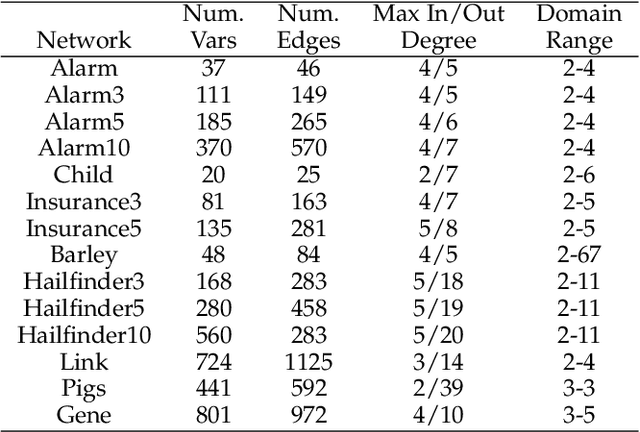
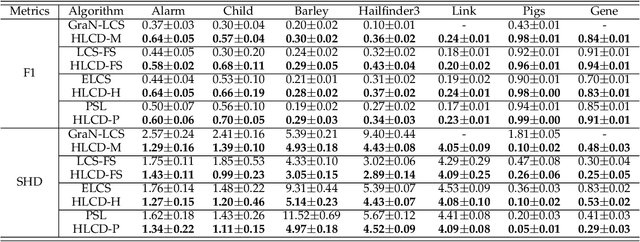
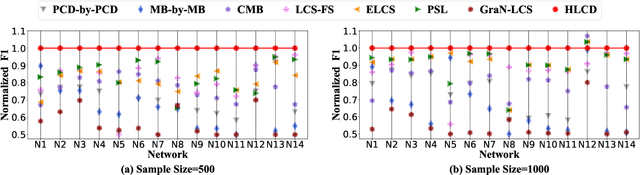
Local causal discovery aims to learn and distinguish the direct causes and effects of a target variable from observed data. Existing constraint-based local causal discovery methods use AND or OR rules in constructing the local causal skeleton, but using either rule alone is prone to produce cascading errors in the learned local causal skeleton, and thus impacting the inference of local causal relationships. On the other hand, directly applying score-based global causal discovery methods to local causal discovery may randomly return incorrect results due to the existence of local equivalence classes. To address the above issues, we propose a Hybrid Local Causal Discovery algorithm, called HLCD. Specifically, HLCD initially utilizes a constraint-based approach combined with the OR rule to obtain a candidate skeleton and then employs a score-based method to eliminate redundant portions in the candidate skeleton. Furthermore, during the local causal orientation phase, HLCD distinguishes between V-structures and equivalence classes by comparing the local structure scores between the two, thereby avoiding orientation interference caused by local equivalence classes. We conducted extensive experiments with seven state-of-the-art competitors on 14 benchmark Bayesian network datasets, and the experimental results demonstrate that HLCD significantly outperforms existing local causal discovery algorithms.
HM3: Hierarchical Multi-Objective Model Merging for Pretrained Models
Sep 27, 2024



Model merging is a technique that combines multiple large pretrained models into a single model with enhanced performance and broader task adaptability. It has gained popularity in large pretrained model development due to its ability to bypass the need for original training data and further training processes. However, most existing model merging approaches focus solely on exploring the parameter space, merging models with identical architectures. Merging within the architecture space, despite its potential, remains in its early stages due to the vast search space and the challenges of layer compatibility. This paper marks a significant advance toward more flexible and comprehensive model merging techniques by modeling the architecture-space merging process as a reinforcement learning task. We train policy and value networks using offline sampling of weight vectors, which are then employed for the online optimization of merging strategies. Moreover, a multi-objective optimization paradigm is introduced to accommodate users' diverse task preferences, learning the Pareto front of optimal models to offer customized merging suggestions. Experimental results across multiple tasks, including text translation, mathematical reasoning, and code generation, validate the effectiveness and superiority of the proposed framework in model merging. The code will be made publicly available after the review process.
Design Principle Transfer in Neural Architecture Search via Large Language Models
Aug 21, 2024



Transferable neural architecture search (TNAS) has been introduced to design efficient neural architectures for multiple tasks, to enhance the practical applicability of NAS in real-world scenarios. In TNAS, architectural knowledge accumulated in previous search processes is reused to warm up the architecture search for new tasks. However, existing TNAS methods still search in an extensive search space, necessitating the evaluation of numerous architectures. To overcome this challenge, this work proposes a novel transfer paradigm, i.e., design principle transfer. In this work, the linguistic description of various structural components' effects on architectural performance is termed design principles. They are learned from established architectures and then can be reused to reduce the search space by discarding unpromising architectures. Searching in the refined search space can boost both the search performance and efficiency for new NAS tasks. To this end, a large language model (LLM)-assisted design principle transfer (LAPT) framework is devised. In LAPT, LLM is applied to automatically reason the design principles from a set of given architectures, and then a principle adaptation method is applied to refine these principles progressively based on the new search results. Experimental results show that LAPT can beat the state-of-the-art TNAS methods on most tasks and achieve comparable performance on others.
Fair Streaming Feature Selection
Jun 20, 2024



Streaming feature selection techniques have become essential in processing real-time data streams, as they facilitate the identification of the most relevant attributes from continuously updating information. Despite their performance, current algorithms to streaming feature selection frequently fall short in managing biases and avoiding discrimination that could be perpetuated by sensitive attributes, potentially leading to unfair outcomes in the resulting models. To address this issue, we propose FairSFS, a novel algorithm for Fair Streaming Feature Selection, to uphold fairness in the feature selection process without compromising the ability to handle data in an online manner. FairSFS adapts to incoming feature vectors by dynamically adjusting the feature set and discerns the correlations between classification attributes and sensitive attributes from this revised set, thereby forestalling the propagation of sensitive data. Empirical evaluations show that FairSFS not only maintains accuracy that is on par with leading streaming feature selection methods and existing fair feature techniques but also significantly improves fairness metrics.
Learning to Transfer for Evolutionary Multitasking
Jun 20, 2024



Evolutionary multitasking (EMT) is an emerging approach for solving multitask optimization problems (MTOPs) and has garnered considerable research interest. The implicit EMT is a significant research branch that utilizes evolution operators to enable knowledge transfer (KT) between tasks. However, current approaches in implicit EMT face challenges in adaptability, due to the use of a limited number of evolution operators and insufficient utilization of evolutionary states for performing KT. This results in suboptimal exploitation of implicit KT's potential to tackle a variety of MTOPs. To overcome these limitations, we propose a novel Learning to Transfer (L2T) framework to automatically discover efficient KT policies for the MTOPs at hand. Our framework conceptualizes the KT process as a learning agent's sequence of strategic decisions within the EMT process. We propose an action formulation for deciding when and how to transfer, a state representation with informative features of evolution states, a reward formulation concerning convergence and transfer efficiency gain, and the environment for the agent to interact with MTOPs. We employ an actor-critic network structure for the agent and learn it via proximal policy optimization. This learned agent can be integrated with various evolutionary algorithms, enhancing their ability to address a range of new MTOPs. Comprehensive empirical studies on both synthetic and real-world MTOPs, encompassing diverse inter-task relationships, function classes, and task distributions are conducted to validate the proposed L2T framework. The results show a marked improvement in the adaptability and performance of implicit EMT when solving a wide spectrum of unseen MTOPs.
Unlock the Power of Algorithm Features: A Generalization Analysis for Algorithm Selection
May 18, 2024



In the field of algorithm selection research, the discussion surrounding algorithm features has been significantly overshadowed by the emphasis on problem features. Although a few empirical studies have yielded evidence regarding the effectiveness of algorithm features, the potential benefits of incorporating algorithm features into algorithm selection models and their suitability for different scenarios remain unclear. It is evident that relying solely on empirical research cannot adequately elucidate the mechanisms underlying performance variations. In this paper, we address this gap by proposing the first provable guarantee for algorithm selection based on algorithm features, taking a generalization perspective. We analyze the benefits and costs associated with algorithm features and investigate how the generalization error is affected by several factors. Specifically, we examine adaptive and predefined algorithm features under transductive and inductive learning paradigms, respectively, and derive upper bounds for the generalization error based on their model's Rademacher complexity. Our theoretical findings not only provide tight upper bounds, but also offer analytical insights into the impact of various factors, including model complexity, the number of problem instances and candidate algorithms, model parameters and feature values, and distributional differences between the training and test sets. Notably, we demonstrate that algorithm feature-based models outperform traditional models relying solely on problem features in complex multi-algorithm scenarios in terms of generalization, and are particularly well-suited for deployment in scenarios under distribution shifts, where the generalization error exhibits a positive correlation with the chi-square distance between training and test sets.